

随着数据孤岛现象的出现和个人隐私保护的重视,集中学习的应用模式受到制约,而联邦学习作为一个分布式机器学习框架,可以在不泄露用户数据的前提下完成模型训练,从诞生之初就备受关注.伴随着联邦学习应用的推广,其安全性和隐私保护能力也开始受到质疑.本文对近年来国内外学者在联邦学习模型安全与隐私的研究成果进行了系统总结与分析.首先,介绍联邦学习的背景知识,明确其定义和工作流程,并分析存在的脆弱点.其次,分别对联邦学习存在的安全威胁和隐私风险进行系统分析和对比,并归纳总结现有的防护手段.最后,展望未来的研究挑战和方向.
http://www.jos.org.cn/jos/article/abstract/6658
近年来机器学习(machine learning)技术蓬勃发展,在社会工作生活各个领域中得到广泛应用,如人脸识别、 智慧医疗和自动驾驶等,并取得巨大的成功.机器学习的目标是从大量数据中学习到一个模型,训练后的模型可 以对新的未知数据预测结果,因此模型的性能与训练数据的数量和质量密切相关.传统的机器学习应用基本都 采取集中学习[1]的模式,即由服务提供商集中收集用户数据,在服务器或数据中心训练好模型后,将模型开放给 用户使用.但是,目前存在两大要素制约了集中学习的进一步推广:
(1) 数据孤岛
随着信息化、智能化进程的发展,各个企业或同一企业的各个部门都存储了大量的应用数据,但是数据的定义和组织方式都不尽相同,形成一座座相互独立且无法关联的“孤岛”,影响数据的流通和应用.数据集成整合 的难度和成本严重限制了集中学习的推广应用.
(2) 个人隐私保护的重视
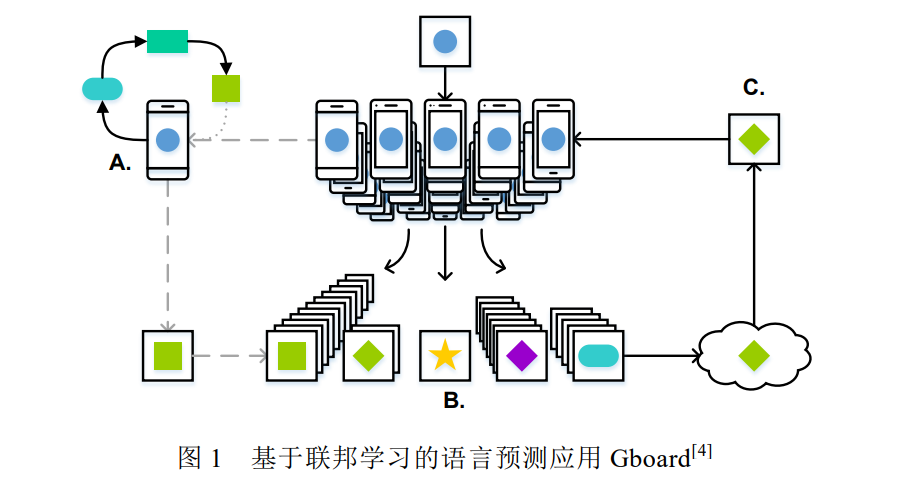
近年来,个人数据泄露的事件层出不层,如 2018 年 Facebook 数据泄露事件等.这些事件引起了国家和公众 对于个人隐私保护的关注.各个国家都开始出台数据隐私保护相关的法律法规,如欧盟 2018 年 5 月 25 日出台 的《通用数据保护条例》(General Data Protection Regulation,简称 GDPR) [2],以及中国 2017 年实施的《中华人 民共和国网络安全法》等.这些法律法规要求公司企业必须在用户同意的前提下才可以收集个人数据,且需要 防止用户数据泄露.此外,个人隐私保护意识的兴起也导致用户不愿轻易共享自己的隐私数据.严格的法律法规 和个人隐私保护意识导致训练数据的收集愈发困难,为集中学习提出了巨大的挑战. 为应对上述两个问题,联邦学习(federated learning)应运而生.联邦学习,又名联盟学习或联合学习,是一种 由多个客户端和一个聚合服务器参与的分布式机器学习架构.客户端既可以是个人的终端设备(如手机等),也 可以代表不同的部门或企业,它负责保存用户的个人数据或组织的私有数据.客户端在本地训练模型,并将训练 后的模型参数发送给聚合服务器.聚合服务器负责聚合部分或所有客户端的模型参数,将聚合后的模型同步到 客户端开始新一轮的训练.这种联合协作训练的方式可以在保证模型性能的前提下,避免个人数据的泄露,并有 效解决数据孤岛的问题. 联邦学习自 2016 年谷歌[3]提出后便引起学术界和工业界的强烈关注,并涌现出许多实际应用,如谷歌最初 将其应用在安卓手机上的 Gboard APP(the Google Keyboard,谷歌键盘输入系统),用于预测用户后续要输入的内 容(如图 1 所示) [4].用户手机从服务器下载预测模型,基于本地用户数据进行训练微调,并上传微调后的模型参 数,不断优化服务器的全局模型.此外,联邦学习也被广泛应用于工业[5,6]、医疗[7–11]和物联网[12]等领域.
随着联邦学习的发展应用,其安全性与隐私性逐渐引起学术界的关注.与集中学习相比,联邦学习的模型参 数共享和多方通信协作机制引入了新的攻击面.近年来,许多学者对联邦学习的安全威胁进行深入研究,提出一 系列攻击手段和防护方案.除安全性外,学者也发现联邦学习存在诸如成员推断攻击等隐性泄露的风险.这些将 严重影响联邦学习的实际部署应用,因此本文对目前联邦学习模型的安全与隐私研究工作进行系统地整理和 科学地归纳总结,分析联邦学习面临的安全隐私风险及挑战,为后续学者进行相关研究时提供指导.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢