
论文标题:DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR
论文链接:https://arxiv.org/abs/2201.12329
代码链接:https://github.com/IDEA-Research/DAB-DETR
导读
DAB-DETR 提出了一种新的建模 DETR 中 query 的方式,使用 4 维的 anchor box,这一建模方式不仅使得 DETR query 有了可解释性,同时作为位置先验可以加速模型收敛,以及利用 box 的尺度信息调制注意力图。
这一建模方式也将 DETR 类模型和传统的 two-stage 模型如 Faster RCNN 联系了起来。decoder 中 cross-attention 的作用类似于 ROI pooling 或者 ROI align,我们称之为 soft-ROI pooling。
模型性能:
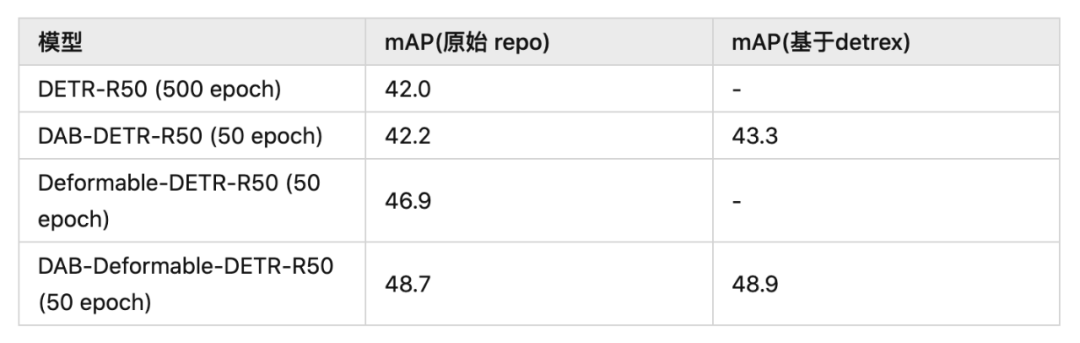
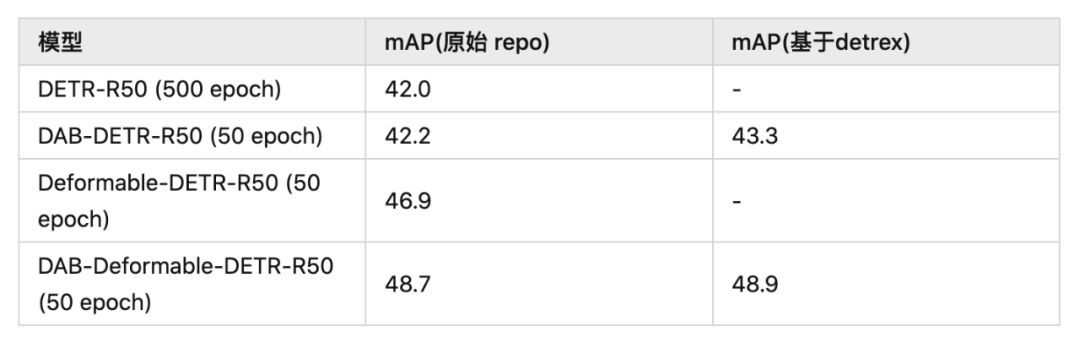
我们的 formulation 可以使用在原始 DETR 或者 Deformable DETR 上,都能相比于原始模型带来很大的增益。另外,基于我们新的算法库 detrex 的模型带来了更好的结果。
方法
2.1 动机和分析
DETR 作为首个使用 Transformer 做目标检测的模型,非常具有创新性。他将目标检测建模成集合预测的任务,即输入一组(如 100 个)learnable 的 query,然后输入对应数量(如 100 个)的物体预测结果。在训练过程中,使用二分图匹配预测和标签进行训练,而测试时不需要后处理(如 nms)即可产生所有结果。
尽管很简单、优雅,但是 DETR 存在两个问题,一是 query 含义并不清楚,不可解释,二是模型收敛慢。我们在这篇文章里主要希望解决两个问题。本来这应该是两个独立问题,不过后来我们发现,DETR 收敛慢很大程度上来自于 query 含义的不明。
DETR中的query
在原始的 DETR 文章中的 object query 画的比较简单,可能会让人觉得 query 就是一组向量:
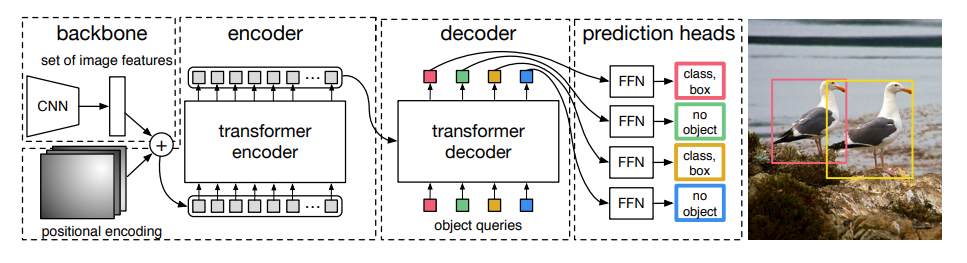
▲ 原始DETR中的框图
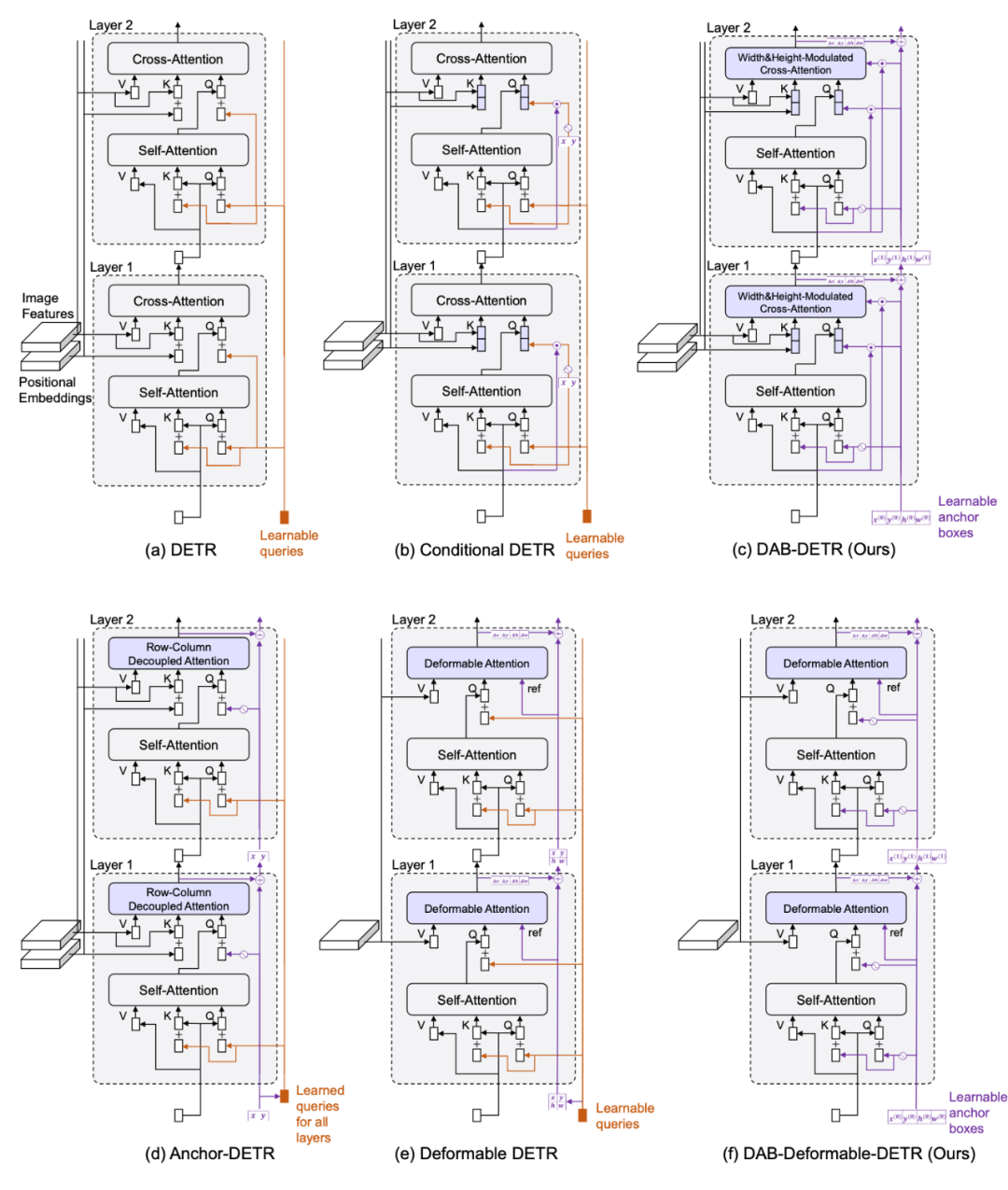
然而实际上 object query 应该有两部分组成,我们称之为 content query 和 positional query(这里感谢 conditional detr,这两个名字由他们提出。)我们这里画出来了 encoder 和 decoder 中的 attention 的组成部分。
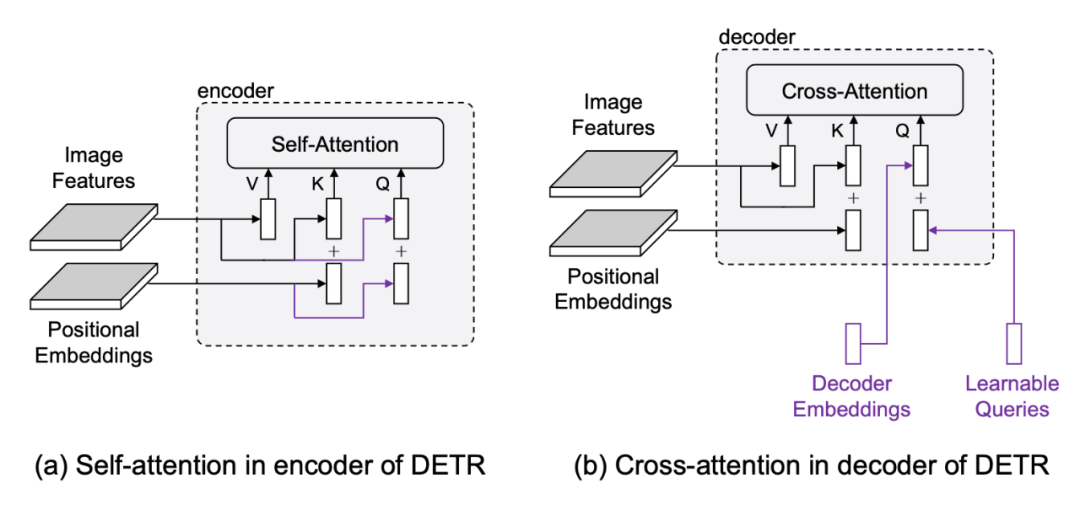
▲ encoder和decoder的attention部分
可以看到,encoder 和 decoder 里 attention 和 query 和 key 都是由两部分组成的,比如 encoder 里的 query 分别来自于图像特征(包含语义信息)和位置编码(包含位置信息),因此这两部分分别称为 content query(对应图像特征)和 positional query(对应位置编码)。key 和 query 完全相同。value 只有图像特征这一语义部分。
再看 decoder,decoder 的 key 和 value 与 encoder 的组成完全相同,但是 query 则不同。query 的语义部分来自于 decoder embeddings,对应上层的输入,是由图像特征组合来的。而位置部分则来自于 learnable queries,这是与我们看 DETR 的框架图后的第一反应不同的。因此 decoder 的 learnable query 实际指代的是位置信息。
2.2 Cross-attention的作用与soft-ROI pooling
接下来我们想来说明一下 cross-attention 在做什么,以及与传统的 Faster RCNN 之间的关系。
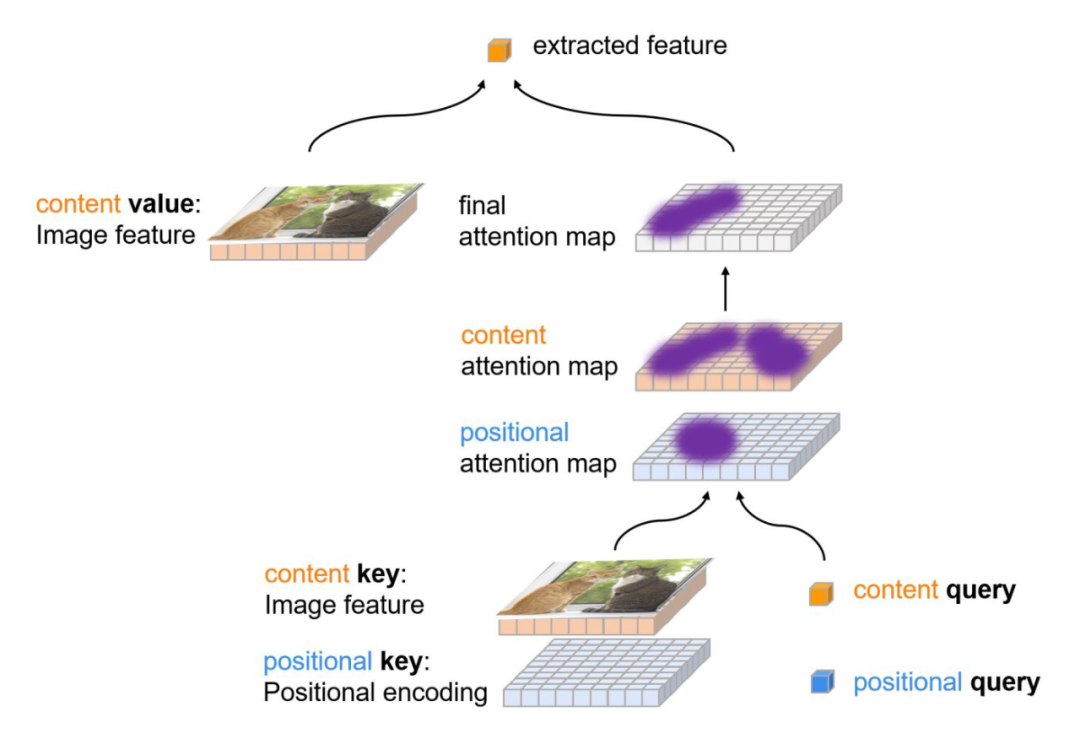
▲ attention & soft ROI pooling
我们看到,在 attention 模块中,query 和 key 计算相似度,同时考虑了 content 信息和 positional 信息,计算出一个注意力图,然后使用这个注意力图从原始图片特征中提取特征。
这个步骤非常类似于传统两阶段检测器中的 ROI pooling(或者 ROI align)。但是由于注意力图是有 query 和 key 共同决定的,并不局限于物体框内信息,我们称之为 Soft ROI pooling。
2.3 将query建模成anchor box
learnable query 不够好
既然了解了 attention 及 decoder 的作用,下面我们看原始的 detr 中 query 问题在哪。
我们发现,原始的 learnable query 学习到的特征并不够好,即不能提供 soft roi pooling 中所需的 roi 信息。
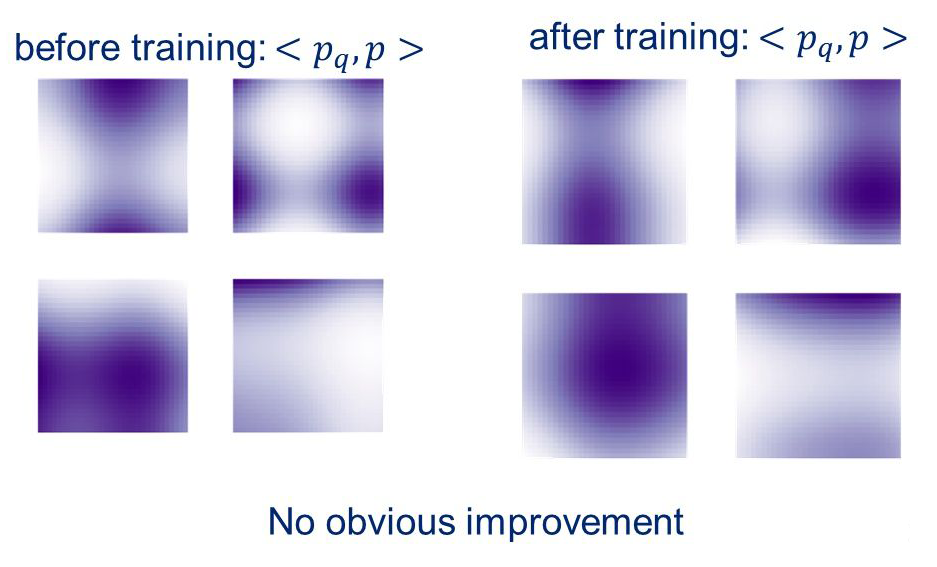
▲ 训练前后的位置注意力图
如图,训练前后的 learnable query 产生的位置注意力图仍然存在多模式、退化解等现象,并不能为 soft roi pooling 提供 roi 的信息。
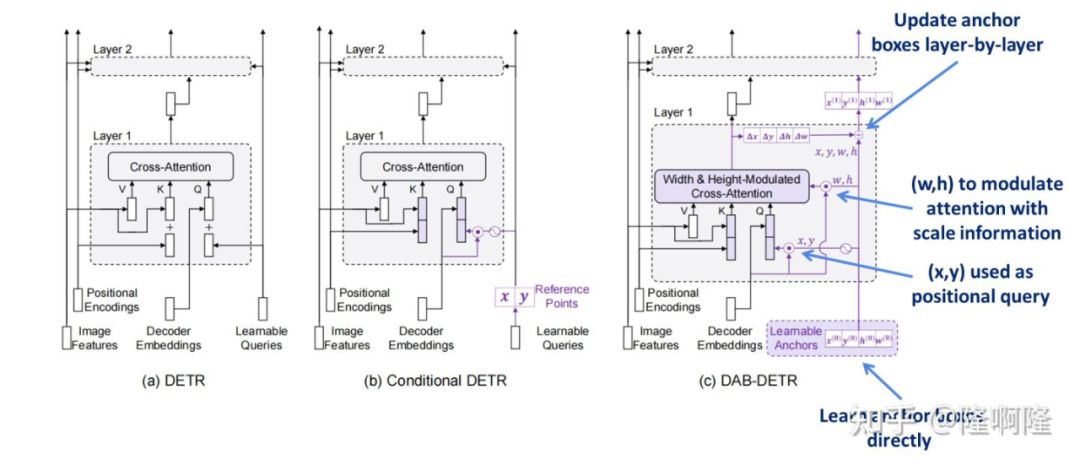
那么很自然的,我们意识到,要为 cross attention 提供更好的位置先验,提供更好的 roi region。很自然的,传统两阶段检测器中的 anchor box 可以引入到模型中作为位置先验。
引入anchor box作为query提供位置先验
▲ 从DETR到DAB-DETR
将 anchor box 引入之后的好处有:
- query 有了可解释性。
- 为模型提供了位置先验,加速收敛。
- anchor box 中的位置信息可以用来调制注意力图。
- anchor box 可以层与层进行更新。
anchor box 直接提供了 roi 区域用来做 soft roi pooling,因而这一描述也更加的自然。
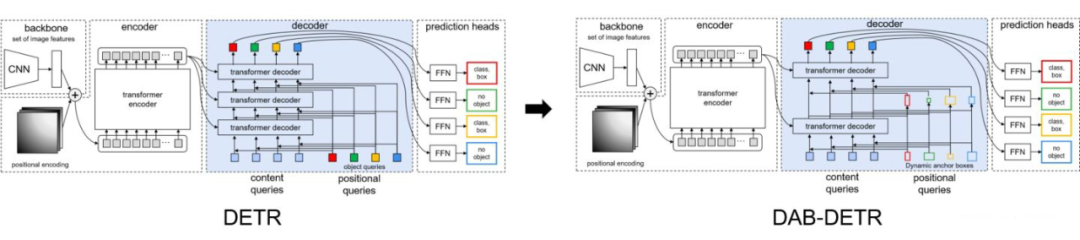
模型改进简述
将我们的模型和 DETR&Conditional DETR 的对比列了出来。我们核心改进有:
- 直接学习 anchor box 作为 query
- 使用正余弦编码后的 x,y 作为 positional query
- 使用 w,h 调制注意力图
- 层与层更新 anchor box
2.4 DAB-Deformable-DETR
我们的建模方式也是通用的,我们将 anchor box 的建模方式用到 deformble DETR 里,依然能带来性能的提升。
2.5 DETR类模型对比
我们在文章里做了很多对比,包括将 DAB-DETR 和之前的 DETR 系列做对比:
▲ DETR 类模型的对比
DAB-DETR & Faster RCNN
这里其实更想和大家分享关于 DETR 和传统检测器进行对比。从我们的讨论中我们看到,DETR 中的 encoder 起到了特征增强的作用,类似于一个 non-local 的模块。
而更令人着迷的 decoder 则起到了类似于 two-stage 模型中 ROI head 的作用,通过 Soft ROI pooling 的方式不断从特征图中采集特征,进行 box 的回归。而多个 decoder layer 又起到了类似于 cascade RCNN,类似于级联的 ROI head 的效果。
那么现在来看除了结构上(Transformer 和卷积)以外,DAB-DETR 和 Faster RCNN 还有哪些区别:
一是 box 产生的方式。Faster RCNN 来自于 RPN,而 DAB-DETR 来自于 learnable 的 anchor box(从这个意义上 DAB-DETR 更像是 Sparse RCNN)。那如果我们也将 DAB-DETR 的 anchor box 来自一个 RPN 或者 encoder 输出(Deformble DETR 已经做了),我们也可以构造一个 two stage 的 DAB-DETR,也会有更好的性能。
二是标签分配的方式。DETR 类模型的匹配是匈牙利匹配,one-to-one,同时考虑 content 和 position,在 layer 之后;而 Faster RCNN 是 one-to-many(一个 gt 可能对应多个 anchor),只考虑 position,在 layer 之前。
那么最理想的匹配方式是什么?有没有更好的匹配方案?也是一个值得研究的问题。这里推荐 peize 大佬的一篇文章 What Makes for End-to-End Object Detection? 很有启发意义。
综上,DETR 结构也可以看做是一种 two stage 模型,只是用了不同的模型结构(Transformer)和标签分配方式(匈牙利匹配)。
实验
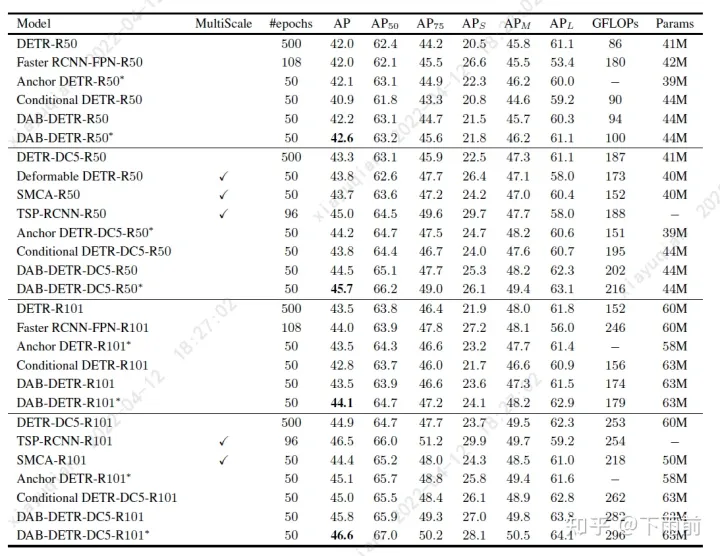
消融实验也证明了每个设计的有效性。我们充分相信 Transformer-based/DETR 类模型将会称为目标检测带来更广泛的影响,希望更多人来一同推动这一领域的发展。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢