

论文地址:https://arxiv.org/abs/2209.03917
字节跳动和厦门大学提出基于掩码知识蒸馏的视觉自监督框架 dBOT,在 ImageNet 微调分类上仅使用 ImageNet-1k 作为预训练数据获得 89.0% 的预测精度,斩获自监督预训练榜首:
https://paperswithcode.com/sota/self-supervised-image-classification-on-1
MIM需要什么样的预测目标?
基于 Masked Image Modeling(MIM)的视觉预训练范式近来吸引了大量关注,具体来讲,MIM 首先随机 mask 输入图像的一部分,然后利用神经网络来预测被 mask 的部分。如何对被 mask 的部分进行表示一直以来是研究人员关注的热点,并没有一个定论,比如在 BEiT [2] 中利用 DALL-E [3] 的中间表示作为预测目标,在 MAE [4] 中直接预测原始像素,MaskFeat [5] 预测 HOG 特征。
本文首先基于掩码蒸馏框架,探究不同模型的输出结果作为预测目标对图像微调分类、目标检测、语义分割性能的影响。在多阶段的掩码知识蒸馏框架(Masked Knowledge Distillation, MKD)下,所有实验的性能均趋于一致,性能方差随着阶段而减小。
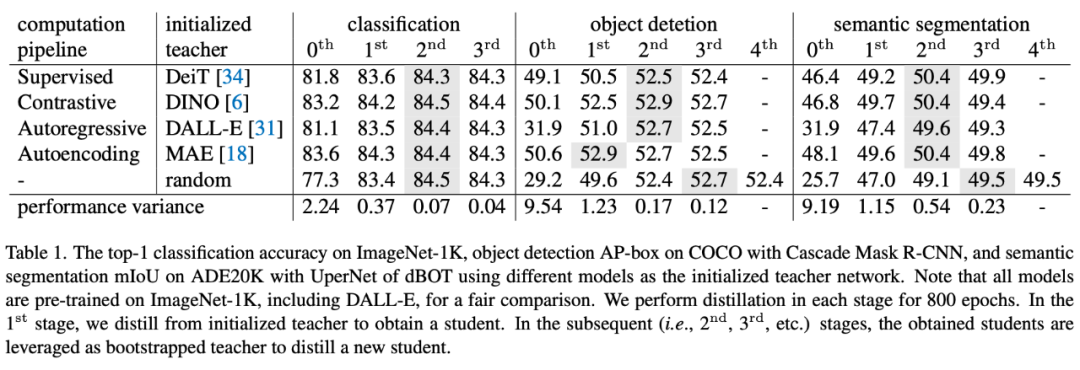
通过对实验结果的观察,可以得到如下的结论:
1. 不同预测目标得到的模型性能趋于相同;
2. 通过 MKD 可以有效提升不同预测目标(teacher)的性能;
3. 一个随机初始化的模型经过多轮训练之后表现出的性能出奇好。
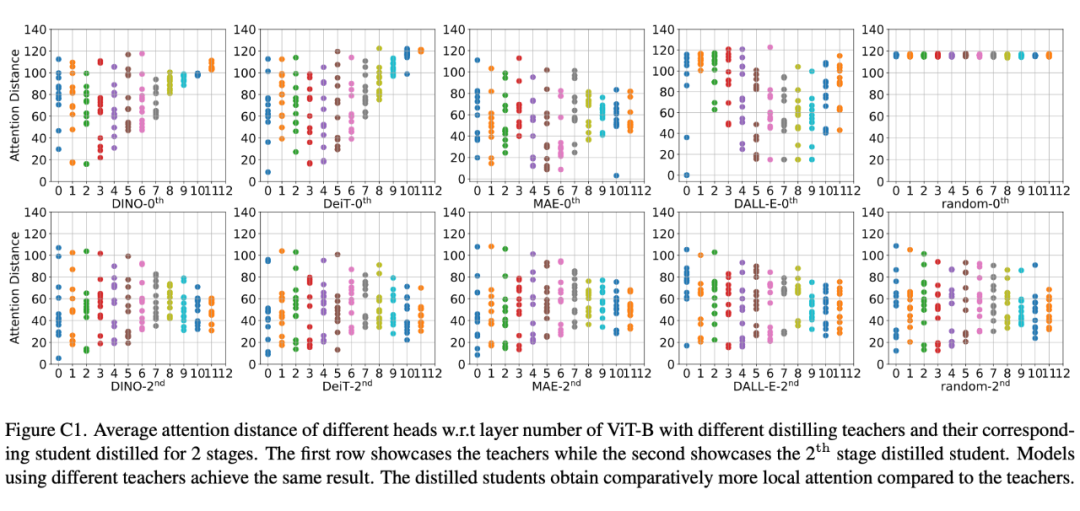
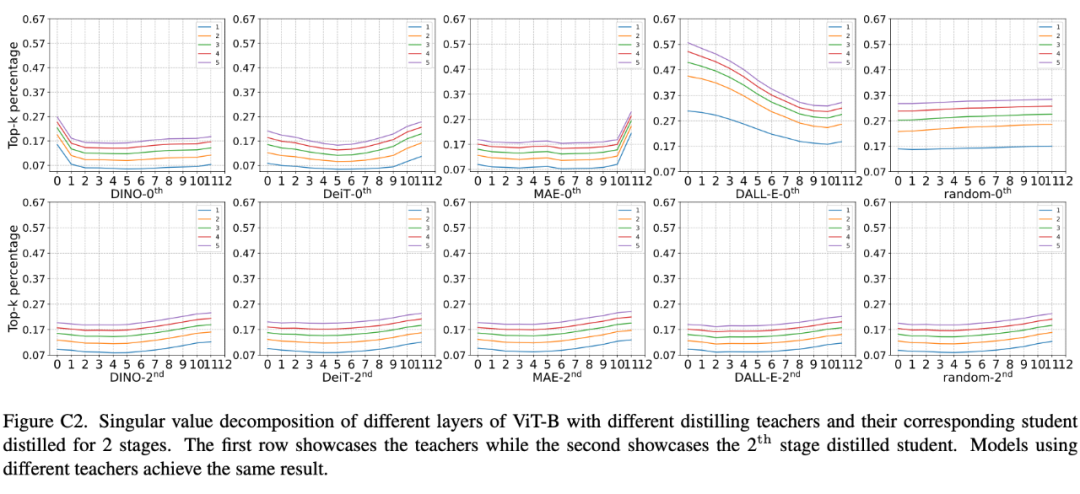
除了使用数值量化指标外,文章还使用两种可视化工具,来分析不同模型权重和输出的性质。使用不同网络做教师经过掩码知识蒸馏后,模型的权重和输出表现出了相似的性质。
可以得出:在多阶段掩码蒸馏下,目标表征的选择不重要。
dBOT方法提出
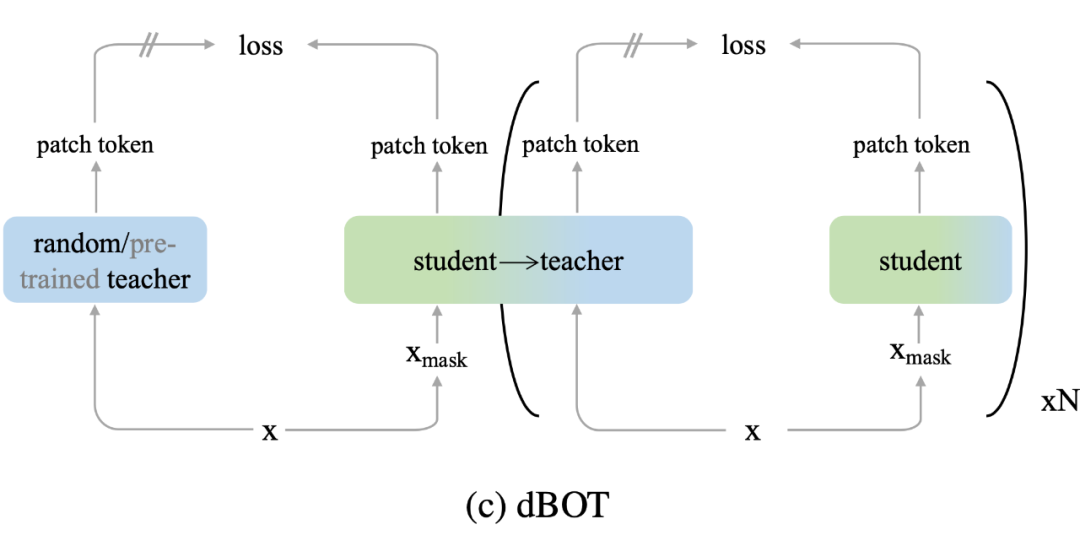
dBOT 将 MIM 训练分为不同阶段,在每个阶段中采用上个阶段的模型作为 MIM 的预测目标,在第一阶段采用一个随机初始化的模型作为预测目标。相比于之前的方法:
1. dBOT 使用预训练网络作为预测目标,不需要额外一个阶段的预训练。
2. dBOT 使用随机网络的多阶段策略,既保证了在每一个阶段提供稳定的视觉特征,又通过阶段间 teacher 网络的更新,保证了更强的视觉特征。
3. dBOT 一开始使用一个随机初始化的网络做 teacher,极大降低了设计上的 inductive bias。
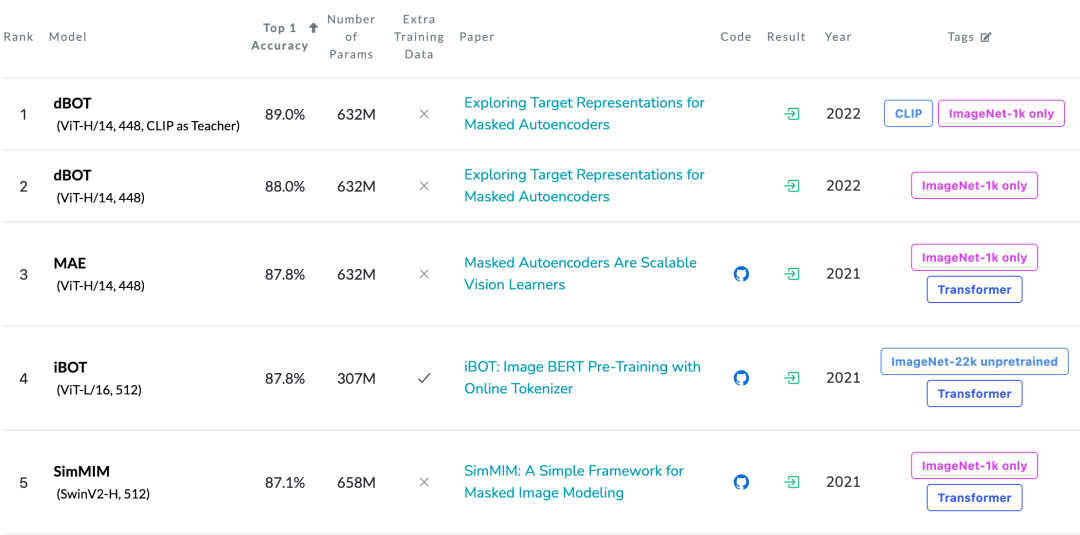
结果和分析
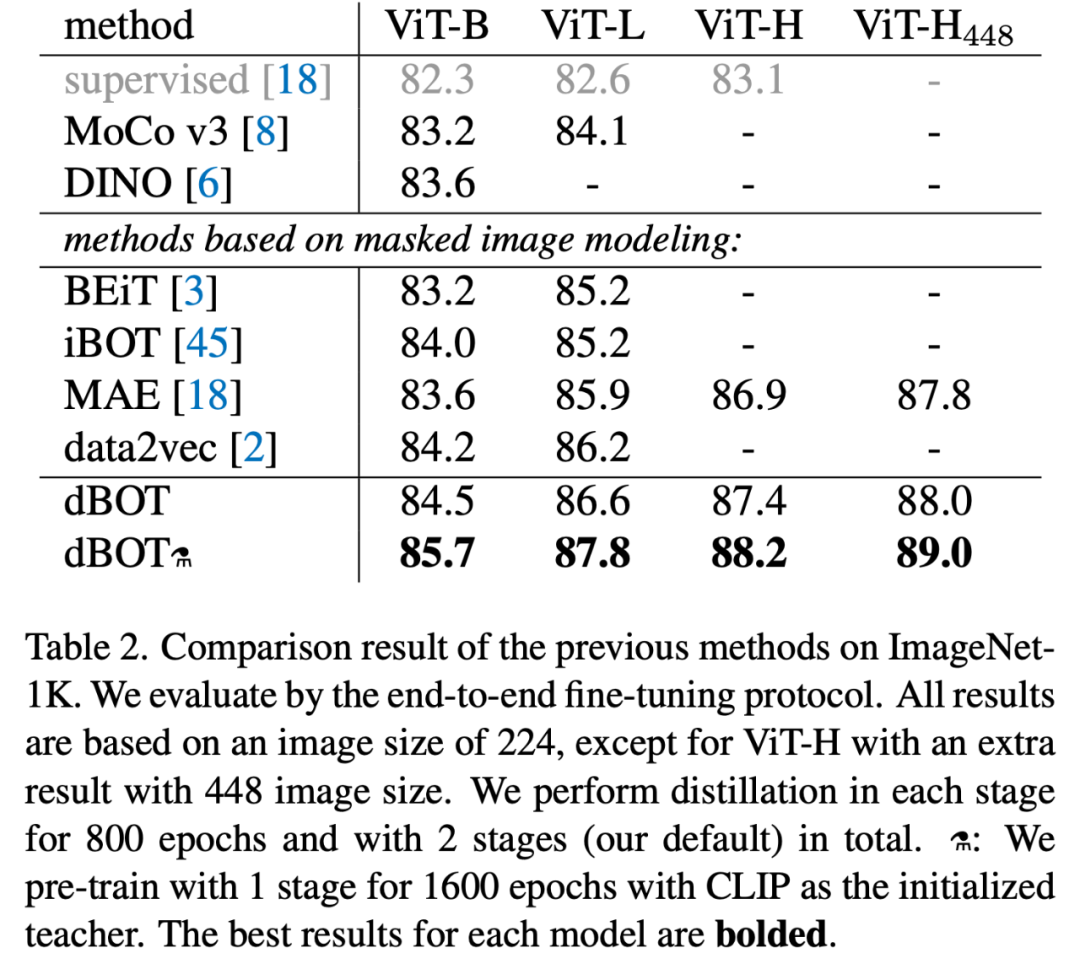
在微调分类上,dBOT 使用 ViT-H 达到了 89.0% 的精度,超越 MAE 1.2%。获得了在 ImageNet-1K 上的 SOTA 性能。
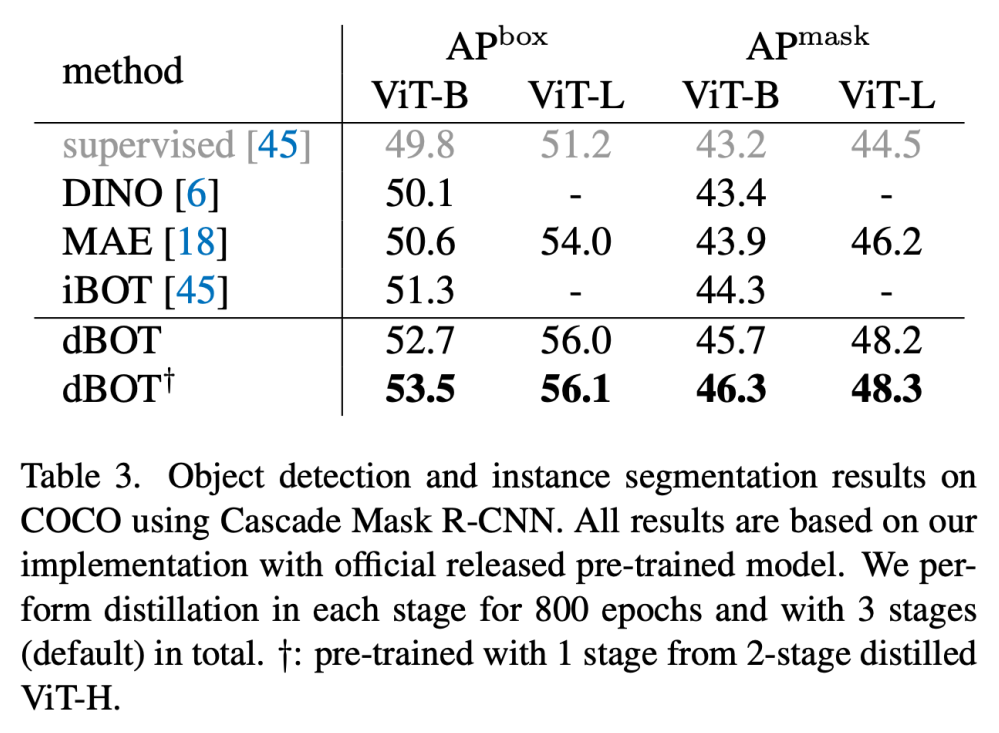
在目标检测、实例分割、语义分割等密集预测任务上,相同设置下 dBOT 的性能超越了之前的视觉预训练方法。相比于 MAE 有 2~3 个点的提升。这个提升是非常显著的。
除此之外,文章还使用更强的教师网络【结构上/数据上】来探究 dBOT 的上限和泛化性。
1. 首先选取比 student 参数量更大的 teacher 来进行掩码蒸馏,在三个任务上均获得了显著的提升:
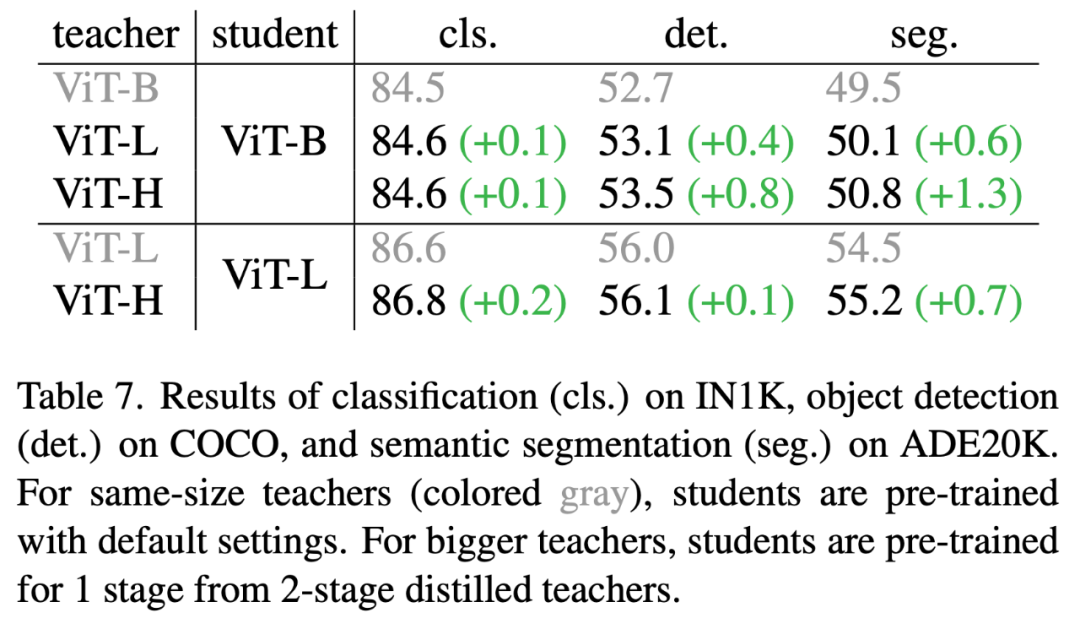
2. 其次选取在更大数据集训练的网络来作为 teacher 进行掩码蒸馏:
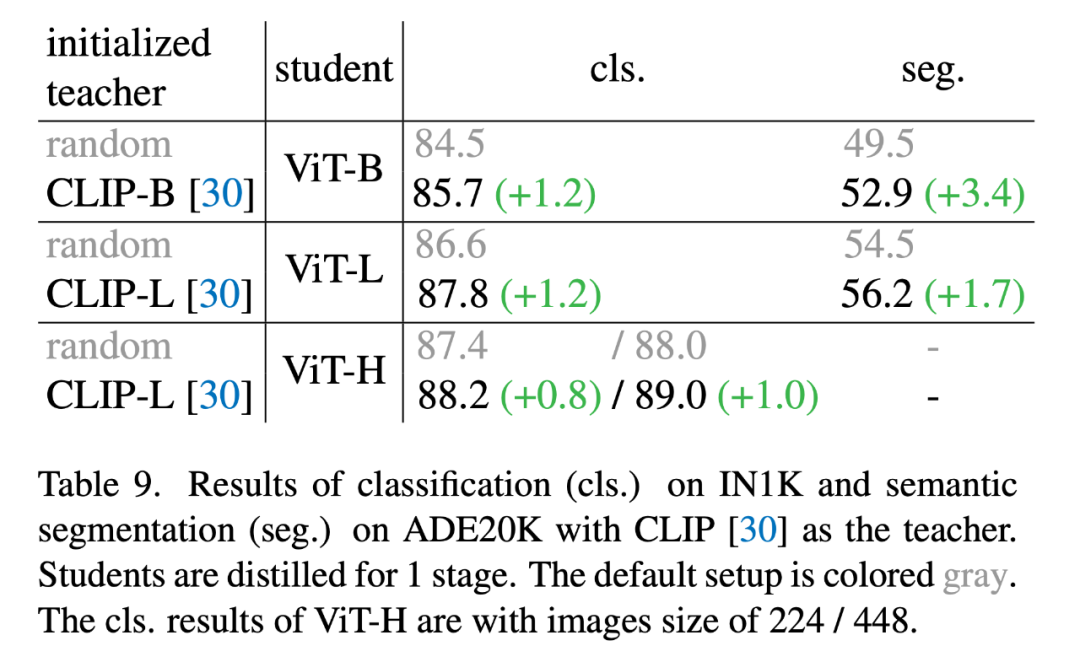
相比于使用参数量更大的网络作为 teacher,使用数据容量更大的网络作为teacher的效果更加显著。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢