

论文链接:
https://arxiv.org/abs/2207.02375
代码链接:
https://github.com/Ryan-prime/3DG-STFM
导读
在本文中,作者采取了3DG-STFM来解决在一对图像之间寻找密集视觉对应的问题。3DG-STFM使用一种多模态匹配模型(教师)以在3D密集对应监督下加强深度一致性,并将知识转移到2D单峰匹配模型(学生)。教师和学生模型都由两个基于变压器的匹配模块组成,这些模块以从粗到精的方式获得密集对应。教师模型引导学生模型学习RGB诱导○的深度信息,以便在粗分支和细分支上进行匹配。文中还评估了3DG-STFM的模型压缩任务。3DG-STFM是第一种用于局部特征匹配任务的学生-教师学习方法。实验表明,文中的方法在室内和室外摄像机姿态估计和单应性估计问题上的性能优于最先进的方法。
贡献
建立重叠图像之间的对应关系对于许多计算机视觉任务至关重要,比如运动推断结构(SfM)、视觉定位与建图(SLAM)、视觉定位等。而大多数解决该问题的现有方法遵循经典的三阶段流程,即特征检测、特征描述和特征匹配。为了提高效率,有些人使用Hloc将这些匹配技术用于视觉定位。有些则尝试避免检测步骤,并通过考虑来自规则网格的所有点来建立密集匹配。这些密集匹配方法旨在提供低纹理区域中的兴趣点,并为匹配目的提供足够的候选。

图 1.1 稠密局部特征匹配方法LoFTR与所提方法3DG-STFM的比较。该示例表明,3DG-STFM方法可以在具有重复模式和低纹理区域的具有挑战性的场景下找到正确的对应关系。红色表示极线误差超过5×10^(-4)(在标准化图像坐标中)。
现有的建立重叠图像对应关系的方法都没有在训练阶段探索深度模态分布,与RGB图像不同,深度图提供3D信息,以明确的方式描述几何分布。文中引入深度模态分布的方法可以提供双重好处。首先,深度信息可以消除2D图像空间中的许多模糊,并增强特征匹配的几何一致性,这在仅使用RGB输入时非常困难。当图像对中存在多个类似对象时,这尤其如此。在这种情况下,大多数现有方法倾向于寻找不可信的匹配候选,因为它们纯粹区分2D描述符,而没有深度或大小知识。图1.1的第一行中示出了一个示例,其中基线方法被类似的2D外观混淆,并且错误地将较近的椅子与另一个椅子匹配。第二,如图1的第二行中所示的示例,单个对象的低纹理区域在实施密集和一致匹配方面困扰2D描述符。通过利用深度模态的识别,也可以很好地调整该缺陷。
尽管有深度信息的优势,但高质量的RGB-D输入只能在控制良好的实验室环境中收集,并且很少,特别是低成本设备能够在真实场景中捕获类似的对齐良好的RGB-D对。大多数成像系统仅配备RGB传感器作为输入,并且不能承受由多模态推断引起的高计算成本。这使得在推理和训练期间RGB和深度输入的朴素多模式融合成为限制性解决方案。因此,在实际场景中,考虑到硬件和计算负载的约束,需要一种将昂贵的RGB-D知识转换为RGB模态推理的好方法。
基于这些观察,文中提出了3DG-STFM,一个学生-教师学习框架,将多模态教师模型学习的深度知识转移到单模态学生模型,以改进局部特征匹配。3DG-STFM是第一个在图像匹配问题上传递跨模态知识的学生-教师学习架构。该方法旨在找到RGB-D图像中的深度和RGB相关分布,并通过保持这种分布将知识传递给RGB学生分支。因此,在实际推理过程(学生分支)中不明确要求深度模态。
本文的主要贡献总结如下:
- 文中提出了第一个基于局部特征匹配问题的学生-教师学习架构,该架构学习从密集RGB-D通信监控中提取的诱导深度分布。
- 文中提出了专注的知识转移策略,以帮助学生模型理解培训过程中的匹配分布和学习优先级,而不是学习点对点匹配。
- 文中表明,所提出的模型在一系列匹配任务上产生高质量的密集对应,并在摄像机姿态和单应性估计任务上实现了最先进的结果
方法
3.1 师生学习
文中提出的系统,3DG-STFM,是利用训练有素的多模态模型(教师)的知识来训练单模态局部特征匹配模型(学生)。每个学生或教师分支都首先利用特征金字塔网络(FPN)来提取原始图像分辨率为 1/81/8 和 1/21/2 的粗级局部特征( \( F_c^A \) ,\( F_c^B \) )和细级特征(\( F_f^A \) ,\( F_f^B \) )。由 \( L_c \) 注意力层组成的粗略transformer查找可能匹配的特征对及其匹配分数。选择具有高置信度分数的匹配项,并将其映射到精细级别的特征地图。\( F_f^A \) ,\( F_f^B \) 上的周围特征由 w×w 大小的窗口收集,并馈送到具有 \( L_f \) 注意力层的精细级别transformer。精细级别匹配模块用于预测亚像素级别上的对应(\( \hat i \),\( \hat j \) )。教师模式首先在直接监督下培养。在学生模型培训期间,它将被冻结,并通过注意损失和相互查询偏离(MQD)损失,提供额外的监督。
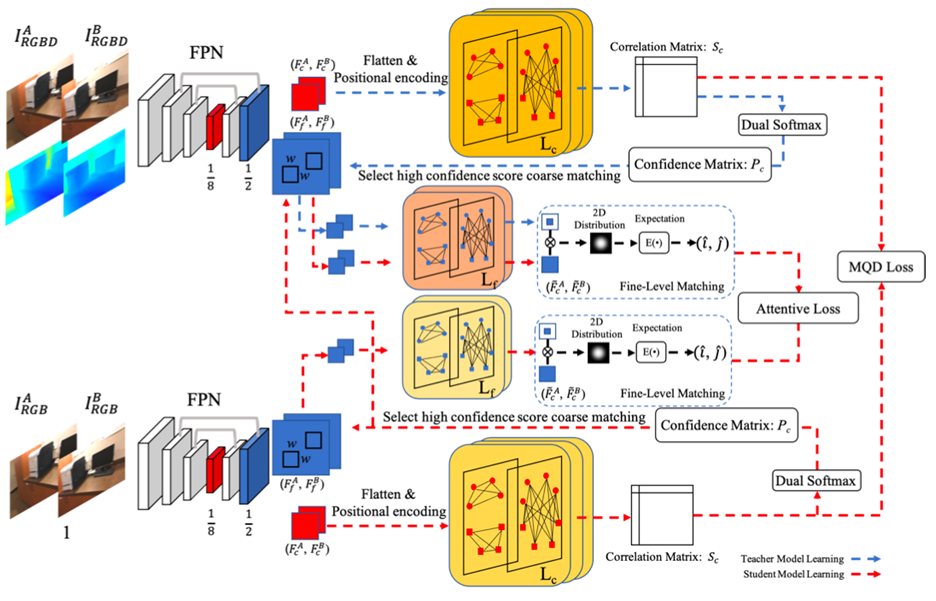
图3.1.1 3GD-STFM概览
3.2 粗略差分匹配机制
综合transformer的输出可以得到联合矩阵 \( S_c \) ,在两个维度上应用双重softmax来得到配对概率。原理如图3.2.1所示。
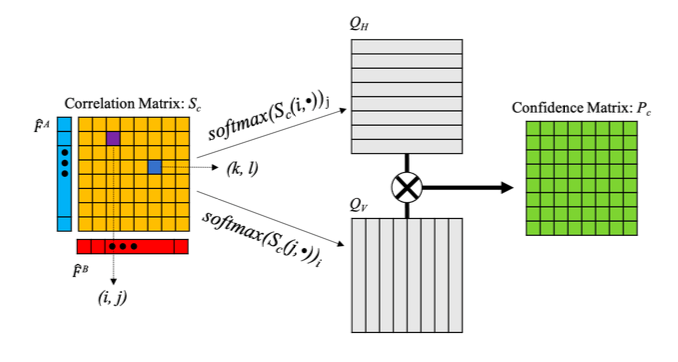
图3.2.1
3.3 在粗略转换层和精细转换层中的信息传递
如图3.3.1(a),相关矩阵被分解为多个独立的分布,学生模型间以这种形式相互查询学习。图3.3.2(b) 描述了精细层的信息传递。选择精细级别要素的一个中心点,并与其他要素图的所有点关联,以生成热图分布。教师部门热图的期望和方差可以用于用于精细层次的知识转移。
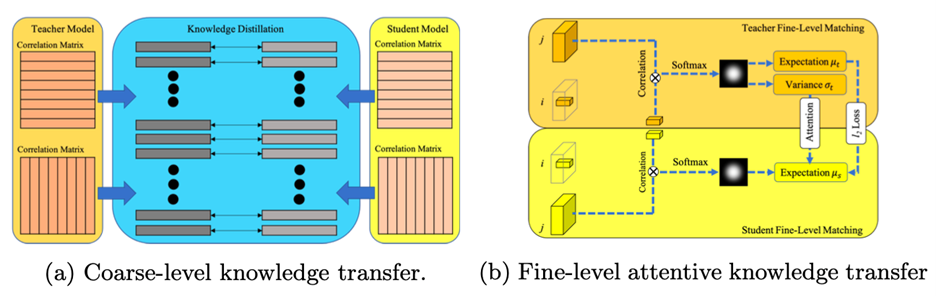
图3.3.1
实验
4.1 室内姿态检测
作者使用ScanNet来评估模型效果。ScanNet是一个由1613个单目序列组成的大型室内场景数据集,具有深度图和相机姿态。由于广泛的无纹理区域和重复模式,该数据集非常具有挑战性。作者采样了230M个重叠分数在0.4和0.8之间的图像对进行训练,并在1500个测试对上评估了学生模型。为适应深度图的尺寸,所有参与实验的图像大小调整为640×480。
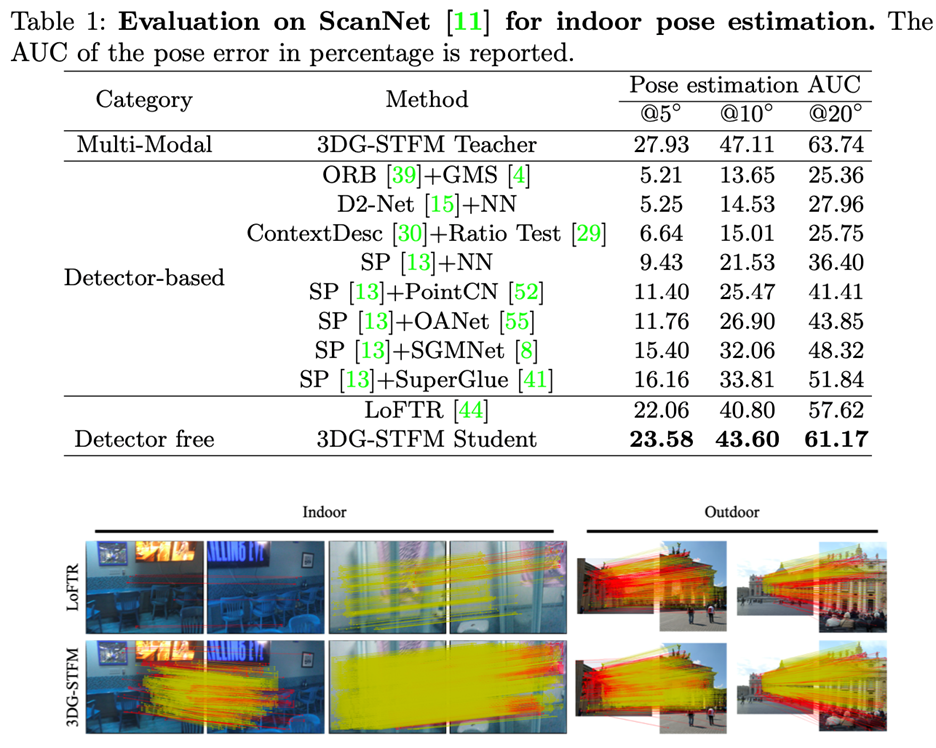
图4.1.1定性结果。学生模型与室内和室外场景中的LoFTR进行比较。文中的方法在具有重复模式和低纹理区域的挑战场景中表现更好。红色表示极线误差超过5×10−4的室内场景以及误差超过1×10−4的室外场景(在归一化图像坐标中)
作者在实验中记录了阈值 {5∘,10∘,20∘} 处姿态误差的AUC。 其中姿态误是旋转和平移中的最大角度误差。配对好的预测结果用于RANSAC求解本质矩阵。
由于发布的DRC网络是在MegaDepth上训练的,而LoFTR被证明具有更好的性能,仅将LoFTR视为最先进的网络进行比较。图3.1.1表1中的结果表明,3GD-STFM模型优于所有单一模式竞争对手。对于无检测器方法,学生模型在 10∘ 阈值的结果比LoFTR要优秀近百分之三。
对于图3.1.1中的可视化比较,学生模型显示了比LoFTR更密集和更可靠的对应关系,特别是在具有重复模式的区域。此外,模型在低纹理区域提供了更鲁棒的对应,这也有利于姿态估计。平均而言,学生模型在每对室内图像上检测到1192.84个内部对应,远高于LoFTR的887.04个内部对应。数值和定性结果都证明了学生模型从教师模型中学习RGB诱导深度分布的有效性。
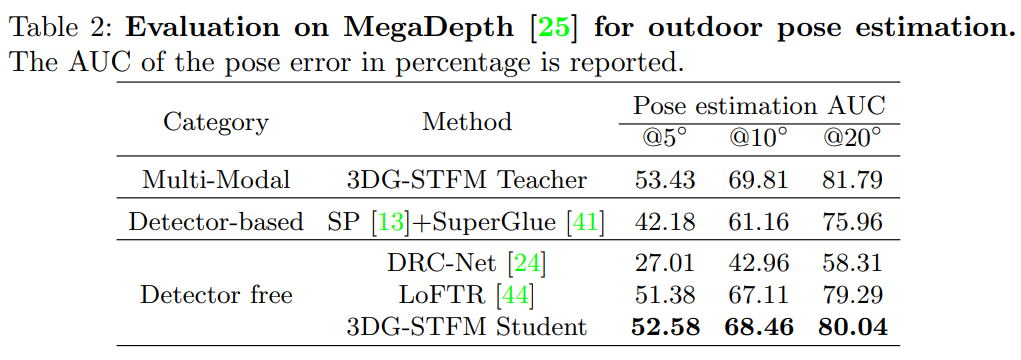
图4.2.1
4.2 室外姿态检测
文中使用MegaDepth来进行户外检测,Megadepth是一个包含196个不同户外场景的1M互联网图像组成的数据集,用于户外姿势估计评估。作者依照DISK选择1500对进行验证。
在推断过程中,作者将图像的长边调整为1200,并遵循与室内姿态估计时相同的评估协议。如图3.1.1所示,由于室外图像包含较少的低纹理区域和重复图案,LoFTR还可以预测鲁棒相机姿态估计的许多正确对应。然而,图3.2.1中的结果表明,3DG-STFM教师模型通过利用相对深度实现了更好的绩效。从老师那里学习到的学生模型表现也可以超过LoFTR。学生模型平均检测到1864.63对内部对应,这也高于LoFTR的1694.60对。
4.3 单应性估计
作者还评估了学生模型在HPatches数据集上的单应性估计。在前面的工作之后,文中选择了108个在大照明变化或显著视点变化下的图像序列进行评估。每个测试图像序列包含一个参考图像和五个配对图像。首先调整原始图像的尺寸,使其尺寸小于480,并找到无检测器方法的每对图像的前1K个对应关系。3DG-STFM学生模型Megadepth上进行训练。所有基线结果均使用其原始默认实现超参数进行报告。单应性估计由OpenCV RANSAC实现执行。
接下来,计算图像四个角的重投影平均误差,并在图3.3.1中报告累积曲线下面积(AUC),最多三个值:3、5和10个像素。3DG-STFM学生模型在同质图估计任务上得到了很好的推广,并与图3.3.1所示的无检测器方法相比实现了最佳性能。在AUC@10px处,基于Superpoint和Superglue的方法表现的比文中的方法更好。然而,3DG-STFM学生模型在其他两个严格指标下表现出更精确的性能。
在AUC@10px处,基于Superpoint和Superglue的方法表现的比文中的方法更好。然而,3DG-STFM学生模型在其他两个严格指标下表现出更精确的性能。
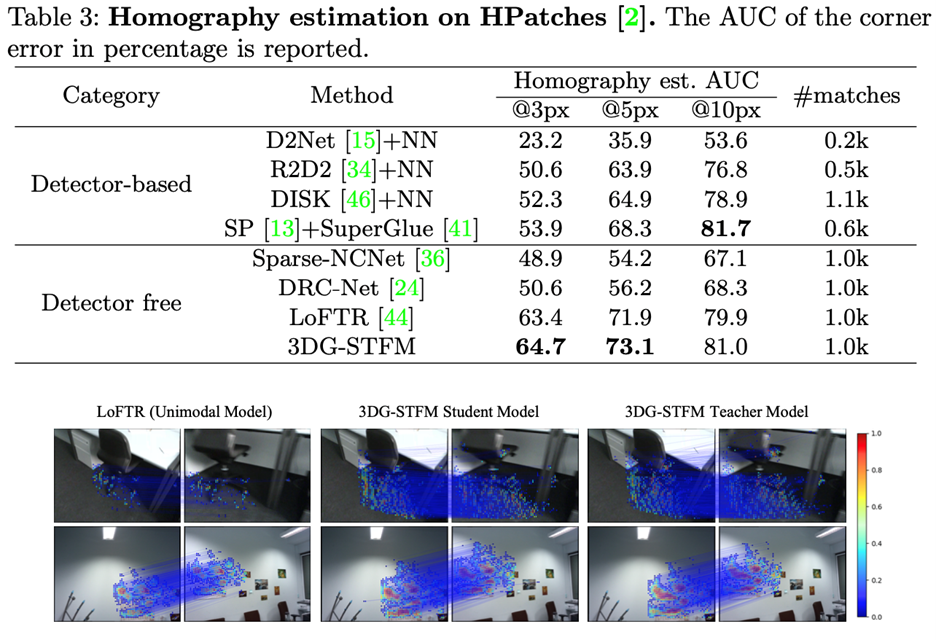
图4.3.1 可视化匹配分布变化,以便更好地理解学生模型和教师模型的学习过程。对应散射的颜色由每个模型的置信度预测确定。教师模型不仅指导学生模型找到更多的对应关系,还教授学生模型置信分数的分布。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢