
最近Google又利用钞能力,不仅将语言模型PaLM升级为视觉语言模型,还训了一个史上最大的ViT模型!
近几年自然语言处理的进展很大程度上都来自于大规模语言模型,每次发布的新模型都将参数量、训练数据量推向新高,同时也会对现有基准排行进行一次屠榜!
比如今年4月,Google发布5400亿参数的语言模型PaLM(Pathways Language Model)在语言和推理类的一系列测评中成功超越人类,尤其是在few-shot小样本学习场景下的优异性能,也让PaLM被认为是下一代语言模型的发展方向。
同理,视觉语言模型其实也是大力出奇迹,可以通过提升模型的规模来提升性能。
当然了,如果只是多任务的视觉语言模型,显然还不是很通用,还得支持多种语言的输入输出才行。
最近Google就将PaLM扩展升级成PALI(Pathways Language and Image model),兼具多语言和图像理解的能力,同时支持100+种语言来执行各种横跨视觉、语言和多模态图像和语言应用,如视觉问题回答、图像说明(image caption)、物体检测、图像分类、OCR、文本推理等。

论文链接:https://arxiv.org/abs/2209.06794
模型的训练使用的是一个公开的图像集合,其中包括自动爬取的109种语言的标注,文中也称之为WebLI数据集。
在WebLI上预训练的PaLI模型在多个图像和语言基准上取得了最先进的性能,如COCO-Captions、TextCaps、VQAv2、OK-VQA、TextVQA等等,也超越了先前模型的多语言视觉描述(multilingual visual captioning)和视觉问答的基准。
PALI的目标之一是研究语言和视觉模型在性能和规模上的联系是否相同,特别是语言-图像模型的可扩展性(scalability)。
所以模型的架构设计上就很简单,主要是为了实验方便,尤其是可重复使用且可扩展。
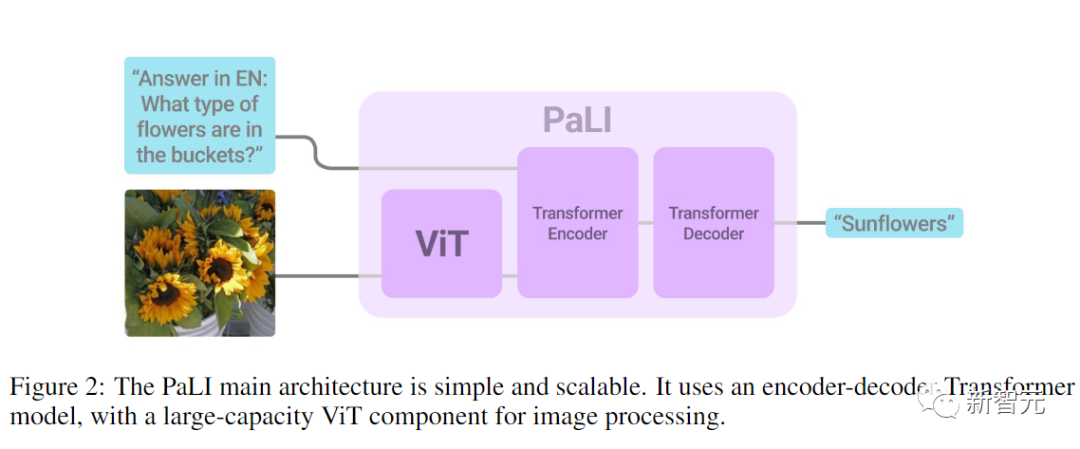
模型由一个处理输入文本的Transformer编码器和一个生成输出文本的自回归Transformer解码器组成。
在处理图像时,Transformer编码器的输入还包括代表由ViT处理的图像的视觉词(visual words)。
PaLI模型的一个关键设计是重用,研究人员用之前训练过的单模态视觉和语言模型(如mT5-XXL和大型ViTs)的权重作为模型的种子,这种重用不仅使单模态训练的能力得到迁移,而且还能节省计算成本。
模型的视觉组件使用的是迄今为止最大的ViT架构ViT-e,它与18亿参数的ViT-G模型具有相同的结构,并使用相同的训练参数,区别就是扩展为了40亿参数。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢