

论文地址:https://arxiv.org/abs/2209.08726
导读
最近,Transformers 在各种视觉任务中表现可喜。Transformer 设计中的一个具有挑战性的问题是全局自注意力的计算成本非常高,尤其是对于高分辨率视觉任务。局部自注意力在局部区域内进行注意力计算以提高其效率,这导致它们在单个注意力层中的感受野不够大,导致上下文建模不足。
在观察场景时,人类通常专注于局部区域,而以粗粒度关注非注意力区域。基于这一观察,作者开发了轴向扩展窗口自注意力机制,该机制在局部窗口内执行细粒度自注意力,在水平轴和垂直轴上执行粗粒度自注意力,因此可以有效地捕获短和远距离的视觉依赖。
贡献
长期以来,计算机视觉建模一直由卷积神经网络 (CNN) 主导。最近,自然语言处理(NLP)领域的 Transformer 模型引起了计算机视觉(CV)研究人员的极大兴趣。 Vision Transformer (ViT) 模型及其变体在许多核心视觉任务上获得了最先进的结果。继承自 NLP 的原始 ViT 首先将输入图像拆分为Patch,同时配备一个可训练类 (CLS) Token,该Token附加到输入Patch Token。接下来,Patch在 NLP 应用程序中的处理方式与Token相同,使用自注意力层进行全局信息通信,最后使用输出 CLS Token 进行预测。最近的工作表明,ViT 在大规模数据集上优于最先进的卷积网络。然而,当在较小的数据集上进行训练时,ViT 通常不如基于卷积层的对应模型。
原始 ViT 缺乏局部性和平移等效性等归纳偏差,导致 ViT 模型的过度拟合和数据效率低下。为了解决这种数据效率低下的问题,随后的大量工作研究了如何将 CNN 模型的局部性引入 ViT 模型以提高其可扩展性。这些方法通常会重新引入分层架构来补偿非局部性的损失,例如 Swin Transformer。
局部自注意力和分层 ViT (LSAH-ViT) 已被证明可以解决数据效率低下的问题并缓解模型过度拟合。然而,LSAH-ViT 在浅层使用基于窗口的注意力,失去了原始 ViT 的非局部性,这导致 LSAH-ViT 的模型容量有限,因此不适用于 ImageNet-21K 等更大的数据机制。为了架起窗口之间的联系,之前的 LSAH-ViT 作品提出了专门的设计,例如“haloing operation”和“shifted window”。这些方法通常需要复杂的架构设计,并且感受野扩大非常缓慢,并且需要堆叠大量块来实现全局自注意力。
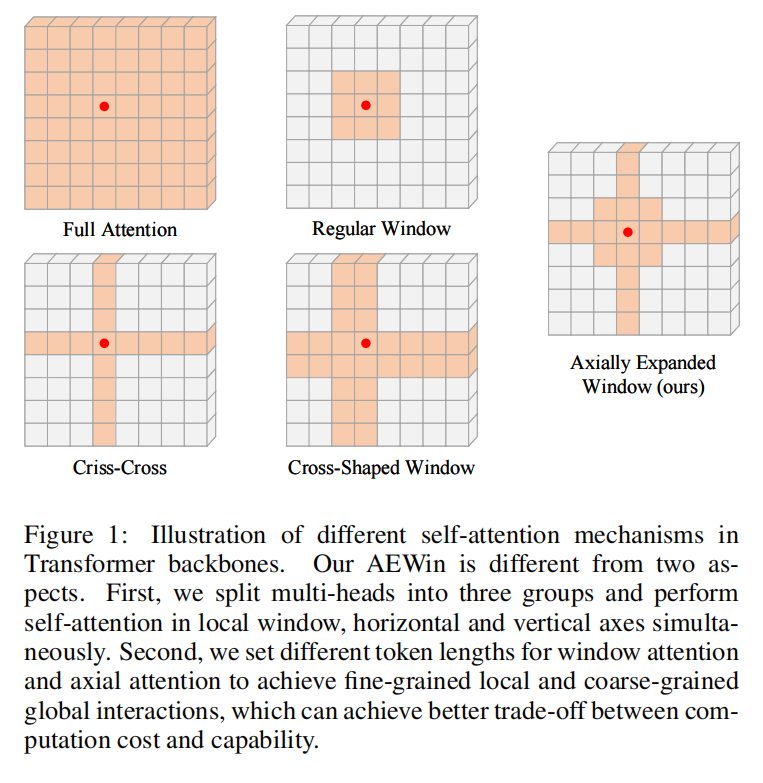
在观察场景时,人类通常专注于局部区域,而以粗粒度关注非注意力区域。基于这一观察提出了轴向扩展窗口(AEWin)自注意力,如图 1 所示,并与现有的自注意力机制进行了比较。考虑到附近区域之间的视觉依赖性通常比远处更强,作者在局部窗口内执行细粒度自注意力,在水平轴和垂直轴上执行粗粒度注意力。
将多头分成3个平行的组,前2组的Head数是最后一组的一半,前两组分别用于水平轴和垂直轴上的self-attention,最后一组group 用于局部窗口内的self-attention。值得注意的是,采用AEWin自注意力机制,局部窗口、横轴、纵轴的自注意力是并行计算的,这种并行策略并没有引入额外的计算成本。
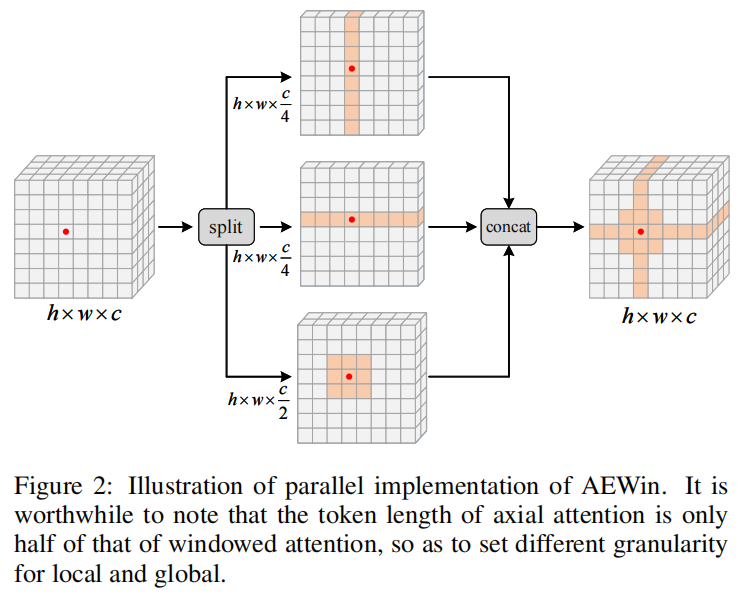
如图 2 所示,特征图用long tokens关注其最近的环境,用short tokens关注其水平和垂直轴上的环境,以捕获粗粒度的视觉依赖关系。因此,它能够有效地捕捉短程和长程的视觉依赖。得益于细粒度的窗口自注意力和粗粒度的轴向自注意力,与图 1 所示的现有局部自注意力机制相比,AEWin 自注意力可以更好地平衡性能和计算成本。
基于提出的 AEWin self-attention 设计了一个具有分层架构的通用视觉 Transformer 主干,命名为 AEWin Transformer。Tiny AEWin-T 在 ImageNet-1K 上实现了 83.6% 的 Top-1 准确度,无需任何额外的训练数据或标签。
方法
3.1、总体结构
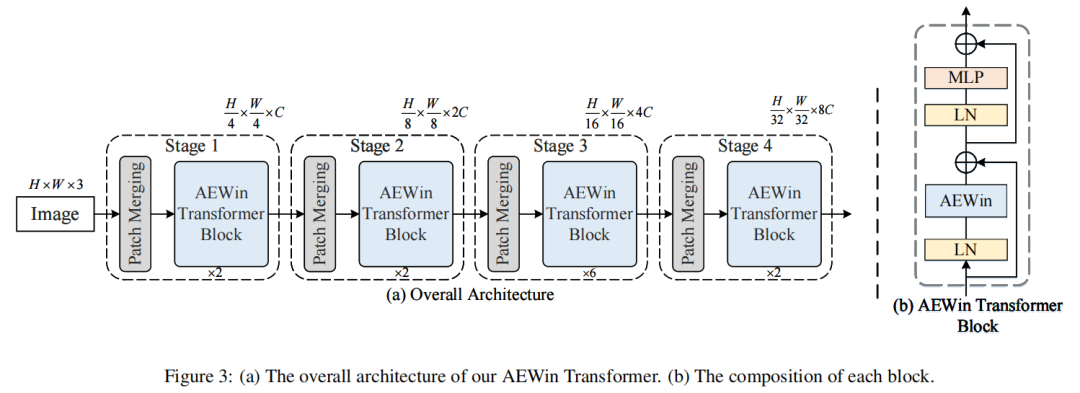
AEWin-ViT 架构的概述如图 3 (a) 所示,它说明了Tiny版本。AEWin-ViT 由4个分层阶段组成,遵循Swin-ViT中流行的设计来构建分层架构以捕获多尺度特征并交替使用移位窗口。每个阶段都包含一个patch merging layer和多个 AEWin Transformer Block。随着网络越来越深,输入特征通过patch merging layer按一定比例进行空间下采样,通道维度扩大两倍,产生分层图像表示。
具体来说,空间下采样率在第一阶段设置为 4,在后3个阶段设置为 2,使用与 Swin-ViT 相同的patch merging layer。patch merging layer的输出被馈送到后续的 AEWin Transformer Block中,并且Token的数量保持不变。最后,对最后一个Block的输出应用全局平均池化步骤,以获得最终预测的图像表示向量。
3.2、轴向扩展窗口 Self-Attention
LSAH-ViT 在浅层使用基于窗口的注意力,失去了原始 ViT 的非局部性,这导致 LSAH-ViT 的模型容量有限,因此在更大的数据机制上不利于扩展。现有作品提出了专门的设计,例如“haloing operation”和“shifted window”,以在窗口之间传递信息。这些方法通常需要复杂的架构设计,并且感受野扩大非常缓慢,并且需要堆叠大量块来实现全局自注意力。为了捕捉从短程到长程的依赖关系,受人类观察场景的启发提出了轴向扩展窗口自注意力(AEWin-Attention),它在局部窗口内执行细粒度自注意力和粗粒度自注意力。
1、轴向扩展窗口
根据multi head self-attention机制,输入特征X先线性投影到K个heads,然后每个head会在窗口或横轴或垂直轴内进行局部self-attention。
对于水平轴向self-attention,X被均匀地分割成不重叠的水平stripes,每个stripes包含1*W个token。形式上,假设第 k 个 head 的投影query、key 和 value 都有维度dk ,那么第 k 个 head 的水平轴 self-attention 的输出定义为:
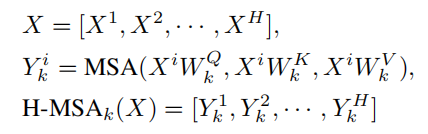
其中,MSA表示Multi-head Self-Attention。W ,K ,V 分别表示第 k 个head的query、key 和 value的投影矩阵,dk=C/K。垂直轴向self-attention可以类似地推导出来,它对第k个head的输出表示为V-MSAk(X)。
对于windowed self-attention,X被均匀地分割成高度和宽度等于M的非重叠局部窗口,每个窗口包含M×M个token。基于以上分析,第 k 个 head 的窗口化 self-attention 的输出定义为:
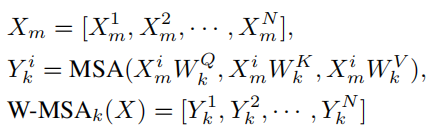
其中,N=(H×W)/(M×M),M 默认为7。
2、不同粒度的并行实现
将K个head分成3个平行组,前2组为K/4个head,最后一组为K/2个head,从而在局部和全局之间建立了不同的粒度,如图2所示。第一组head进行横轴自注意力,第二组head进行纵轴自注意力,第三组head进行局部窗口自注意力。最后,这三个平行组的输出将被重新连接在一起。
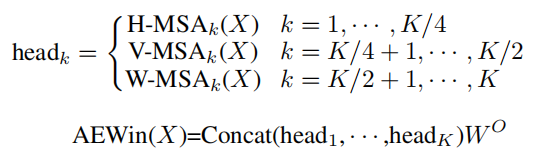
其中,W是常用的投影矩阵,用于积分三组的输出Token。与分别逐步实现轴向自注意力和窗口自注意力相比,这种并行机制具有较低的计算复杂度,通过仔细设计不同组的head数可以实现不同的粒度。
3、Complexity Analysis
给定大小为H×W×C和窗口大小(M,M)的输入特征,M 默认设置为7,标准的全局自注意力的计算复杂度为
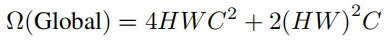
然而,提出的AEW注意力在并行实现下的计算复杂度为
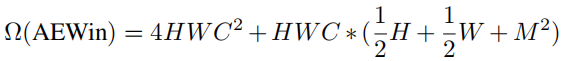
与全局相比,这可以明显减轻计算和内存负担,因为2HW>>(1/2H+1/2W+M2)始终成立。
3.3、AEWin Transformer Block
采用上述自注意机制,AEWin Transformer block 定义为:
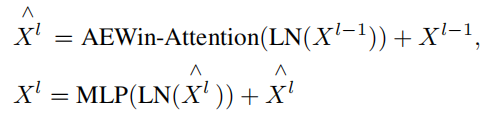
其中和分别表示Block l的AEWin模块和MLP模块的输出特征。在计算 self-attention 时,遵循 Swin-ViT,在计算相似度时包括每个head的相对位置偏差 B。
实验
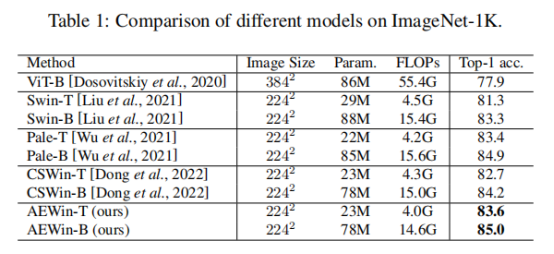
表1比较了我们的AEWinTransformer与ImageNet-1K上最先进的视觉Transformer骨干的性能。与ViT-B相比,我们的AEWinT模型的+比ViT-B好5.7%,计算复杂度要低得多。同时,我们的AEWinTransformer变体的性能优于最先进的基于Transformer的骨干,并且+比最相关的CSWinTransformer高出0.9%。与表1中的所有模型相比,AEWinTransformer的计算复杂度最低。
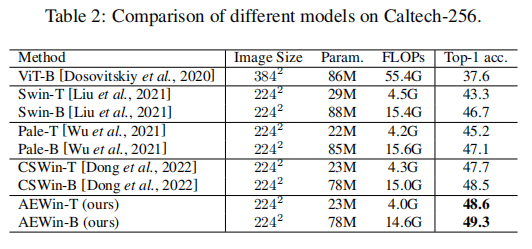
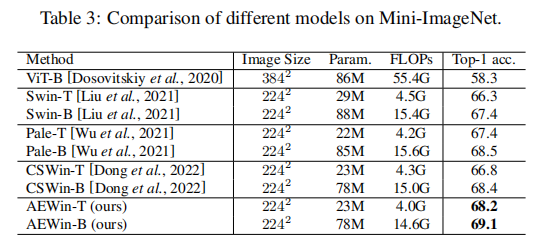
我们在表2和表3中展示了ViT在小数据集上的性能。众所周知,ViTs通常在这些任务上表现不佳,因为它们通常需要对大型数据集进行训练
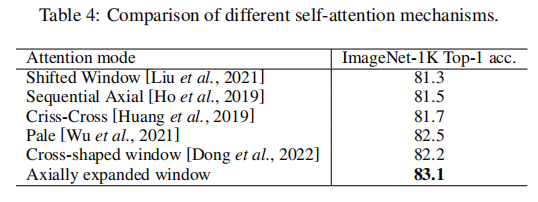
为了进行公平的比较,我们使用Swin-T作为骨干,只改变了自我注意机制。如表4所示,我们的AEWin自我注意机制的表现优于现有的自我注意机制。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢