
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:通用神经算法学习器、用于训练机器学习Potential的类药物分子和肽数据集、无提示的高效少样本学习、可行概率模型的连续混合、集成采样分析、Transformer时序应用综述、基于Transformer的多模态着色统一框架、语言模型指令微调以生成用于意图分类和槽标记的标注话语、浅层线性网络过拟合时深度线性网络可以良性过拟合
1、[LG] A Generalist Neural Algorithmic Learner
B Ibarz, V Kurin, G Papamakarios...
[DeepMind & University of Oxford & IDSIA & Mila & Purdue University]
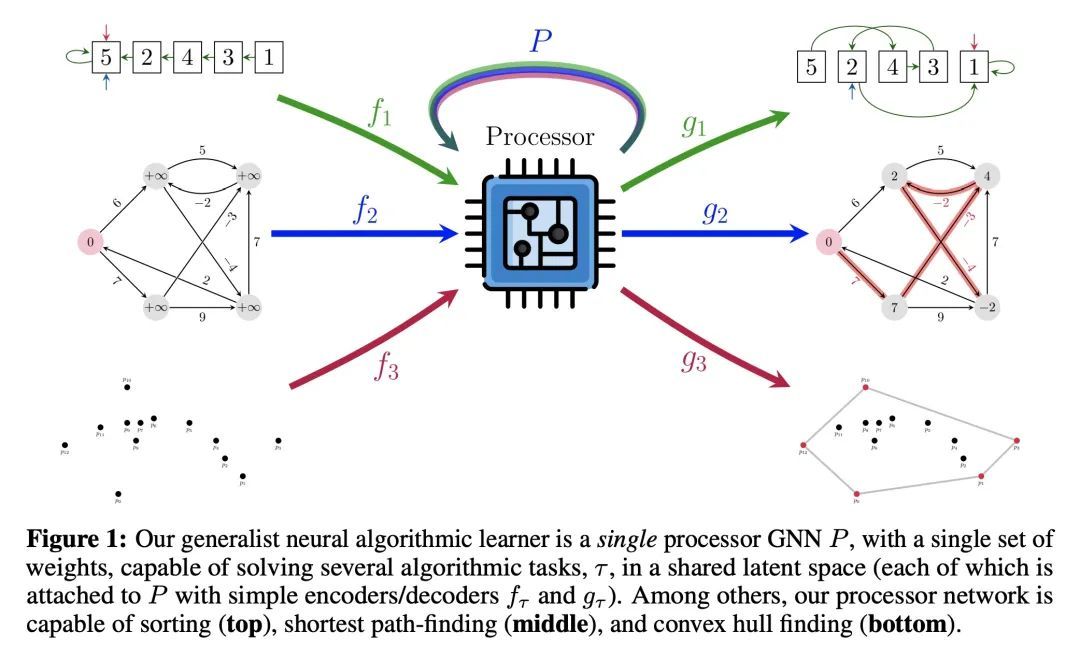
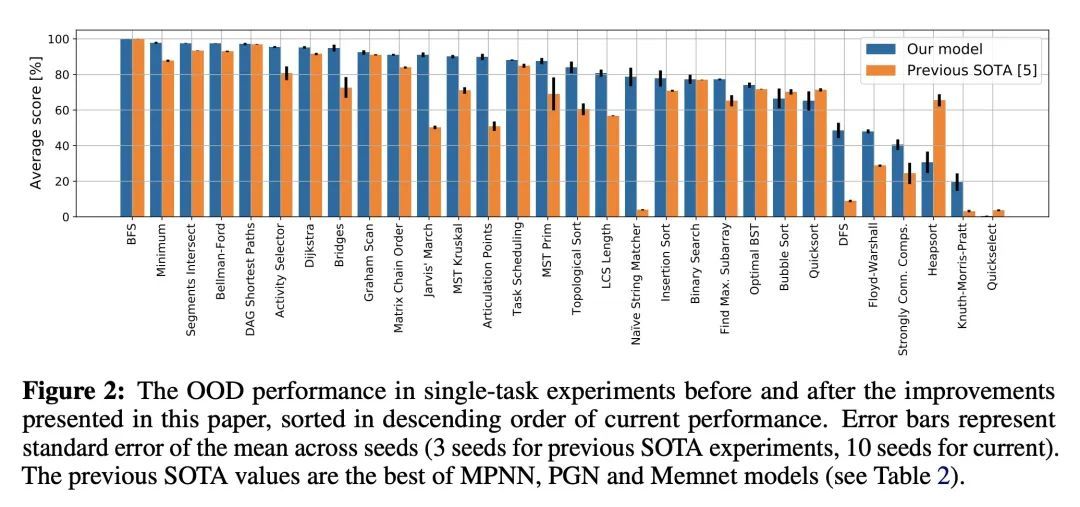
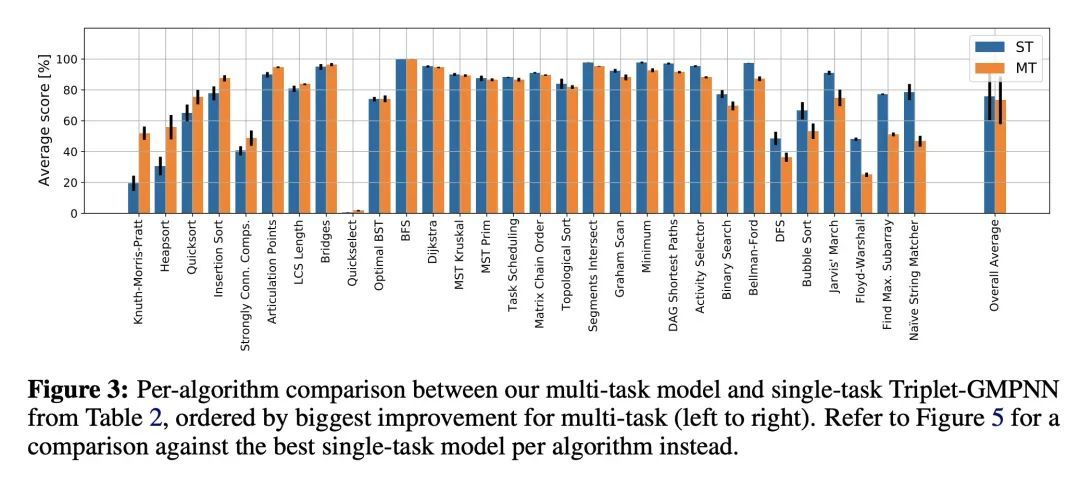
通用神经算法学习器。神经算法推理的基石是解决算法任务的能力,特别是以一种泛化出分布的方式。虽然近年来这一领域的方法学改进激增,但它们大多集中在建立专家模型上。专家模型能学习神经性地执行一种算法或具有相同控制流主干的算法集合。本文专注于构建一种通用的神经算法学习器——一种能学习执行各种算法的单一图神经网络处理器,如排序、搜索、动态规划、寻路和几何。利用CLRS基准,从经验上表明,就像最近在感知领域取得的成功一样,通用的算法学习器可以通过"纳入"知识来建立。也就是说,只要能学会在单任务系统中很好地执行算法,就有可能以多任务方式有效地学习算法。受此启发,本文对输入表示法、训练方案和处理器架构进行了一系列改进,与现有技术相比,平均单任务性能提高了20%以上。然后,利用这些改进,对多任务学习器进行了彻底的消融,结果表明,一种通用的学习器能有效地纳入专家模型所捕获的知识。
The cornerstone of neural algorithmic reasoning is the ability to solve algorithmic tasks, especially in a way that generalises out of distribution. While recent years have seen a surge in methodological improvements in this area, they mostly focused on building specialist models. Specialist models are capable of learning to neurally execute either only one algorithm or a collection of algorithms with identical control-flow backbone. Here, instead, we focus on constructing a generalist neural algorithmic learner—a single graph neural network processor capable of learning to execute a wide range of algorithms, such as sorting, searching, dynamic programming, path-finding and geometry. We leverage the CLRS benchmark to empirically show that, much like recent successes in the domain of perception, generalist algorithmic learners can be built by "incorporating" knowledge. That is, it is possible to effectively learn algorithms in a multi-task manner, so long as we can learn to execute them well in a single-task regime. Motivated by this, we present a series of improvements to the input representation, training regime and processor architecture over CLRS, improving average single-task performance by over 20% from prior art. We then conduct a thorough ablation of multi-task learners leveraging these improvements. Our results demonstrate a generalist learner that effectively incorporates knowledge captured by specialist models.
https://arxiv.org/abs/2209.11142

2、[LG] SPICE, A Dataset of Drug-like Molecules and Peptides for Training Machine Learning Potentials
P Eastman, P K Behara...
[Stanford University & University of California, Irvine & Open Molecular Software Foundation & ...]
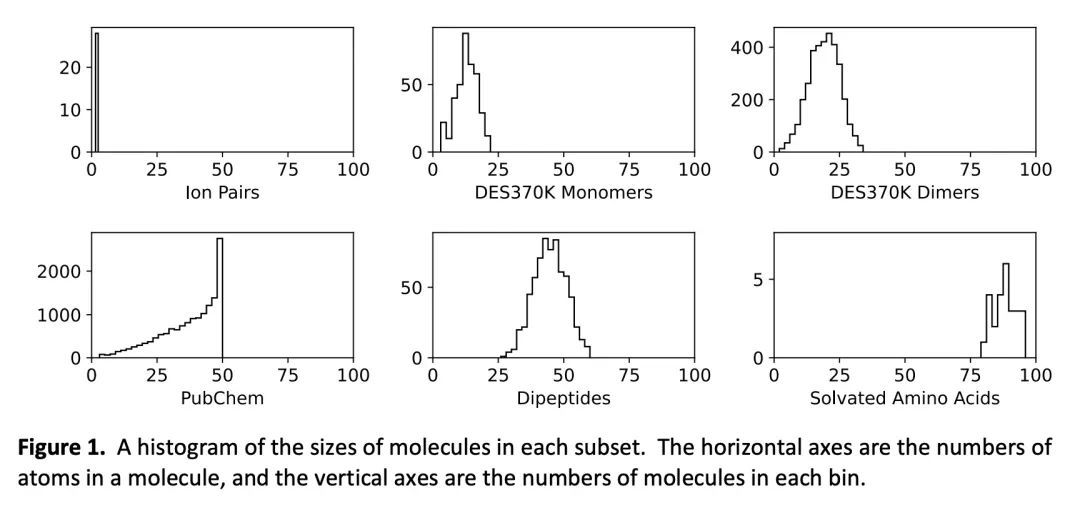
SPICE:用于训练机器学习Potential的类药物分子和肽数据集。机器学习Potential是分子仿真的重要工具,但由于缺乏高质量的数据集来训练它们,其发展受到阻碍。本文提出SPICE数据集,一种新的量子化学数据集,用于用Potential训练与模拟类似药物的小分子与蛋白质相互作用。它包含了超过110万个小分子、二聚体、二肽和溶解的氨基酸的构象。它包括15种元素,带电和不带电的分子,以及广泛的共价和非共价相互作用。它提供了在ωB97M-D3(BJ)/def2-TZVPPD理论水平上计算的力和能量,以及其他有用的量,如多极矩和键序。本文在上面训练了一套机器学习Potential,并证明其可以在化学空间的广泛区域内达到化学精度。SPICE作为一种宝贵的资源,可用于创建可迁移的、可直接使用的分子仿真Potential函数。
Machine learning potentials are an important tool for molecular simulation, but their development is held back by a shortage of high quality datasets to train them on. We describe the SPICE dataset, a new quantum chemistry dataset for training potentials relevant to simulating drug-like small molecules interacting with proteins. It contains over 1.1 million conformations for a diverse set of small molecules, dimers, dipeptides, and solvated amino acids. It includes 15 elements, charged and uncharged molecules, and a wide range of covalent and non-covalent interactions. It provides both forces and energies calculated at the ωB97M-D3(BJ)/def2-TZVPPD level of theory, along with other useful quantities such as multipole moments and bond orders. We train a set of machine learning potentials on it and demonstrate that they can achieve chemical accuracy across a broad region of chemical space. It can serve as a valuable resource for the creation of transferable, ready to use potential functions for use in molecular simulations.
https://arxiv.org/abs/2209.10702

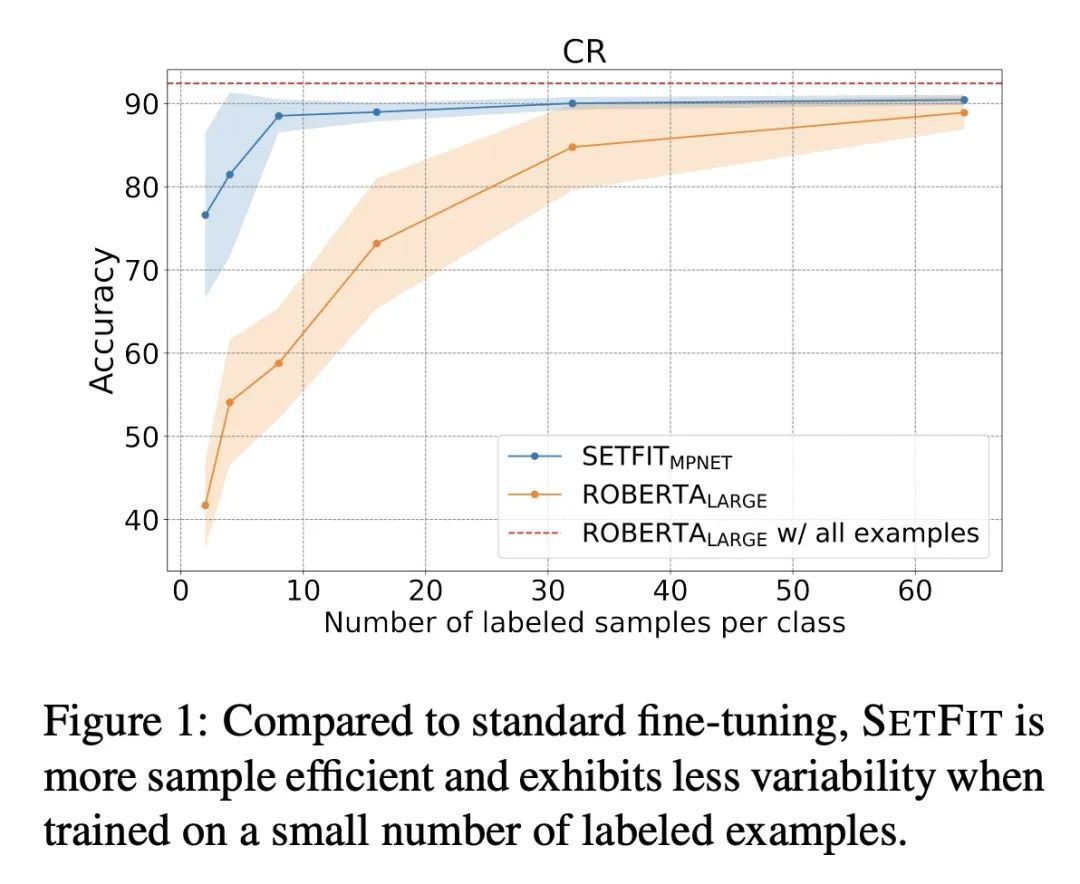
3、[CL] Efficient Few-Shot Learning Without Prompts
L Tunstall, N Reimers, U E S Jo...
[Hugging Face & cohere.ai & Technical University of Darmstadt & Intel Labs]
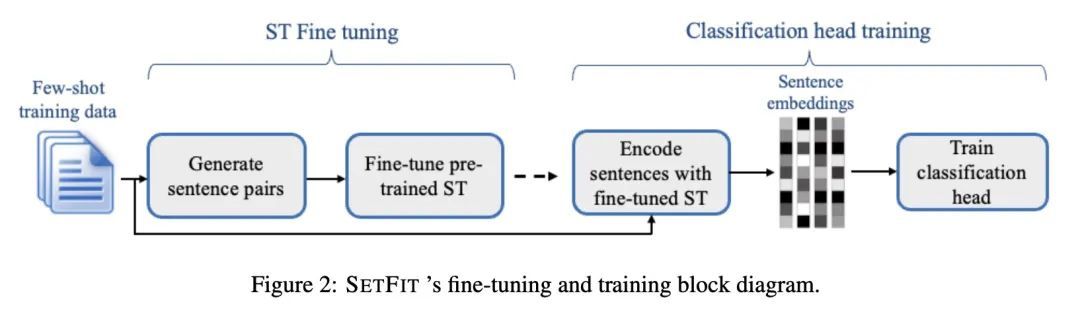
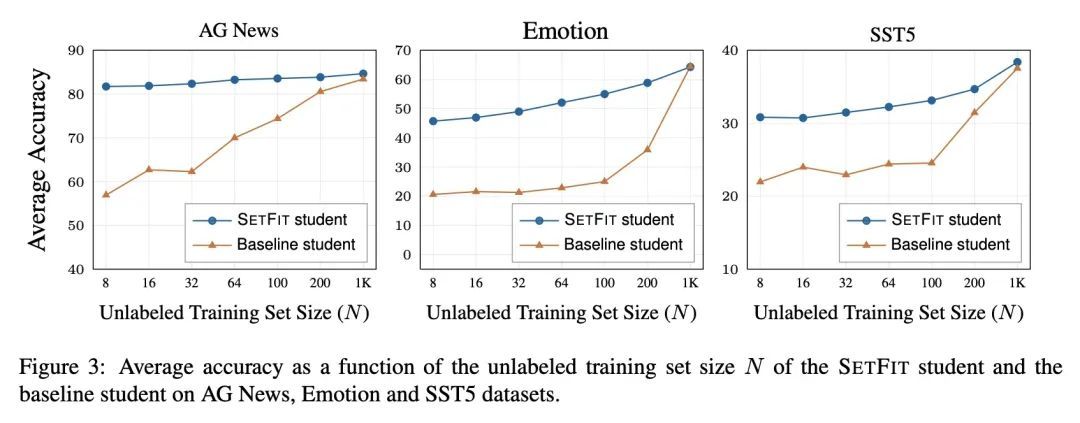
无提示的高效少样本学习。最近的一些方法,如参数高效微调(PEFT)和模式利用训练(PET),在标签稀缺的情况下取得了令人印象深刻的结果。然而,它们很难被采用,因为它们受制于手工生成的提示的高变化性,并且通常需要十亿个参数的语言模型来实现高精确度。为解决这些缺点,本文提出SETFIT(Sentence Transformer Finetuning),一种高效的、无提示的框架,用于对句子Transformer(ST)进行少样本微调。SETFIT的工作方式是首先在少量文本对上以对比Siamese的方式对预训练的ST进行微调。然后,产生的模型被用来生成丰富的文本嵌入,这些嵌入被用来训练一个分类头。该简单框架不需要任何提示或口头语,并且以比现有技术少几个数量级的参数实现了高精度。实验表明,SETFIT获得了与PEFT和PET技术相当的结果,同时其训练速度也快了一个数量级。SETFIT可以通过简单地切换ST主体而应用于多语言环境。
Recent few-shot methods, such as parameter efficient fine-tuning (PEFT) and pattern exploiting training (PET), have achieved impressive results in label-scarce settings. However, they are difficult to employ since they are subject to high variability from manually crafted prompts, and typically require billionparameter language models to achieve high accuracy. To address these shortcomings, we propose SETFIT (Sentence Transformer Finetuning), an efficient and prompt-free framework for few-shot fine-tuning of Sentence Transformers (ST). SETFIT works by first finetuning a pretrained ST on a small number of text pairs, in a contrastive Siamese manner. The resulting model is then used to generate rich text embeddings, which are used to train a classification head. This simple framework requires no prompts or verbalizers, and achieves high accuracy with orders of magnitude less parameters than existing techniques. Our experiments show that SETFIT obtains comparable results with PEFT and PET techniques, while being an order of magnitude faster to train. We also show that SETFIT can be applied in multilingual settings by simply switching the ST body. Our code1 and datasets2 are made publicly available.
https://arxiv.org/abs/2209.11055
4、[LG] Continuous Mixtures of Tractable Probabilistic Models
A H.C. Correia, G Gala, E Quaeghebeur, C d Campos, R Peharz
[Eindhoven University of Technology]
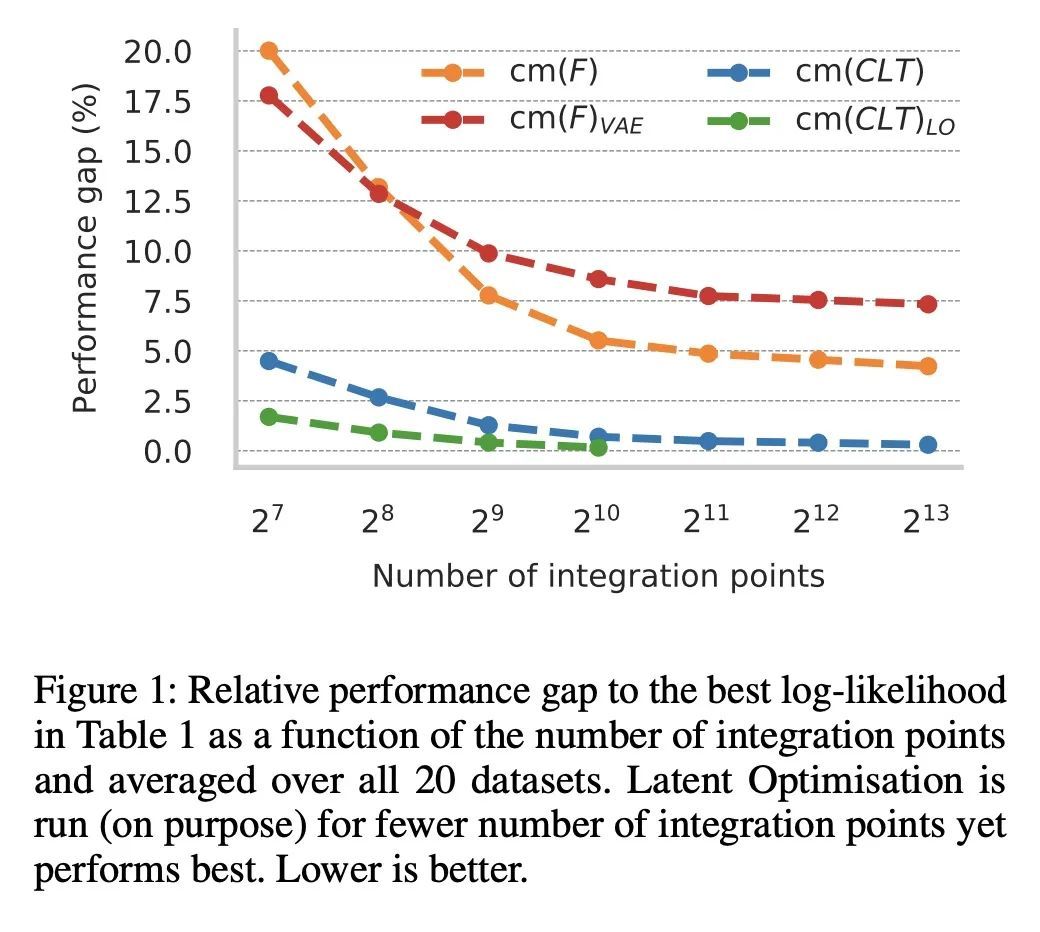
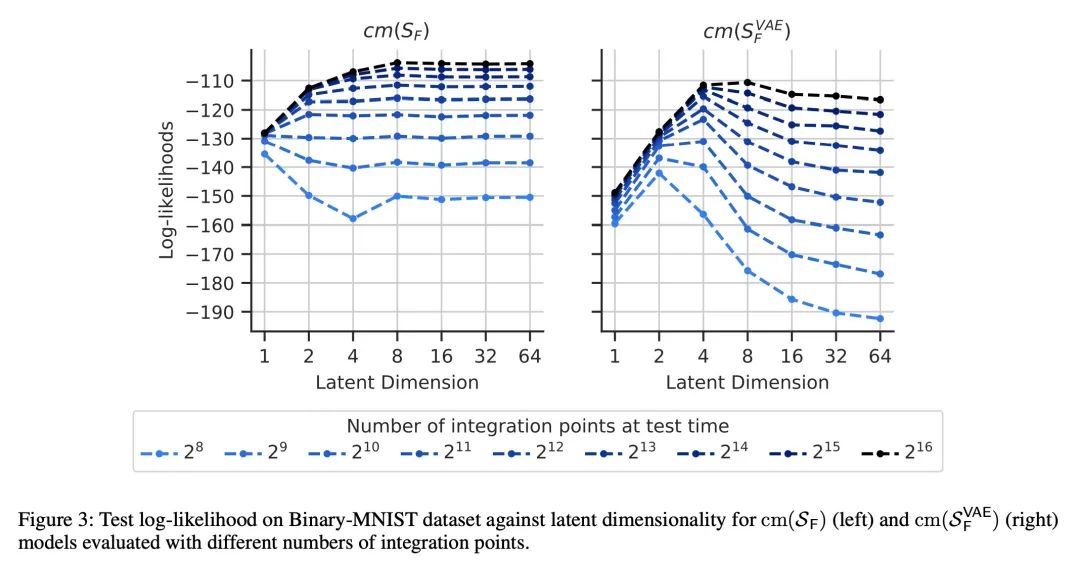
可行概率模型的连续混合。基于连续潜空间的概率模型,如变分自编码器,可以理解为不可数的混合模型,其中的成分连续地依赖于潜代码。其已证明是生成和概率建模的表达工具,但与可操作的概率推理不一致,即计算所代表的概率分布的边际和条件。同时,可操作的概率模型如概率电路(PC)可以被理解为分层的离散混合模型,这使得它们可以进行精确推理,但与连续的潜空间模型相比,其往往表现出不理想的性能。本文研究了一种混合方法,即具有小潜维度的可操作模型的连续混合。虽然这些模型在分析上是难以求解的,但很适合于基于有限积分点的数字积分方案。有了足够多的积分点,近似就变得事实上是精确的。此外,使用有限的积分点集,近似方法可以被编译成一个PC,执行"近似模型中的精确推理"。在实验中发现该简单方案被证明是非常有效的,因为以这种方式学习的PC在许多标准的密度估计基准上创造了新的最先进的可操作模型。
Probabilistic models based on continuous latent spaces, such as variational autoencoders, can be understood as uncountable mixture models where components depend continuously on the latent code. They have proven expressive tools for generative and probabilistic modelling, but are at odds with tractable probabilistic inference, that is, computing marginals and conditionals of the represented probability distribution. Meanwhile, tractable probabilistic models such as probabilistic circuits (PCs) can be understood as hierarchical discrete mixture models, which allows them to perform exact inference, but often they show subpar performance in comparison to continuous latent-space models. In this paper, we investigate a hybrid approach, namely continuous mixtures of tractable models with a small latent dimension. While these models are analytically intractable, they are well amenable to numerical integration schemes based on a finite set of integration points. With a large enough number of integration points the approximation becomes de-facto exact. Moreover, using a finite set of integration points, the approximation method can be compiled into a PC performing `exact inference in an approximate model'. In experiments, we show that this simple scheme proves remarkably effective, as PCs learned this way set new state-of-the-art for tractable models on many standard density estimation benchmarks.
https://arxiv.org/abs/2209.10584


5、[LG] An Analysis of Ensemble Sampling
C Qin, Z Wen, X Lu, B V Roy
[Columbia University & DeepMind]
集成采样分析。当维持模型参数的精确后验分布在计算上难以实现时,集成采样可以作为Thompson采样的实际近似方法。本文建立了一个贝叶斯遗憾约束,以确保当集成采样应用于线性bandit问题时的理想行为。这代表了对集成采样的第一个严格的遗憾分析,并且是通过利用信息论概念和新的分析技术来实现的,这些技术可能会在本文的范围之外证明是有用的。
Ensemble sampling serves as a practical approximation to Thompson sampling when maintaining an exact posterior distribution over model parameters is computationally intractable. In this paper, we establish a Bayesian regret bound that ensures desirable behavior when ensemble sampling is applied to the linear bandit problem. This represents the first rigorous regret analysis of ensemble sampling and is made possible by leveraging information-theoretic concepts and novel analytic techniques that may prove useful beyond the scope of this paper.
https://arxiv.org/abs/2203.01303

另外几篇值得关注的论文:
[LG] Transformers in Time Series: A Survey
Transformer时序应用综述
Q Wen, T Zhou, C Zhang, W Chen, Z Ma, J Yan, L Sun
[Alibaba Group & Shanghai Jiao Tong University]
https://arxiv.org/abs/2202.07125

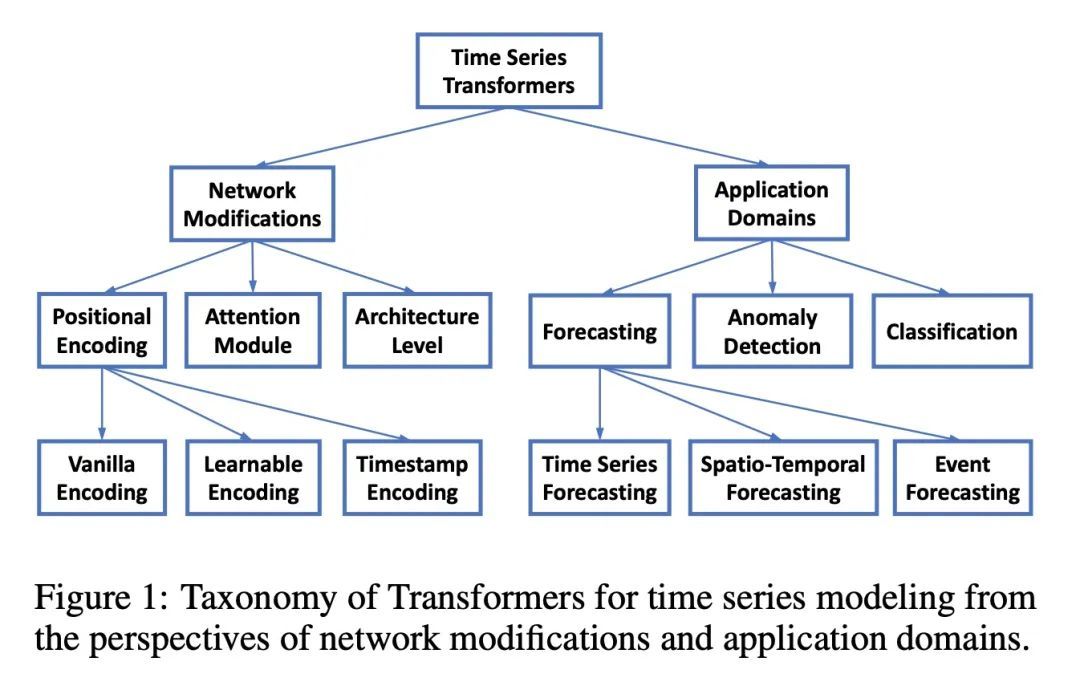
[CV] UniColor: A Unified Framework for Multi-Modal Colorization with Transformer
UniColor:基于Transformer的多模态着色统一框架
Z Huang, N Zhao, J Liao
[City University of Hong Kong & University of Bath]
https://arxiv.org/abs/2209.11223


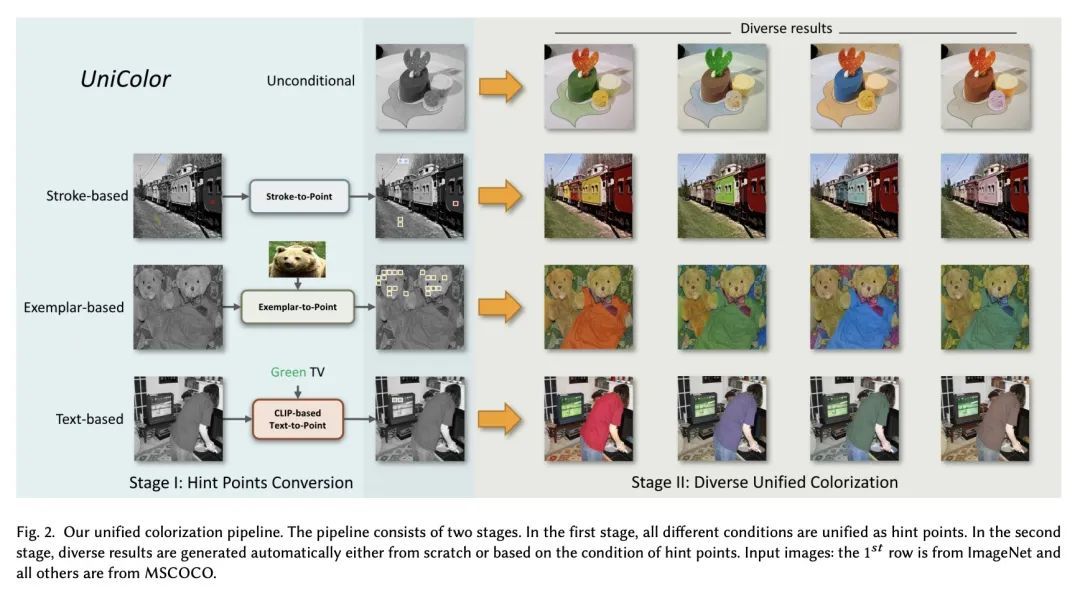
[CL] LINGUIST: Language Model Instruction Tuning to Generate Annotated Utterances for Intent Classification and Slot Tagging
LINGUIST:语言模型指令微调以生成用于意图分类和槽标记的标注话语
A Rosenbaum, S Soltan, W Hamza, Y Versley, M Boese
[Amazon]
https://arxiv.org/abs/2209.09900

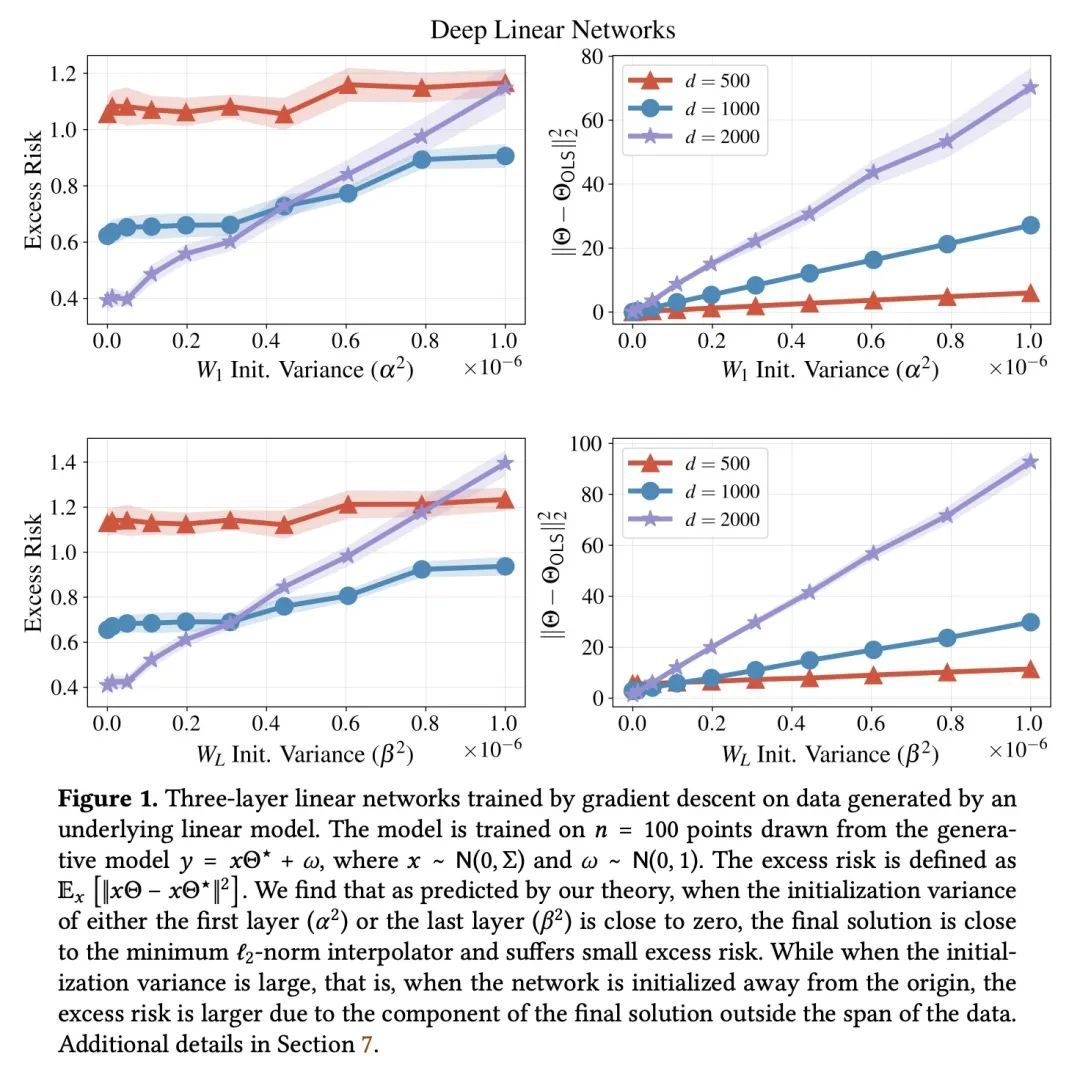
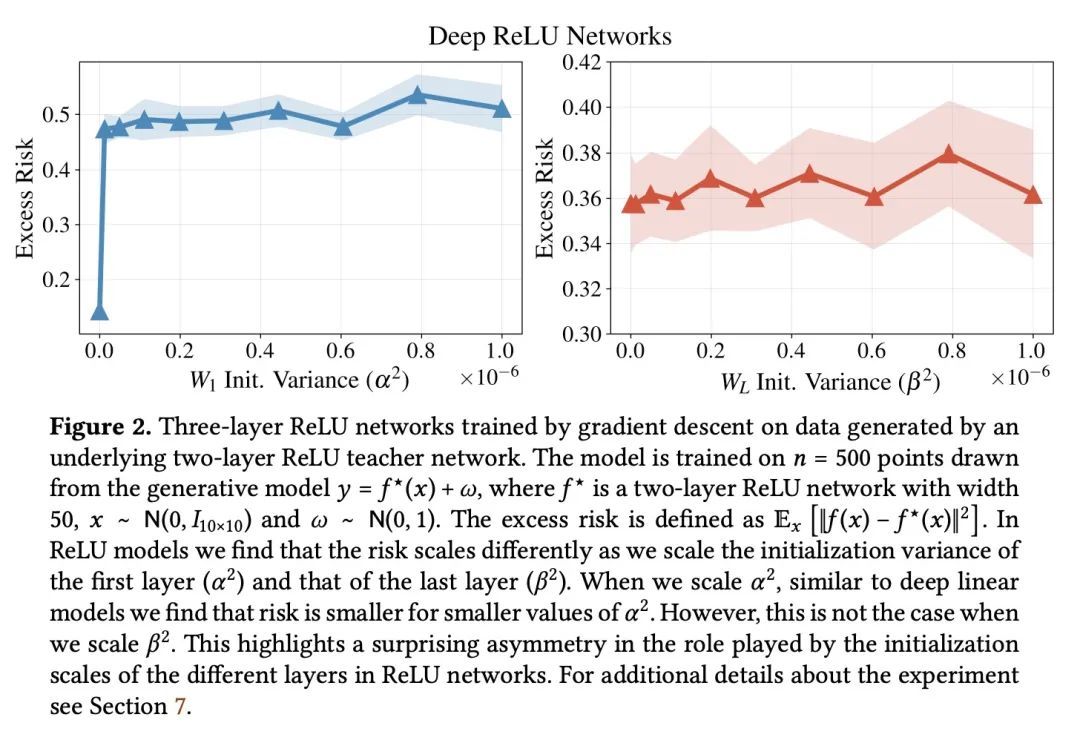
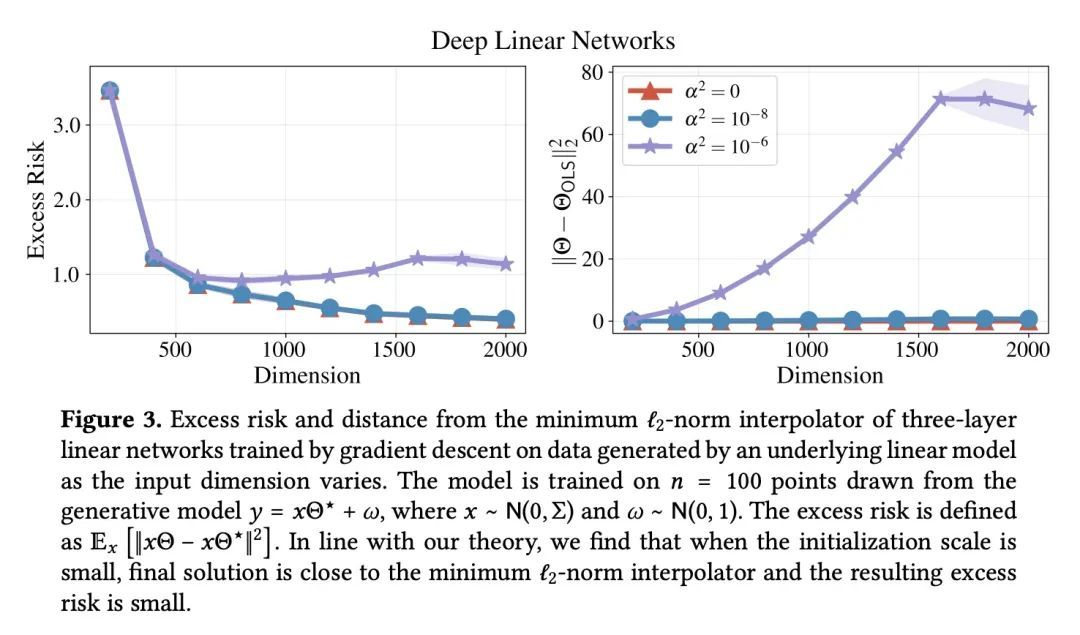
[LG] Deep Linear Networks can Benignly Overfit when Shallow Ones Do
浅层线性网络过拟合时深度线性网络可以良性过拟合
N S. Chatterji, P M. Long
[Stanford University & Google]
https://arxiv.org/abs/2209.09315

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢