

论文:https://arxiv.org/abs/2203.11654
代码:https://github.com/waxnkw/IETrans-SGG.pytorch
1. Scene Graph Generation介绍
Scene Graph Generation (SGG)旨在检测图像中的(主, 谓, 宾)三元组。如下图:
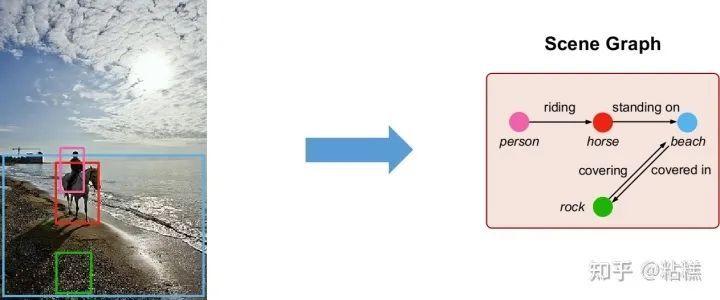
2. 问题
从效果来看,现有的SGG模型生成的场景图仅仅能在少数几个头部做出正确预测。以最常用的50类谓语分类(Predicate Classification)任务为例子,一个正常训练的Neural Motif模型仅仅能在21类上面做出正确预测。具体效果:
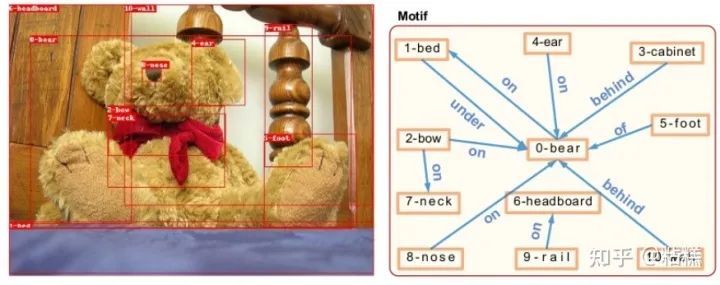
然而,类似于on,under这样的关系过于简单,很难为下游任务提供有用的信息。随便找一个caption模型都能达到类似甚至更好的效果。
所以,为什么效果如此拉垮?在本文中中,我们主要讨论了两个原因。第一个是老生常谈的长尾分布问题。在此不多加赘述。第二个则是我们想重点强调的一个问题 “标注冲突”。标注人员为了省力,在很多情况下会把riding on这样的细粒度关系标注为on这样的粗粒度关系。也就是说,一大批细粒度类别都被同时标注为了自己+粗粒度版本。
假设某个关系A,有1/2的数据被标注为了对应的粗粒度类别B。这就意味着,对于A这个类别在训练时,会有一半的时间认为A是对的,另一半时间认为B是对的。 这种情况下,即便加了reweighting,rebalancing之类的方法,也无法改变模型在冲突的标注上搞优化这一事实。 这也就是我们说的属于SGG模型的 “精神内耗”。
3. 方法
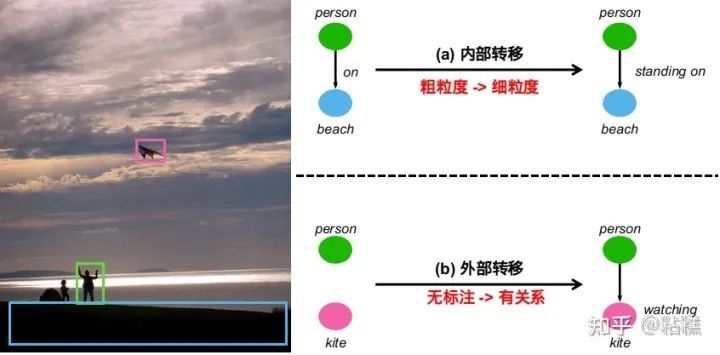
既然所有问题都来源于数据,我们的方法就是直接修改标注数据。首先对于粗粒度和细粒度的标注冲突,我们会从粗粒度往对应的细粒度转移数据。此外,SGG数据集还有一个特点,就是partially labeled。很多无标注的物体对,并不是没有关系,而是漏标了。所以我们不光可以从粗粒度到细粒度转移数据,还可以从无标注到有标注转移数据来做尾部数据的数据增强。
3.1 内部转移
我们通过在训练集上inference一个训练好的模型发现:即便在训练集上,细粒度的关系也会非常容易被对应的粗粒度关系打败。比如在下图中,所有被标注为(man, riding, motorcycle)的数据预测得分最高的并不是riding,而是on。
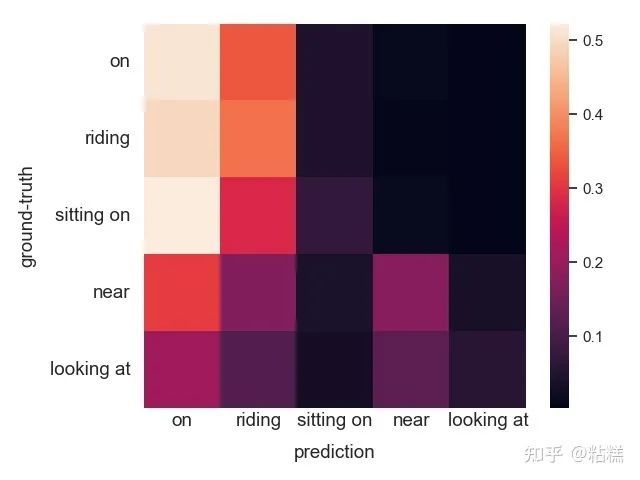
这恰好给我们提供了一个切入点。我们会在训练集上发现这些易混淆的谓语对,比如riding和on。更严谨一点,给定一类关系三元组(比如,man riding motorcycle),我们会在训练集上收集所有该类型的数据,然后用训练过的SGG模型打分。如果某些预测关系比Ground-Truth的标注得分还要高,我们则认为这些关系对于我们的Ground-Truth关系来说是易混淆的关系。
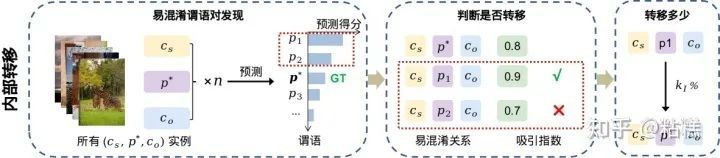
但是,易混淆并不意味着就是粗粒度-细粒度关系。所以,我们通过定义了一个吸引指数来进一步判断他们是否构成一个合格的粗粒度-细粒度关系对。具体细节可以参照论文。最后,我们简单粗暴的从粗粒度关系向细粒度关系转移了 kIk_I%k_I% %的数据。
3.2 外部转移
外部转移大致上follow了我们之前的Visual Distant Supervision(https://zhuanlan.zhihu.com/p/452391206)的形式。基本的想法是对未标注+bounding box有重叠的object pair用模型重新打分,选取其中最可能有关系的前 kEk_Ek_E %数据转移为有标注数据。同时为了更专注于尾部数据,我们仅仅对前15类之外的类别做增强。
最后两部分增强的数据,我们会直接组合起来作为一个增强数据集。
4. 新数据集
我们总共验证了两个benchmark。一个是最常用的50类关系的VG数据集,为了方便,我们在论文中简称VG-50 (其他论文里也有叫VG-150, VG-200的)。此外,我们还为大规模的关系检测专门划分了一个新的benchmark VG-1800。
更可靠! VG-1800旨在为大规模关系检测的评测服务。我们手动过滤掉了不合理的关系,比如一些拼写错误,名词,形容词。此外,通过观察过之前基于VG的大规模SGG数据集(VG8K,VG8K-LT),我们发现很多关系只存在于训练集,测试集一个也没有,或者测试集仅仅有一个两个。考虑到这一点,我们确保了测试集上每一种关系至少5个sample,训练集上每种关系至少1个sample。
更丰富!VG1800包含了更加丰富的关系类别:
| (car, pulled by, engine) | (car, driving alongside, road) | (horse, possesses, leg) |
| (train, switching, track) | (wave, breaking in, wave) | (horse, galloping on, beach) |
| (window, on exterior of, house) | (cloud, floating through, sky) | (window, at top of, tower ) |
更有挑战! 首先,在VG1800中,之前提及的长尾部分和标注问题带来的优化冲突变得更为严重。这也导致现有的resampling和reweighting会比较难用。如果有小伙伴仔细看了论文,可能会发现我们在VG50中应用了reweighting来做方法增强,但在VG1800上面却没有采用。这是由于VG1800过于悬殊的头尾类别数量导致常规的reweighting factor难以work。一些常规的 1/freq1/freq1/freq 或者 1/freq\sqrt{1/freq}\sqrt{1/freq} 会直接导致模型过于关注于标注稀疏且高噪音的尾部类别,从而使得模型的识别能力大幅度下降,严重情况下甚至不收敛。但如果猛调reweighting factor的temperature可能又会造成低效。
5. 实验
在VG-50上,我们验证了方法的通用性+有效性。
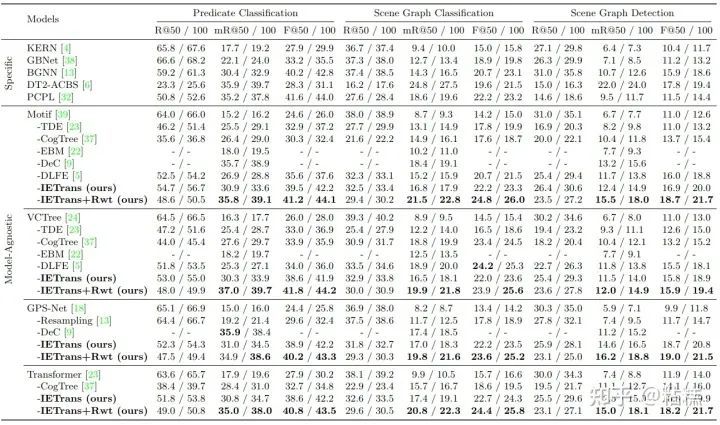
可以看出我们的方法可以比较有效的提升mR指标。
在VG-1800上面,我们进一步验证了我们方法的效果。
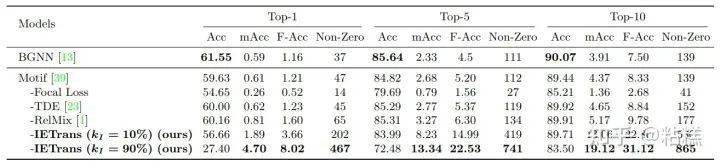
当别人只能做出37个正确预测的时候,我们可以做出467个正确预测。
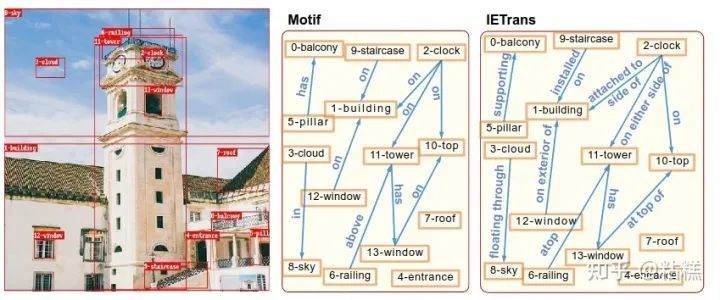
具体到实际效果,我们的模型可以说出更多样的关系类型:
6. 展望未来
现在来到了胡扯环节。。。
展望一下未来,简单讨论一下我自己觉得比较有意思的一些未来方向。
场景图生成这个任务作为一个检测任务,我觉得可以搞的地方无非就是两点:定位+分类。我下面会从方法层面和任务层面重点讨论一下分类方面。
6.1 方法层面
我觉得数据为中心的方法创新是一个非常有前景的方向。我们这里以SGG中存在的标注问题为例子。首先,我们可以把这些标注问题划分为两类:一类是partially label,另一类是noisy label。其中partially label指的是标签标注不全。 比如我们提到的标注冲突,其实就是指在SGG这个多标签分类任务中只标注了部分单标签。内部转移也就是为粗粒度标签标注部分扩展出漏标的细粒度标签,然后使用更重要的细粒度标签做监督。而我们的外部转移则是尝试利用NA数据中漏标的部分。Noisy label则主要指标注错误。 对于VG这样一个巨大的数据集,其中其实包含了大量的标注噪音。比如错误的关系标注;很多物体被重复标注了多个bounding box。
数据上的特点(充足+标注问题+长尾)+评价指标(重视mR)选取其实也为我们做research带来了一点好处:那就是SGG任务难以被预训练模型直接刷爆。我相信很多做VL多模态的同学都会发现,当各种大模型(e.g. BEIT v3)横空出世之后,似乎VL相关的榜单(e.g. VQA)已经没有非预训练模型的位置了。但是对于视觉关系检测来说,预训练模型(我们试过finetune VinVL)确实可以带来一定的增益,比如PREDCLS上mR@100从17、18->20。但显然20这个performance,还不如加一个reweighting来缓解长尾分布管用。
其次,数据层面的方法创新和之前方法一定程度上是正交的。数据层面的方法创新不光可以辅助不同模型,还可以进一步装备分布调整的方法,比如reweighting。这极大程度的避免了,别人出了新模型,我就不是SOTA的尴尬状况。此外,这个方向刚刚还比较稚嫩,会比较容易做出改进。比如,我们的内部转移就是非常粗暴的对所有类别定了一个百分比来做转移,看起来毫无技术含量。。。
最后,这些数据层面的方法创新是可以扩展到其他VL领域的。 就近来说,我们可以探索其他大规模检测任务中的partially label+noisy label问题,比如LVIS数据集的大规模Instance Segmentation。往远了说,VQA当中一样存在着严重的partially label问题。当我们问大海里有多少水。显然a lot of,lots of,much都是表达一样的意思,但我们往往只能标注出一小部分。插一个现象,这种高度partially labeled数据,我们甚至难以过拟合(VG训练终止时train set准确率<75%)。再远一点,我们考可以虑VL预训练。一个很好的例子就是BLIP,BLIP通过进一步清洁数据取得了很好的效果。
6.2 任务层面
我认为一个好的任务起码需要具备两个特点,一个是有用,一个是能提供丰富的工作岗位。
首先从有用角度来讲, 我觉得现有SGG在两点上有比较大的欠缺,一个是精准,一个是细粒度。精准指的是精准的定位+正确的分类。以精准的定位为例子,我觉得最近的Panoptic Scene Graph Generation就是一个很好的扩展。这里我们不多加赘述。
我们主要想分析一下细粒度。其实图像中显著物体粗粒度的物体+关系,用预训练模型已经可以做的相当好了。我们只要搞个模型生成一下caption很大程度上就足够cover了。那为什么我们还要继续做SGG呢?我认为,SGG必须要做到预训练模型做不到的东西,而超级细粒度的分类就是一个选项。我们要让SGG模型去说出预训练模型说不出的词汇。当预训练模型只能说"cloud in the sky","toy on the table",我们可以说出(cloud, floating through, sky),(teddy bear, sitting on, dining table)。我还要让SGG模型去检测被预训练模型忽视的关系(非显著区域) 。比如,当我们面对下图提问问兔子手里拿的是什么时?预训练模型(OFA-base)会倾向于回答梳子,但如果我们可以检测到(兔子,拿着,篮子)这样的关系,就可以很大程度避免预训练模型犯错误。所以我们本文当中非常认真的搞了一个大规模SGG的VG-1800 benchmark。

其次,我认为大规模的细粒度的SGG可以提供很多工作岗位,也就是有很多东西可以(平民化的)做。最简单的,可以参考6.1中提及的数据问题,去搞一些数据为中心的方法创新。此外,按照我们6.1中分析的,大规模细粒度SGG难以被预训练模型直接替代,但这恰好提供给我们去做定制化adaption的机会。VG-1800当中有大量的关系只有个位数级别的标注数据,无论数据如何増广都难以达到很好的效果。于是,借助预训练模型去做一些prompt之类的方法就成了一个比较有有意思的搞法。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢