
不久前的GTC2022,RTX4090的发布成为了发布会的亮点,使用了英国诗人拜伦之女、计算机程序创始人Ada Lovelace命名40系显卡架构。同时,还带来了一些甜品亮点,或许将对CV/NLP的工业落地带来不可忽视的推动。
CV-CUDA开源项目:加速计算机视觉应用

按照老黄在GTC的屁屁踢,CV-CUDA通过加速图像预处理和后处理算法,在成本不变的情况下将图像处理数量提高为原本的10倍。
由于近年来移动互联网流量越来越大,以视觉媒介尤其是以视频为主,而且很多视频将越来越多地在云端被 AI 特效和计算机图形学所处理或增强。AI的成像处理和计算机视觉pipeline常在图像数据预处理和后处理处遭遇性能瓶颈。为了帮助更快、更高效地大规模处理图像,NVIDIA 推出了 CV-CUDA,这是一个用于构建加速型端到端计算机视觉和图像处理pipeline的开源库。
CV-CUDA 可为AI特效加速,例如视频或图像的亮度增强、图像修复重建、背景模糊和超分辨率等等。尽管CUDA已经为计算机视觉的深度学习模型方面提供了巨大的加速。但使用传统计算机视觉工具进行预处理和后处理仍需耗费大量时间和计算能力。而 CV-CUDA 则为开发者提供了 50 多种高性能计算机视觉算法,以及一种可轻松实现自定义内核的开发框架,以及诸多zero-copy的接口,从而消除AI模型推理流程中前后处理部分的瓶颈,这能带来更高的吞吐量和更低的云计算成本。

CV-CUDA通过手动优化的CUDA Kernel加速图像预处理和后处理,并原生集成于 C/C++、Python 和常见的深度学习框架(例如 PyTorch)中。开发者可在 12 月抢先体验CV-CUDA,测试版将于明年 3 月发布。
抢先体验CV-CUDA可点击本文左下角 [阅读原文] 提前申请early access,将在年底或明年初获得alpha版本体验资格,但目前仅限于以企业身份进行申请,不接受个人研究者的申请。
第四代Tensor Core: 大幅加速NLP训练
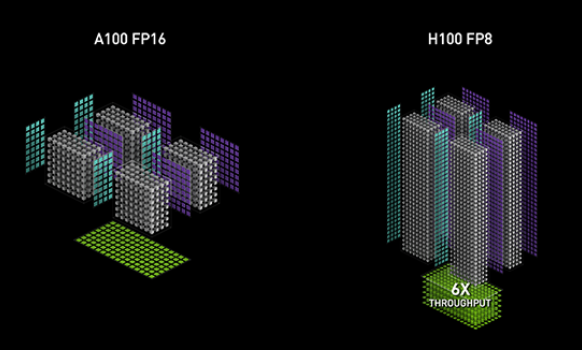
早在 Hopper 架构发布时,第四代Tensor Core就已经被揭开面纱,复习一遍,按官网的说法:“新的第四代 Tensor Core 专为深度学习矩阵乘法和累加数学运算而设计,可加速更多数据类型,并支持细粒度结构化稀疏,可将张量矩阵运算的吞吐量提升至前一代产品的 2 倍以上。Tensor Core 的更新还将加速新的 FP8 精度模式,而独立的浮点和整数数据路径允许使用混合计算和寻址计算,从而更高效地执行工作负载。”
从前,AMP (自动混合精度训练) 一般是指在cv和nlp任务中,使用fp32/tf32和fp16/bf16进行混合精度训练;而在Transformer主导的NLP任务中,16位的训练精度常都有冗余。同时,由于Transformer的引入,无论是语言模型、多模态模型、推荐系统、蛋白质折叠预测乃至使用了视觉Transformer的CV任务(如各种基于Diffusion Model的生成模型),都逐渐走向大模型时代。在AI大模型时代,计算量日益庞大,Transformer网络的训练时间甚至会延长到几个月。与 Ampere 上的 FP16 相比,Hopper / Ada 架构新增的 FP8 精度可提供高达 6 倍的性能。所以,基本可以认为,第四代Tensor Core是为加速训练Transformer模型打造的新一代Tensor Core,能够进行 FP8 和 FP16 的混合精度训练,大幅加速 Transformer based 模型的训练,同时保持模型训练的准确性。FP8 还可大幅提升大型语言模型推理的速度,性能提升高达 Ampere 架构的 30 倍。
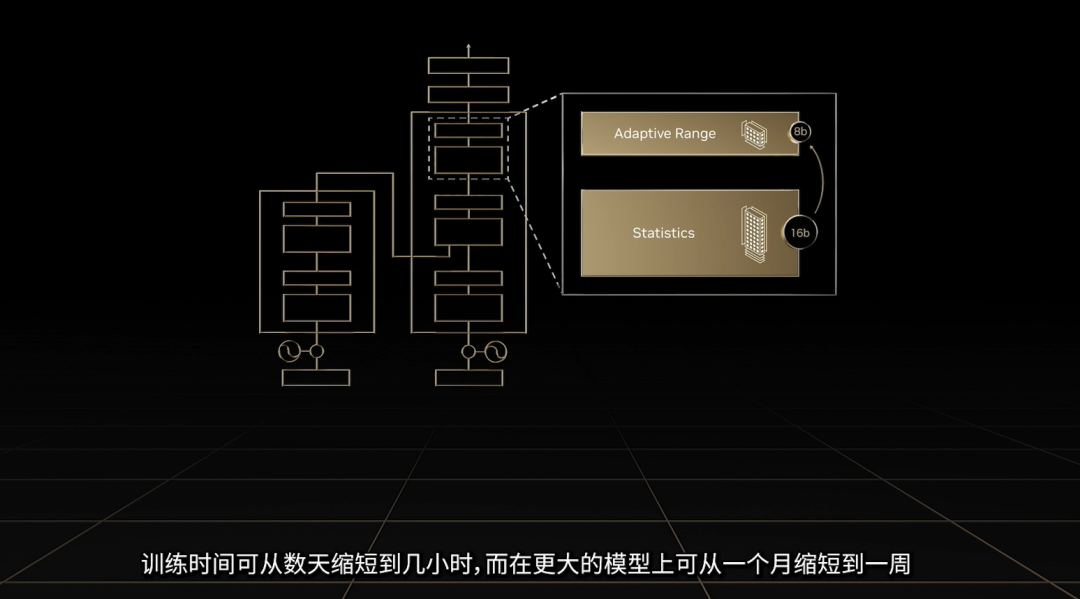
视觉Transformer模型也预期可以受益于此,这或许将是模型训练速度提升的一个巨大飞跃,将AI全面带入大模型时代。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢