
作者:Wenhan Xiong, Anchit Gupta, Shubham Toshniwal, 等
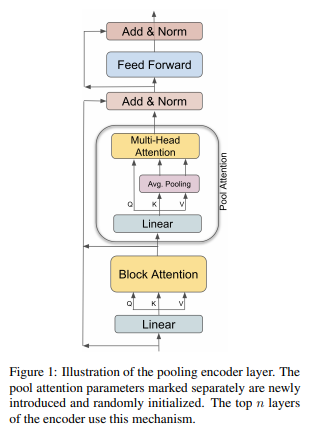
简介:本文是针对长序列输入调整现有预训练文本到文本模型的实证研究。通过对预训练管道的三个轴——模型架构、优化目标和预训练语料库的全面研究,作者提出了一种有效的方法,可以从现有的短上下文模型中构建长上下文模型。具体来说,我们将transformer中的全部注意力替换为池增强块级注意力,并使用具有不同长度跨度的掩蔽跨度预测任务对模型进行预训练。在预训练语料库方面,作者发现使用来自大型开放域语料库的随机连接的短文档,比使用通常在域覆盖范围内受限的现有长文档语料库具有更好的性能。 根据这些发现,作者构建了一个长上下文模型,该模型在长文本QA任务上实现了有竞争力的性能,并在五个长文本摘要数据集上获取了SOTA水平 。
论文下载:https://arxiv.org/pdf/2209.10052.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢