
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:移动平均单头门控注意力、面向稀疏训练通用框架的层冻结和数据筛分、基于最小数据假设的扩散模型理论、语言模型和自动定理证明器的整合、非语言机器学习任务的语言界面微调、多智能体环境中的智能体开发评估和扩展学习、动态环境室内定位、动态环境中的感知四足运动、无限深度神经网络变分推理
1、[LG] Mega: Moving Average Equipped Gated Attention
X Ma, C Zhou, X Kong, J He, L Gui, G Neubig, J May, L Zettlemoyer
[University of Southern California & Meta AI Research & CMU & Shanghai Jiao Tong University]
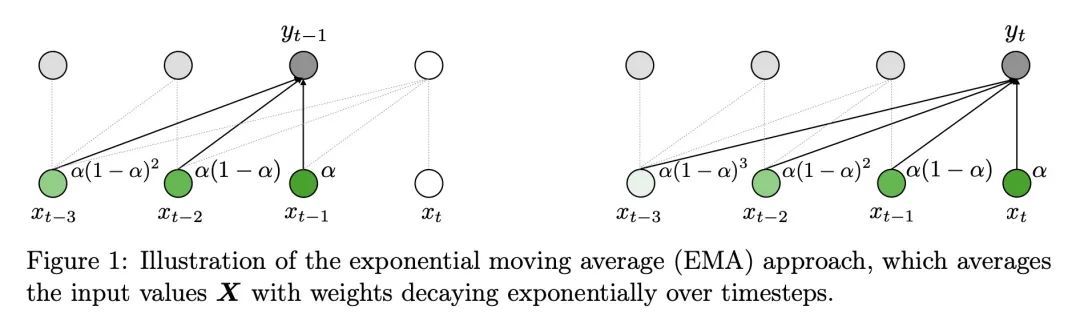
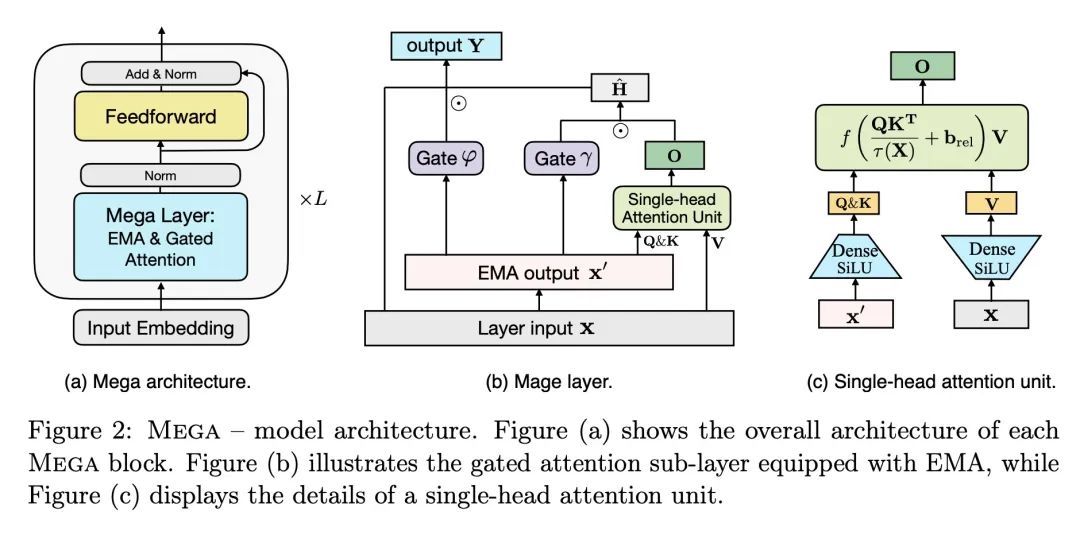
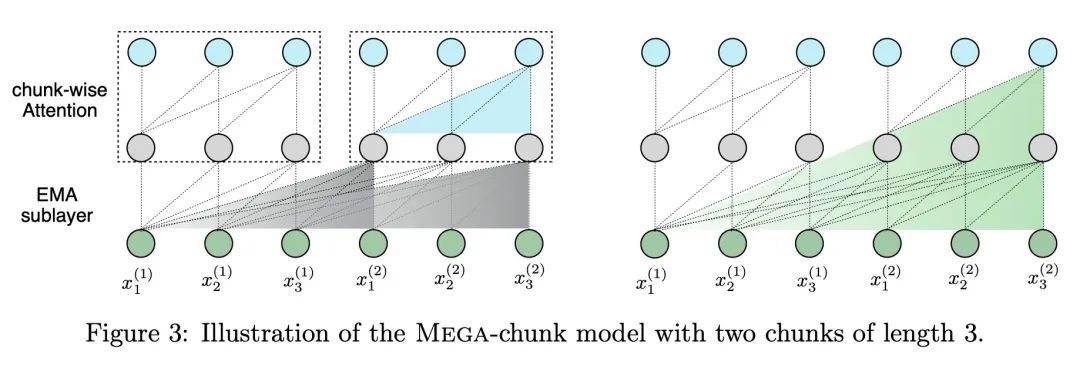
Mega:移动平均单头门控注意力。Transformer注意力机制的设计选择,包括弱的感应偏差和二次计算的复杂性,限制了它对长序列建模的应用。本文提出Mega,一种简单的、有理论基础的、配备有(指数)移动平均的单头门控注意力机制,将位置感知的局部依赖的归纳偏差纳入位置无关的注意力机制。进一步提出了Mega的一种变体,提供了线性的时间和空间复杂性,但只产生最小的质量损失,通过有效地将整个序列分割成具有固定长度的多个块。在广泛的序列建模基准上进行的实验,包括Long Range Arena、神经机器翻译、自回归语言建模以及图像和语音分类,表明Mega比其他序列模型,包括Transformer的变种和最近的状态空间模型,都有明显的改进。
The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences. In this paper, we introduce Mega, a simple, theoretically grounded, single-head gated attention mechanism equipped with (exponential) moving average to incorporate inductive bias of position-aware local dependencies into the position-agnostic attention mechanism. We further propose a variant of Mega that offers linear time and space complexity yet yields only minimal quality loss, by efficiently splitting the whole sequence into multiple chunks with fixed length. Extensive experiments on a wide range of sequence modeling benchmarks, including the Long Range Arena, neural machine translation, autoregressive language modeling, and image and speech classification, show that Mega achieves significant improvements over other sequence models, including variants of Transformers and recent state space models.
https://arxiv.org/abs/2209.10655

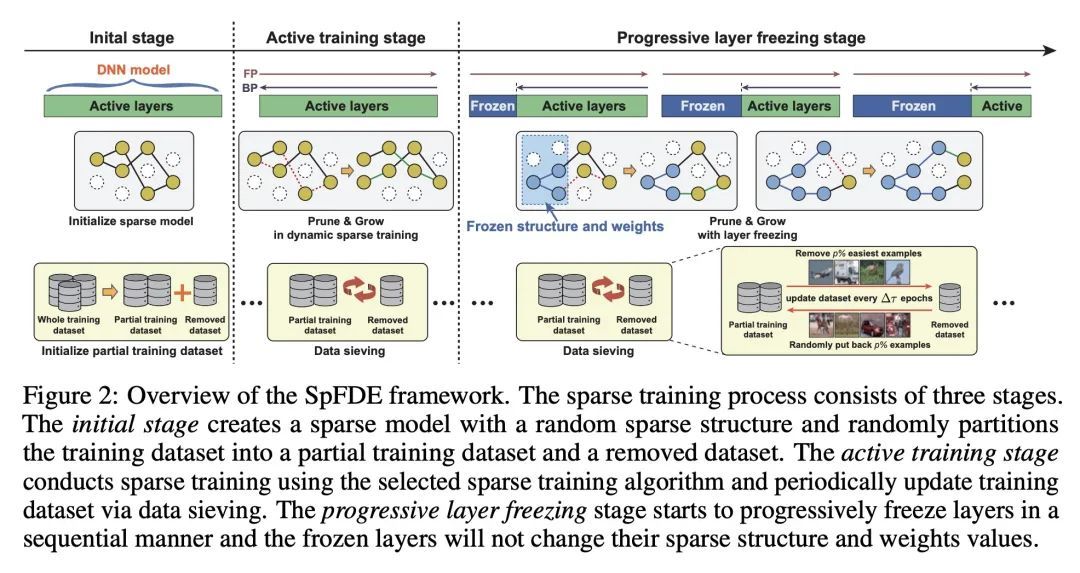
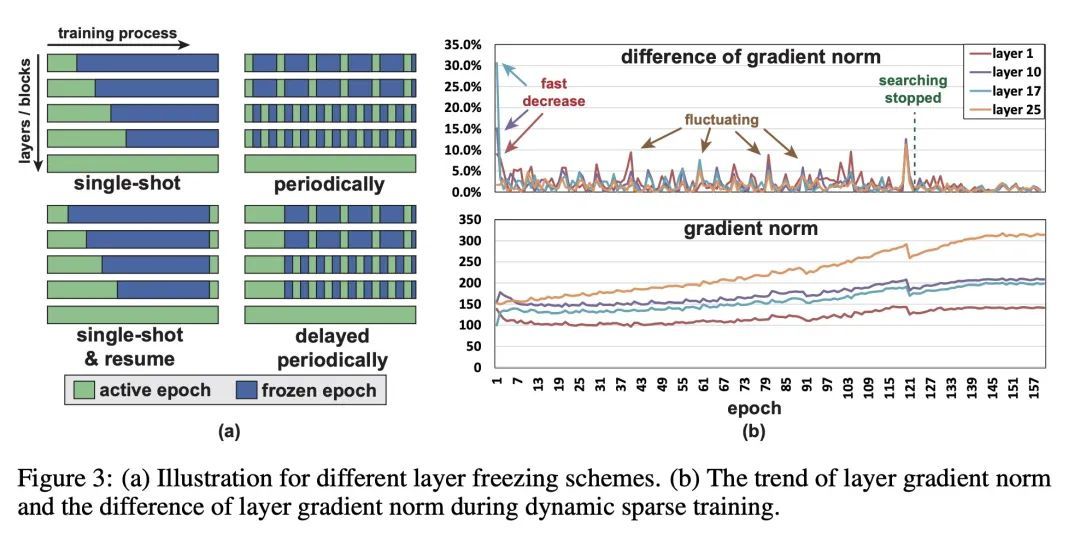
2、[LG] Layer Freezing & Data Sieving: Missing Pieces of a Generic Framework for Sparse Training
G Yuan, Y Li, S Li, Z Kong, S Tulyakov, X Tang, Y Wang, J Ren
[Snap Inc & University of Pittsburgh & Northeastern University]
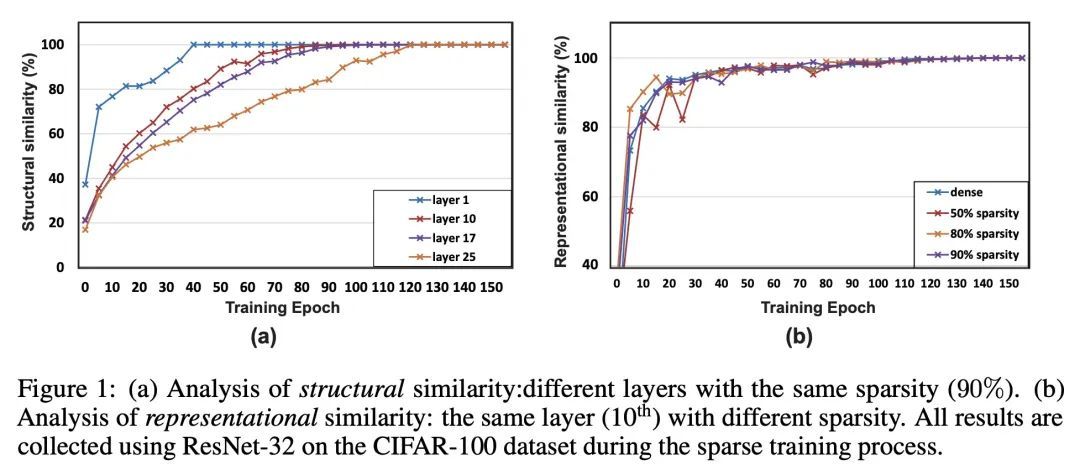
层冻结和数据筛分:稀疏训练通用框架的缺失部分。最近,稀疏训练已经成为边缘设备上高效深度学习的一个有前途的范式。目前的研究主要致力于通过进一步提高模型的稀疏度来降低训练成本。然而,增加稀疏度并不总是理想的,因为它将不可避免地在极高的稀疏度水平上引入严重的精度下降。本文致力于探索其他可能的方向,以有效和高效地减少稀疏训练成本,同时保持精度。本文研究了两种技术,即层冻结和数据筛分。首先,层冻结方法在稠密模型训练和微调中已经显示出它的成功,然而从未在稀疏训练领域采用过。然而,稀疏训练的独特特征可能会阻碍层冻结技术的应用。因此,本文分析了在稀疏训练中使用层冻结技术的可行性和潜力,发现它有可能节省大量的训练成本。其次,本文提出了一种用于数据集高效训练的数据筛分方法,通过确保在整个训练过程中只使用部分数据集来进一步降低训练成本。这两种技术都可以很好地纳入稀疏训练算法,形成一个通用框架,称为SpFDE。大量实验表明,SpFDE可以大大降低训练成本,同时从三个方面保持精度:权重稀疏性、层冻结和数据集筛分。
Recently, sparse training has emerged as a promising paradigm for efficient deep learning on edge devices. The current research mainly devotes the efforts to reducing training costs by further increasing model sparsity. However, increasing sparsity is not always ideal since it will inevitably introduce severe accuracy degradation at an extremely high sparsity level. This paper intends to explore other possible directions to effectively and efficiently reduce sparse training costs while preserving accuracy. To this end, we investigate two techniques, namely, layer freezing and data sieving. First, the layer freezing approach has shown its success in dense model training and fine-tuning, yet it has never been adopted in the sparse training domain. Nevertheless, the unique characteristics of sparse training may hinder the incorporation of layer freezing techniques. Therefore, we analyze the feasibility and potentiality of using the layer freezing technique in sparse training and find it has the potential to save considerable training costs. Second, we propose a data sieving method for dataset-efficient training, which further reduces training costs by ensuring only a partial dataset is used throughout the entire training process. We show that both techniques can be well incorporated into the sparse training algorithm to form a generic framework, which we dub SpFDE. Our extensive experiments demonstrate that SpFDE can significantly reduce training costs while preserving accuracy from three dimensions: weight sparsity, layer freezing, and dataset sieving1.
https://arxiv.org/abs/2209.11204

3、[LG] Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions
S Chen, S Chewi, J Li, Y Li, A Salim, A R. Zhang
[UC Berkeley & MIT & Microsoft Research]
采样像学习分数一样容易:基于最小数据假设的扩散模型理论。本文为基于分数的生成模型(SGM)提供理论上的收敛保证,如去噪扩散概率模型(DDPM),其构成了大规模现实世界生成模型的支柱,如DALL-E 2。本文的主要结果是,假设有准确的分数估计,这种SGM可以有效地从基本上任意现实的数据分布中采样。与之前的工作相比,本文的结果 (1)对L-准确的分数估计(而不是L∞-准确)成立;(2)不需要限制性的函数不等式条件来排除实质性的非对数凹陷;(3)在所有相关的问题参数中呈多项式扩展;(4)只要分数误差足够小,就与最先进的朗文扩散离散化的复杂性保证一致。本文认为这是SGM在经验上取得成功的有力理论依据。本文还研究了基于临界阻尼朗文扩散(CLD)的SGM。与传统观点相反,本文提供证据表明,使用CLD并不能降低SGM的复杂性。
We provide theoretical convergence guarantees for score-based generative models (SGMs) such as denoising diffusion probabilistic models (DDPMs), which constitute the backbone of large-scale realworld generative models such as DALL·E 2. Our main result is that, assuming accurate score estimates, such SGMs can efficiently sample from essentially any realistic data distribution. In contrast to prior works, our results (1) hold for an L-accurate score estimate (rather than L∞-accurate); (2) do not require restrictive functional inequality conditions that preclude substantial non-log-concavity; (3) scale polynomially in all relevant problem parameters; and (4) match state-of-the-art complexity guarantees for discretization of the Langevin diffusion, provided that the score error is sufficiently small. We view this as strong theoretical justification for the empirical success of SGMs. We also examine SGMs based on the critically damped Langevin diffusion (CLD). Contrary to conventional wisdom, we provide evidence that the use of the CLD does not reduce the complexity of SGMs.
https://arxiv.org/abs/2209.11215

4、[LG] Thor: Wielding Hammers to Integrate Language Models and Automated Theorem Provers
A Q. Jiang, W Li...
[University of Cambridge & University of Warsaw & IDEAS NCBR & Polish Academy of Sciences & Google Research]
Thor:语言模型和自动定理证明器的整合。在定理证明中,从一个庞大的库中选择有用的前提来解开一个给定猜想的证明是至关重要的任务。这对所有的定理证明者来说都是一个挑战,特别是那些基于语言模型的定理证明者,因为他们相对无法对大量的文本形式的前提进行推理。本文提出Thor,一种整合语言模型和自动定理证明器的框架,以克服这一困难。在Thor中,一类被称为"hammers"的方法利用自动定理证明器的力量来进行前提选择,而所有其他任务则被指定给语言模型。Thor将语言模型在PISA数据集上的成功率从39%提高到57%,同时解决了8.2%的语言模型和自动定理证明器都无法独立解决的问题。此外,在计算预算明显较少的情况下,Thor可以在MiniF2F数据集上取得与现有最佳方法相当的成功率。Thor可以通过所提供的一种简单协议为大多数流行的交互式定理证明器实例化。
In theorem proving, the task of selecting useful premises from a large library to unlock the proof of a given conjecture is crucially important. This presents a challenge for all theorem provers, especially the ones based on language models, due to their relative inability to reason over huge volumes of premises in text form. This paper introduces Thor, a framework integrating language models and automated theorem provers to overcome this difficulty. In Thor, a class of methods called hammers that leverage the power of automated theorem provers are used for premise selection, while all other tasks are designated to language models. Thor increases a language model’s success rate on the PISA dataset from 39% to 57%, while solving 8.2% of problems neither language models nor automated theorem provers are able to solve on their own. Furthermore, with a significantly smaller computational budget, Thor can achieve a success rate on the MiniF2F dataset that is on par with the best existing methods. Thor can be instantiated for the majority of popular interactive theorem provers via a straightforward protocol we provide.
https://arxiv.org/abs/2205.10893



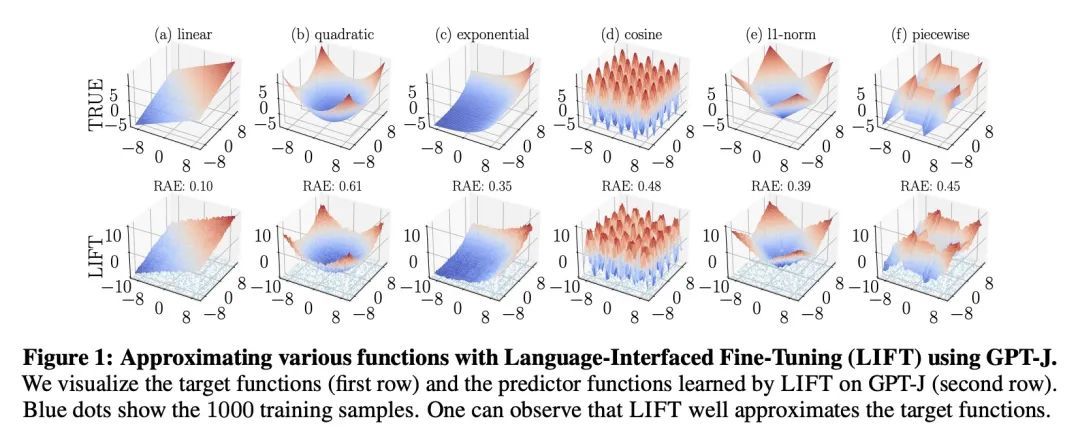
5、[LG] LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks
T Dinh, Y Zeng, R Zhang, Z Lin, M Gira, S Rajput, J Sohn, D Papailiopoulos, K Lee
[University of Wisconsin-Madison]
LIFT:非语言机器学习任务的语言界面微调。对预训练语言模型(LM)进行微调而不做任何架构上的改变,已经成为学习各种语言下游任务的一种规范。然而,对于非语言的下游任务,通常的做法是对输入层、输出层和损失函数采用特定的任务设计。例如,通过将词嵌入层替换为图像块嵌入层,将词标记输出层替换为10路输出层,将词预测损失替换为10路分类损失,就可以将LM微调为MNIST分类器。一个自然的问题出现了:LM微调能否在不改变模型结构或损失函数的情况下解决非语言的下游任务?为了回答这个问题,本文提出了语言界面微调(LIFT),通过对一套非语言分类和回归任务进行广泛的实证研究,研究其功效和局限性。LIFT不对模型结构或损失函数做任何改变,完全依赖于自然语言界面,实现了"基于语言模型的免代码机器学习"。LIFT在广泛的低维分类和回归任务中表现相对较好,在许多情况下与最佳基线的表现相匹配,特别是对于分类任务。本文报告了关于LIFT基本属性的实验结果,包括它的归纳偏差、样本效率、推断能力、对异常值和标签噪声的鲁棒性以及泛化性。本文还分析了LIFT特有的一些特性/技术,例如,通过适当的提示、预测不确定性的量化和两阶段的微调来进行情境感知学习。
Fine-tuning pretrained language models (LMs) without making any architectural changes has become a norm for learning various language downstream tasks. However, for non-language downstream tasks, a common practice is to employ task-specific designs for input, output layers, and loss functions. For instance, it is possible to fine-tune an LM into an MNIST classifier by replacing the word embedding layer with an image patch embedding layer, the word token output layer with a 10-way output layer, and the word prediction loss with a 10-way classification loss, respectively. A natural question arises: can LM fine-tuning solve non-language downstream tasks without changing the model architecture or loss function? To answer this, we propose Language-Interfaced Fine-Tuning (LIFT) and study its efficacy and limitations by conducting an extensive empirical study on a suite of non-language classification and regression tasks. LIFT does not make any changes to the model architecture or loss function, and it solely relies on the natural language interface, enabling "no-code machine learning with LMs." We find that LIFT performs relatively well across a wide range of low-dimensional classification and regression tasks, matching the performances of the best baselines in many cases, especially for the classification tasks. We report the experimental results on the fundamental properties of LIFT, including its inductive bias, sample efficiency, ability to extrapolate, robustness to outliers and label noise, and generalization. We also analyze a few properties/techniques specific to LIFT, e.g., context-aware learning via appropriate prompting, quantification of predictive uncertainty, and two-stage fine-tuning. Our code is available at this https URL.
https://arxiv.org/abs/2206.06565



另外几篇值得关注的论文:
[LG] Developing, Evaluating and Scaling Learning Agents in Multi-Agent Environments
多智能体环境中的智能体开发、评估和扩展学习
I Gemp, T Anthony, Y Bachrach, A Bhoopchand...
[DeepMind]
https://arxiv.org/abs/2209.10958

[CV] D-InLoc++: Indoor Localization in Dynamic Environments
D-InLoc++:动态环境室内定位
M Dubenova, A Zderadickova, O Kafka, T Pajdla, M Polic
[Czech Technical University in Prague]
https://arxiv.org/abs/2209.10185



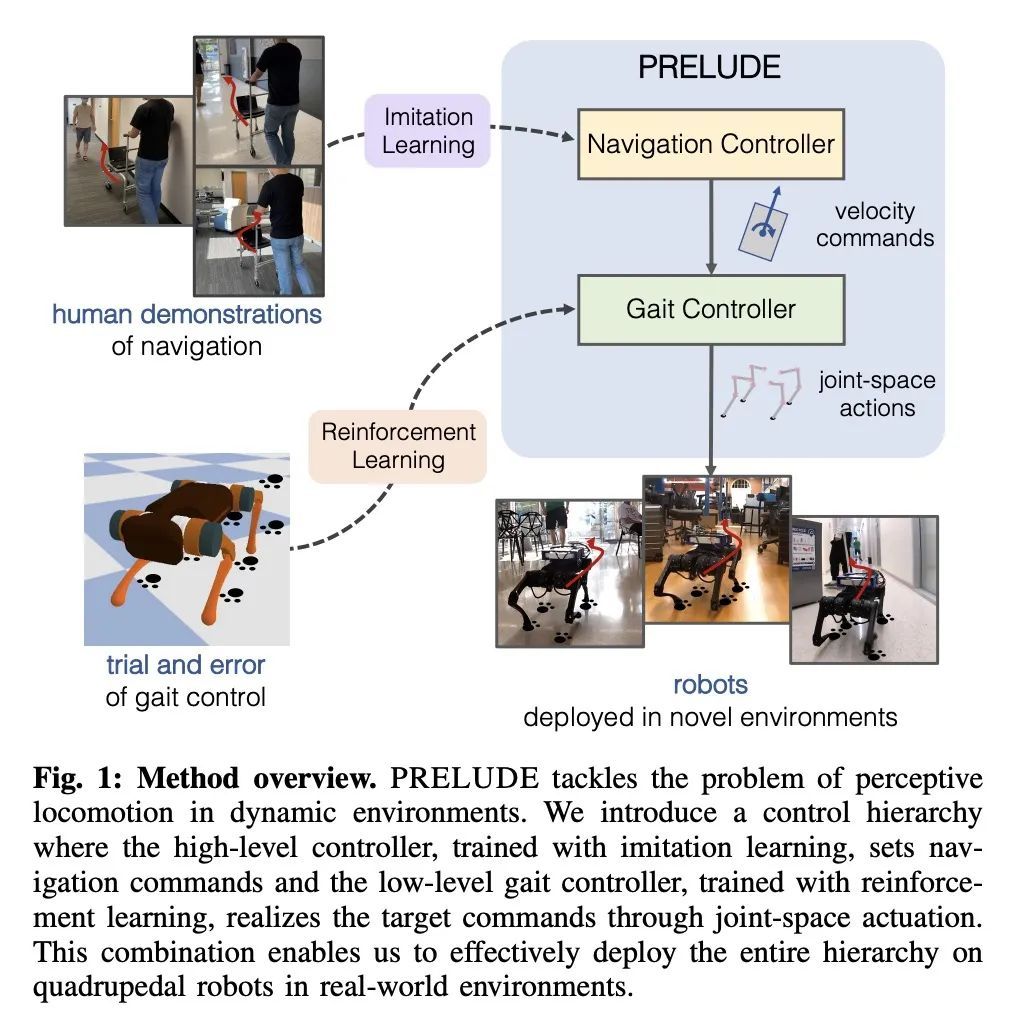
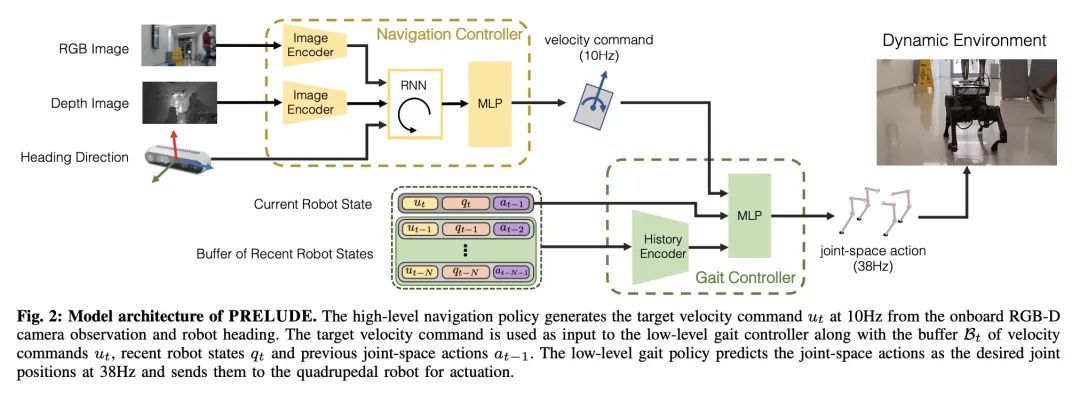
[RO] Learning to Walk by Steering: Perceptive Quadrupedal Locomotion in Dynamic Environments
通过转向学习走路:动态环境中的感知四足运动
M Seo, R Gupta, Y Zhu, A Skoutnev, L Sentis, Y Zhu
[The University of Texas at Austin & Vanderbilt University]
https://arxiv.org/abs/2209.09233


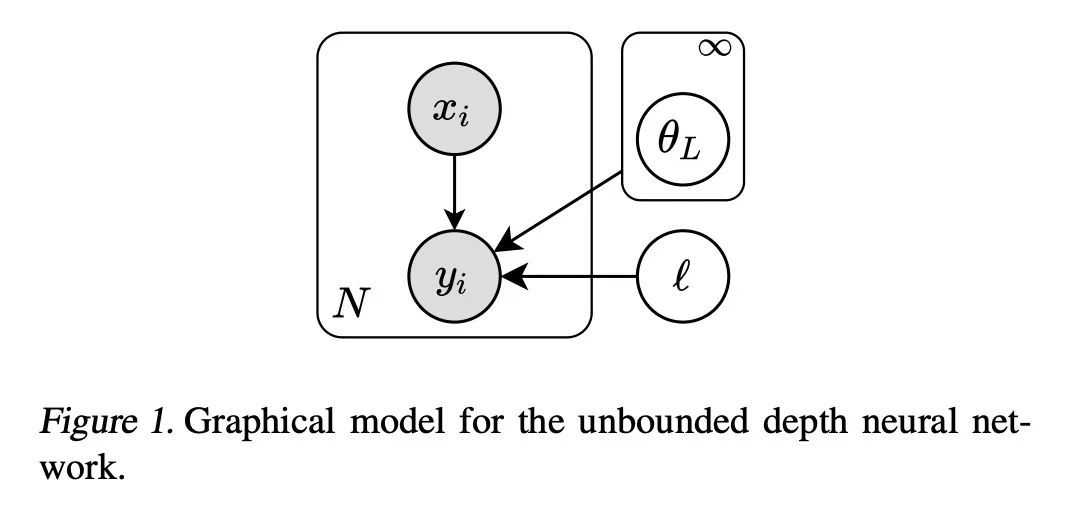
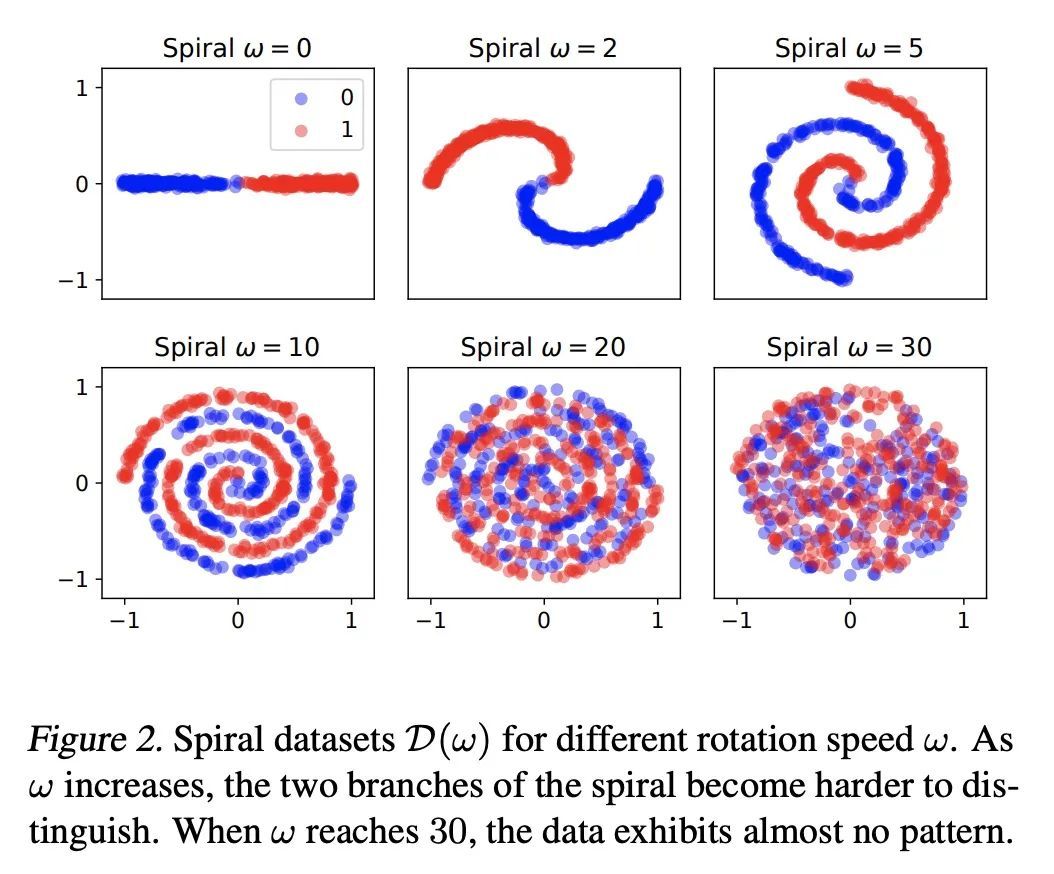
[LG] Variational Inference for Infinitely Deep Neural Networks
无限深度神经网络变分推理
A Nazaret, D Blei
[Columbia University]
https://arxiv.org/abs/2209.10091

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢