

论文链接:https://arxiv.org/abs/2206.12808
代码链接:https://github.com/ICTMCG/M3FEND
导读
广泛传播的假新闻同时威胁到个人和社会,引发媒体信任危机。现在有大量研究集中在单领域虚假新闻检测(例如财经、健康)。然而,不同领域新闻之间通常存在内在联系,同时建模多个新闻领域的信息有助于提升整体的检测效果。基于我们的分析,我们指出多领域虚假新闻检测中的两个挑战:
- 领域偏移,由于不同领域间用词、情感、风格存在差异。
- 领域标签不完整,实践中一则新闻只会在一个领域发布,领域标签唯一,而事实上一则新闻包含的话题非常多样,同时和多个领域存在关联。
为应对上述挑战,我们提出了记忆引导的多视图多领域虚假新闻检测框架(M3FEND)。具体地,我们首先从语义、情感、风格等多个视图建模新闻(Multi-View Extractor),用于获取丰富的新闻表征。为动态存储领域信息并建模领域特质,我们设计了领域记忆库(Domain Memory Bank)。基于该模块,M3FEND可以利用已出现过的样本生成新闻的潜在领域标签。以领域记忆库读出的领域信息作为参考,领域适配器(Domain Adapter)可以自适应地从多个视图聚合有用信息。离线和在线实验均证明了M3FEND的有效性。
贡献
最近几年,越来越多的人通过在线社交媒体获取新闻资讯。然而由于这些在线社交媒体发布资讯非常便捷,以及没有非常严格的审核,假新闻也得以广泛传播。如此广泛传播的虚假新闻严重地威胁到了个人和社会。因此,自动虚假新闻检测系统对于增强在线新闻生态的可信度非常重要。
一个新闻平台每天可能发布上百万条不同领域的新闻,比如金融、政治、健康,如图1所示。然而大部分现有的方法关注于单个领域的虚假新闻检测。事实上,不同领域的新闻通常存在内在关联,如图1(b)和(c)的新闻来自不同领域,但都是关于新冠的。直觉上,同时建模多个相关的新闻领域可以提升虚假新闻检测的效果。
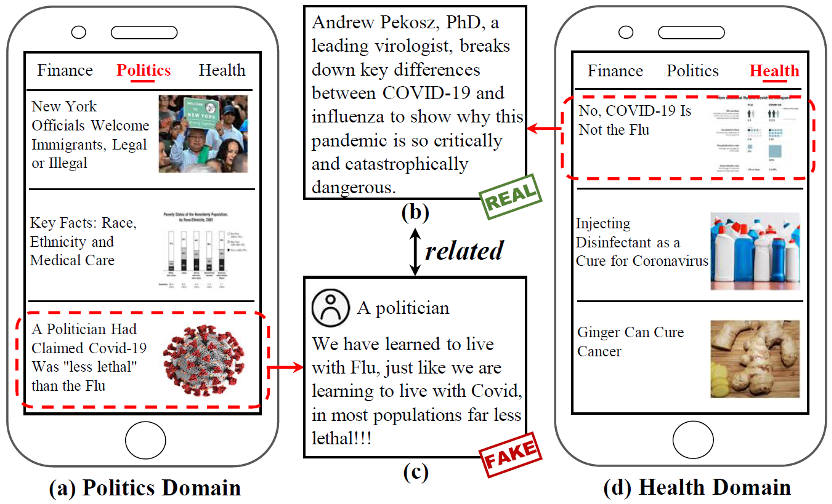
图1 真实新闻平台
在本工作中,我们首先分析了多领域新闻数据,并且发现多领域虚假新闻检测面临两个挑战:
- 多个新闻领域间的领域偏移。新闻领域间存在显著的领域差异,比如用词、情感、风格。图1展示了健康和政治领域的话题不同。此外如图2所示,不同领域的写作风格,用词,发布者情感都存在巨大差异,这种差异也被称作领域偏移(domain shift)。通常来说,领域偏移会严重影响联合训练多个领域数据的效率。因此,有必要提出多领域模型来缓解这个问题。
- 新闻的领域标签不完整。在一个真实新闻平台,一条新闻通常只在一个领域发布。然而,一条新闻通常混杂着多样的话题,使得它和多个领域存在关联。如图1,新闻(c)被分到政治领域,但是它也和健康的话题有关。此外,我们还分析发现新闻领域的领域边界并不明显,这也表明一条新闻可能和多个领域相关。领域标签对于多领域学习非常有用,因此补全领域标签对于多领域虚假新闻检测系统很重要。
为了解决上述的问题,我们提出了一个新的记忆引导的多视图多领域虚假新闻检测框架(M3FEND)。由于不同领域新闻的用词、风格和情感都存在差异,我们首先使用三个多通道网络来从语义、情感、风格三个视图建模新闻。由于跨视图的交互可以抓获视图间的联系以及产生更多样化的视图组合,对于建模领域差异非常有用。因此我们提出了多头自适应跨视图交互器(Multi-Head Adaptive Cross-View Interactor) 来自适应地学习多样化的跨视图交互。注意,不同领域的可判别的跨视图交互是存在差异的,因此我们提出领域适配器,以领域信息作为输入自适应聚合可判别的跨视图表示。
为了补全领域标签以及丰富领域信息,我们提出了领域记忆库(Domain Memory Bank),包含一个领域特质记忆和多个领域事件记忆。领域特质记忆旨在自动抓获以及储存领域特质信息。此外,每个领域都有一个领域事件记忆矩阵,记录这个领域发布的所有新闻。每个领域事件记忆矩阵包含多个记忆单元,每个记忆单元表示着一类相似的新闻。然后,我们计算领域事件记忆矩阵和一条新闻间的相似度。相似度可以表示领域标签的潜在分布,我们使用该相似度分布来丰富领域信息。丰富后的领域信息被用来指导领域适配器聚合跨视图的表示。
我们在中英文数据集上均测试了M3FEND的效果,此外该方法已经部署到了我们的在线虚假新闻检测系统(睿鉴识谣)。本工作的贡献如下:
- 我们调研了多领域虚假新闻检测问题,并指出其中的两个挑战:领域偏移和领域标签不完整。
- 为了解决上述挑战,我们提出了一种新的记忆引导的多视图多领域虚假新闻检测框架,这个框架可以提升大多数领域的虚假新闻检测效果。
- 我们做了离线和线上实验来验证我们的框架的有效性。
方法
1. 领域偏移

图2 (a) 9个领域top20词 (b)风格特征 (c)情感特征
我们分析了不同新闻领域的词频分布、风格特征、发布者情感特征,如图2所示。可以看到不同领域的可判别特征不同,进一步验证了领域偏移的问题。
2. 领域标签不完整

图3 基于中文数据集的t-SNE图
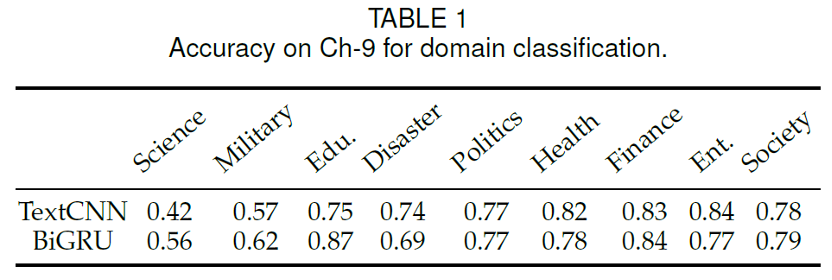
我们基于数据训练一个模型对领域标签进行分类,可视化了特征的t-SNE图,可以看到不同领域的领域边界并不清晰。此外我们列出了分类准确率,如表1所示,可以看到,每个领域的分类准确率也较低。验证了领域标签不完整的问题。
3. 模型
该方法共包含三个部分,首先是多视图表示提取,主要包括提取语义、风格、情感表示,以及进行跨视图交互,提取到多个跨视图表示;其次是记忆模块,包括领域特质记忆以及领域事件记忆,领域特质记忆针对每个领域学习一个向量表示,表示该领域的特质,而领域事件记忆包含写入和查询操作,存储着每个领域的事件;最后是领域适配器,以领域记忆模块的输出作为输入,输出不同跨视图表示的权重,进行聚合,送入最后的多层感知机预测该消息的真假。图4展示了本方案的整体流程。
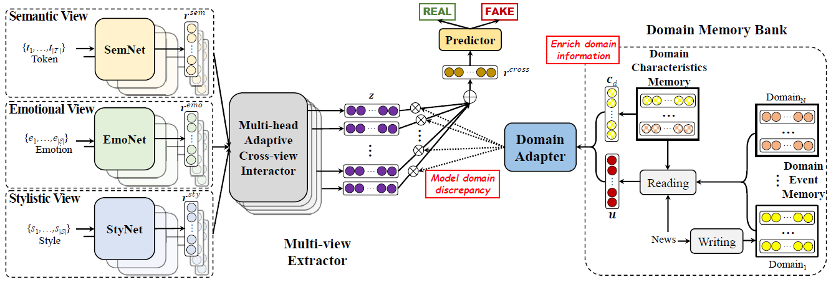
图4 M3FEND整体框架
3.1 多视图提取
给定一条待测消息 PP 。 PP 包含新闻内容(词)\( \mathcal{T} = \{t_1, ..., t_{|\mathcal{T}|}\} \) ,提取到的情感特征\( \mathcal{E}=\{e_1, ..., e_{|\mathcal{E}|}\} \),风格特征 \( \mathcal{S}=\{s_1, ..., s_{|\mathcal{S}|}\} \) 。我们首先提取多视图的表示,为了更充分地提取信息,再建模跨视图的表示。
多视图抽取。 本方案首先使用TextCNN提取语义表示,用多层感知机提取情感表示和风格表示:
\( r^{sem} = \text{SemNet}(\{t_1, ..., t_{|\mathcal{T}|}\}), \)
\( r^{emo} = \text{EmoNet}(\{e_1, ..., e_{|\mathcal{E}|}\}), \)
\( r^{sty} = \text{StyNet}(\{s_1, ..., s_{|\mathcal{S}|}\}). \)
为了更充分地提取信息,本方案采用多通道提取器,每个视图得到多个表示 \( \{r^{sem}_i\}_{i=1}^{k_{sem}}{risem} \) 、 \( \{r^{emo}_i\}_{i=1}^{k_{emo}}{riemo} \) 和 \( \{r^{sty}_i\}_{i=1}^{k_{sty}}{risty} \)。
多头跨视图交互器。 基于提取到的多视图表示,进行跨视图表示建模:
\( x = \prod_{i=1}^{k_{sem}} (r_i^{sem})^{a_i^{sem}} \odot \prod_{j=1}^{k_{emo}} (r_j^{emo})^{a_j^{emo}} \odot \prod_{q=1}^{k_{sty}} (r_q^{sty})^{a_q^{sty}} \)
上式中 aa 为自动学习的参数,可以控制不同视图表示的权重。为了建模不同组合的跨视图表示,我们采用多头跨视图交互器,得到多个跨视图表示 \{z_i\}_{i=1}^H{zi}i=1H 。
3.2 领域记忆模块
领域特质记忆。 它旨在自动捕获和存储领域特征。领域特征存储器可以表示为\( \mathcal{C} = \{c_i\}_{i=1}^N \) ,其中 ci 表示第 i 个域的存储器单元, N 表示域的数量。域存储器 C 的所有参数都随机初始化,并通过反向传播自动学习。记忆单元 ci 仅从第 i 个域的训练样本中学习,因此可以将其视为第 ii 个域的特征表示。
领域事件记忆。 某条新闻被赋予特定的域标签 d ,但该新闻可能同时包含其他域的信息。为了解决领域标签不完整的问题,我们提出了一种领域事件记忆机制,旨在发现潜在的新闻领域标签,丰富领域信息。关键思想是,一个领域事件记忆矩阵记录了该领域中发布的所有新闻,对于某个新闻,我们评估该新闻和所有领域事件记忆矩阵之间的相似性。相似性可以表示潜在域标签的分布。
第 jj 个领域的领域事件记忆表示为\( \mathcal{M}_j = \{m_i\}_{i=1}^Q \) ,其中 M 表示一个内存单元, Q 表示内存单元的数量。内存单元 m 表示一组相似的新闻,每个新闻域中的所有新闻都可以划分为 Q 个簇。每个域都有一个域事件记忆矩阵,因此有 N 域事件记忆矩阵。
初始化: 我们通过使用K-means算法聚类相似的新闻片段来初始化mm。一条新闻的特征表示是由nn代表的:
\( n = [\mathcal{G}(\{t_1, ..., t_{|\mathcal{T}|}\});\{e_1, ..., e_{|\mathcal{E}|}\};\{s_1, ..., s_{|\mathcal{S}|}\}]\in \mathbb{R}^{I}.n=[G({t1,...,t∣T∣});{e1,...,e∣E∣}; \)
在训练之前,我们获取所有新闻的表示,并分别使用K-means将新闻表示聚合到每个域的 QQ 簇中。对于特定的域,所有簇的中心都被用来初始化其内存单元。
读操作: 该操作旨在评估给定新闻与所有领域事件记忆矩阵之间的相似性。具体来说,对于给定的新闻,我们首先在某个域事件内存矩阵 \mathcal{M}_jMj 中找到所有相似的内存单元,并将它们聚合为一个域表示:
\( o_j = \text{softmax}(nWg(\mathcal{M}_j)/\tau )\mathcal{M}_j, \)
其中, g()g() 表示转置函数, WW 是一个可学习的参数矩阵。我们将 \tauτ 设置为0.01,只查找最相似的事件集群。所有域表示拼接为一个矩阵 \mathcal{D} = [o_1, ...,o_N] \in \mathbb{R}^{N \times I}D=[o1,...,oN]∈RN×I ,其中 NN 表示域的数量, II 表示特征维度。然后,相似性分布可以表示为:
\( v = \text{softmax}(nVg(\mathcal{D})). \)
对于某条新闻,根据域标签 dd ,我们查找域特征内存 cc 以获得一个显式的域表示 c_dcd 。然后,使用相似性分布 vv ,我们计算隐式域表示为: \( u = \sum_{i=1}^o v_i c_i \) ,其中 ci 表示第 i 域, vi 表示相似性分布向量的第 i 个元素。隐式域表示包含潜在的域信息。最后,隐式表示 u 和显式表示 cd 拼接起来,表示为 [cd,u] ,以表示新闻中丰富的领域信息。
写操作: 我们采用如下公式在每次迭代过程中进行写入:
\( m_i = m_i - \beta {erase}_i + \beta {add}_i, \)
\( {add}_i = {sim}_i \cdot n, \)
\( {erase}_i = {sim}_i \cdot m_i, \)
\( sim = \text{softmax}(nWg(\mathcal{M}_d) / \tau). \)
3.3 基于领域适配器的特征融合与消息真实性判别
由于存在域差异,不同域的具有判别性的跨视图表示可能不同。因此,我们提出了一个域适配器来建模域差异。域适配器从域记忆模块中获取丰富的域表示 [c_d,u][cd,u] 作为输入,以聚合有用的跨视图表示,用于最终预测。具体而言,聚合的交叉视图表示形式如下:
\( r = \sum_{i = 1}^{H} w_i z_i, \quad w = \text{softmax} (f([c_d, u])), \)
其中 f()f() 表示前馈神经网络。再将聚合到的的表示送入一个多层感知机,得到最后预测的概率:
\( \hat{p} = \text{Sigmoid}(\text{MLP}(r)). \)
实验
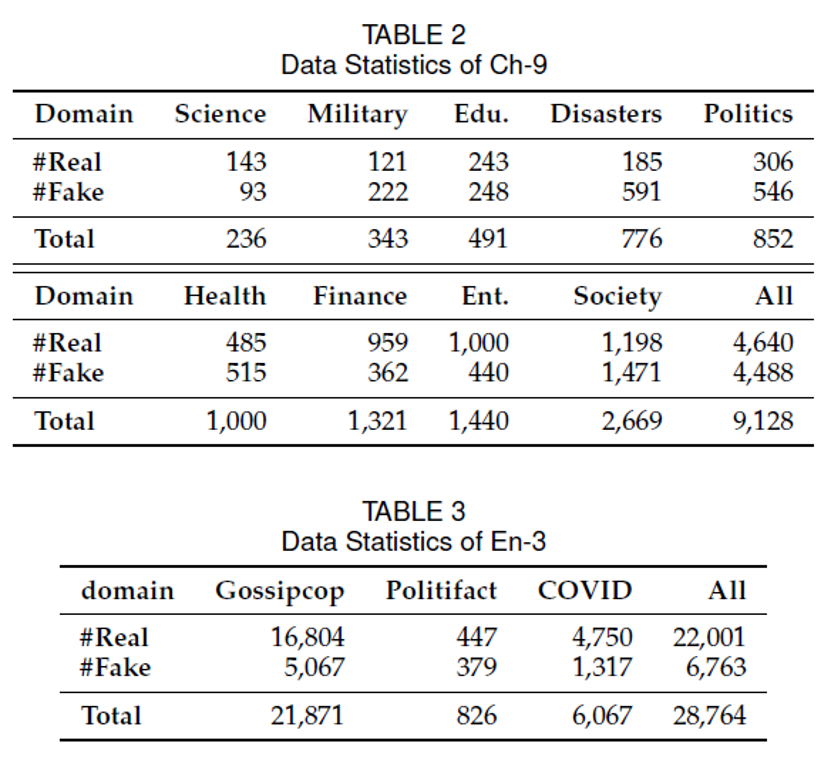
1 数据集
中文数据集我们采用Weibo21数据[1],英文数据我们使用FakeNewsNet[2]以及COVID[3]数据组成三个领域,数据统计如下表:
2 离线实验
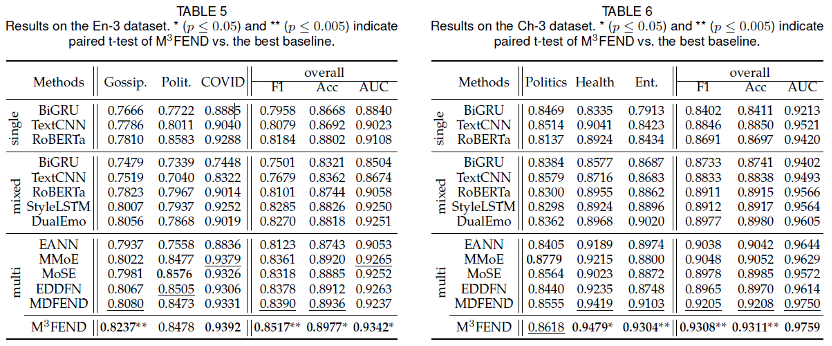
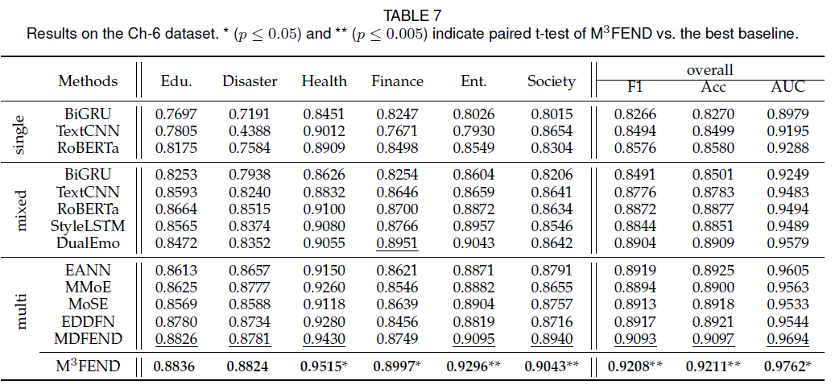
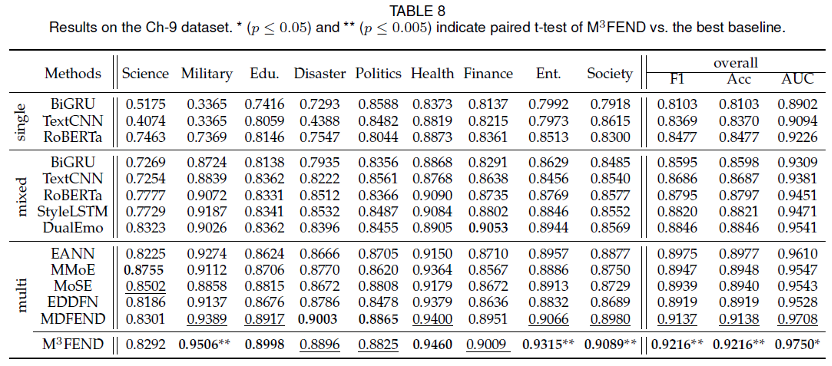
我们选取了3类基础虚假新闻检测模型或者普通文本分类模型,第一类包括基础文本分类模型,用于单领域虚假新闻检测包括BiGRU,TextCNN, RoBERTa,第二类是将所有领域数据混合在一块训练,包括BiGRU,TextCNN, RoBERTa,StyleLSTM,DualEmo,第三类是多领域算法,包括EANN,MMoE,MoSE,EDDFN,MDFEND。实验结果如下图所示,可以看到在大多数任务上,基于不同的基模型我们的方法都有提升。
3 线上实验
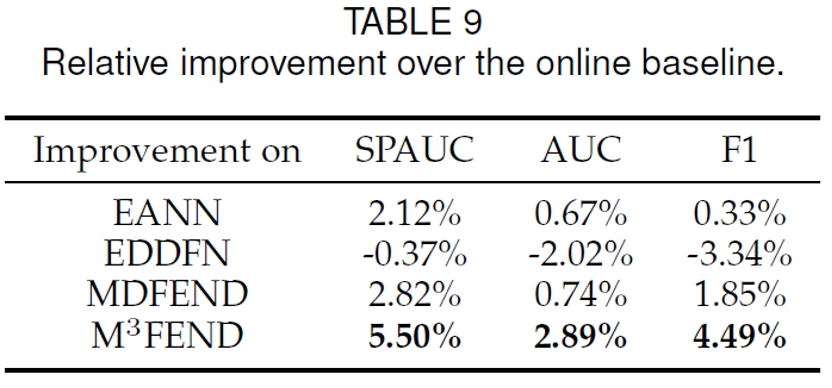
此外我们基于线上数据(睿鉴识谣)进行了实验,下表列出了相比于每个基模型的提升,可以看到我们的方法在大多数任务上都有提升。
4 分析实验
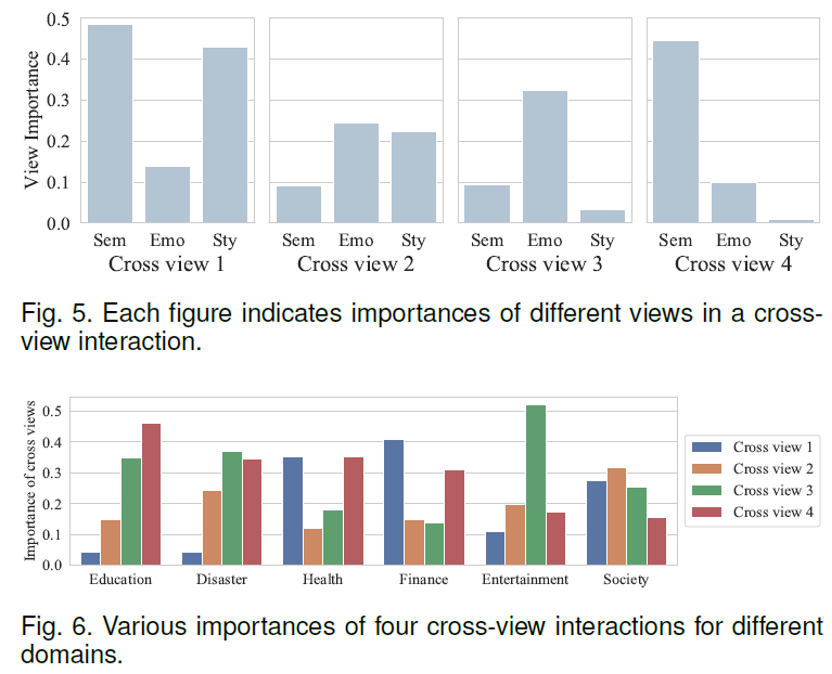
图5可视化了模型学的跨视图表示,可以看到我们的方法可以学到不同的跨视图表示。图6可视化了不同领域挑选的跨视图表示,可以看到领域适配器会根据领域信息挑选有用的跨视图表示。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢