
Introduction
近年来,基于通用信息抽取(UIE)的范式在学术届、工业界引起了广泛的关注,一系列相关的顶会文章涌现出来 [1,2,3,4,5,6,7,8,9],涉及 信息抽取、问答、对话、分类、匹配、文本生成等不同的 NLP tasks。
工业界也随之推出了相关的比赛如 CCKS22 通用信息抽取比赛 [10]、电力行业多模式知识图谱抽取 [11],这些比赛涉及通用、垂直场景以及多资源、少资源等抽取任务,为 UIE 在实践中的应用提供了充分的 benchmark。笔者及所在团队参加了这两个比赛,并取得了不错的成果:
- CCKS22 通用信息抽取技术创新奖 [10,12,14]
- 电力抽取比赛选拔赛、决赛模型得分 TOP1 [11,15],总分 TOP2 [28](决赛模型分 85.54,总分 8 5.48(TOP1 总分 85.57),非电力行业背景)
注:总分=0.9*决赛模型分+0.1*文档分并摸索出了一个实践中应用 UIE 的最佳实践路径。本文主要介绍了我们在 UIE 比赛中提出的 UniLM-UIE 模型以及通用训练方案具体细节,以及在比赛中尝试过有效、无效的训练策略。为大家在实际问题中应用 UIE 提供一份经过实战检验的参考。
UniLM-UIE2.1 UniLM
我们提出了基于 UniLM [13] 的 UIE 框架。UniLM 是微软提出的一个基于 decoder-only 的 unified LM,通过修改不同的 attention mask 实现双向、因果、seq2seq 等不同语言模型等建模,适配 NLU、unconditional generation(GPT)以及 conditional generatio(Seq2Seq)。这里,我们使用 UniLM 主要基于以下几点:
- Decoder-only 相比 Seq2Seq,降低了模型复杂度
- 相比 Seq2Seq,Decoder-only 可以实现更大的基础模型如 GPE-MOE [16]、GLM [17]
UniLM 的基本原理如下:
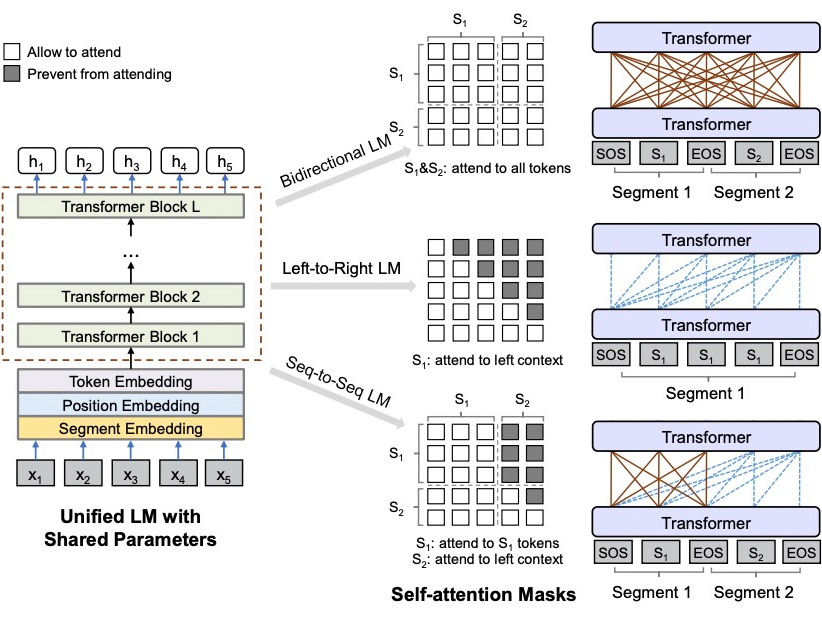
通过控制不同的 attention mask,实现一个模型完成多种 NLP 任务如 NLU、LM、Seq2Seq 等。在信息抽取场景中,通常会给定一个文本、对应的 schema,然后输出目标序列,其形式与 Seq2Seq 类似。所以,在我们的 UniLM-UIE 中,使用了 Seq2Seq attention mask 即输入双向建模,输出单向建模,实现了条件生成。
UniLM-Seq2Seq 模型的训练则相对比较简单,输入序列包含 条件输入+输出序列,attention mask 根据输入、输出序列构建即可。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢