
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:视频的分割与物体关系新基准、对比语言-图像预训练统一框架、验证视觉完整性的物理折射体、稠密检索的渐进式蒸馏、流动性结构化状态-空间模型、室内移动智能体多模态多任务场景理解模型研究、超级分辨率综述指南、连续时间系统分析的深度学习方法、概率、物理和神经网络之间的联系
1、[CV] EPIC-KITCHENS VISOR Benchmark: VIdeo Segmentations and Object Relations
A Darkhalil, D Shan, B Zhu, J Ma, A Kar, R Higgins, S Fidler, D Fouhey, D Damen
[Uni. of Bristol & Uni. of Michigan & Uni. of Toronto]
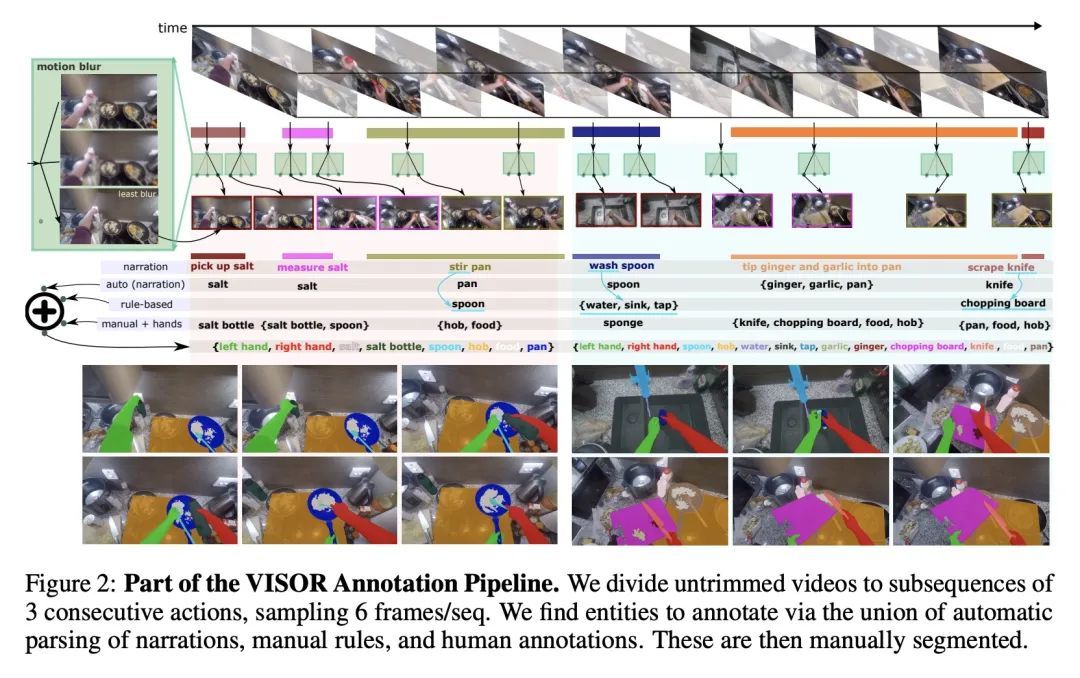
EPIC-KITCHENS VISOR基准:视频的分割与物体关系。本文提出VISOR,一种新的像素标注数据集和基准套件,用于在自我中心的视频中对手和活动物体进行分割。VISOR注释了来自EPIC-KITCHENS的视频,这带来了一系列新的挑战,是目前视频分割数据集所没有遇到的。需要确保像素级标注的短期和长期一致性,因为对象经历了转换性的互动,例如,一个洋葱被剥皮、切丁和煮熟,目标是获得皮、洋葱块、砧板、刀、锅以及行动的手的准确像素级标注。VISOR引入了一个标注管线,部分由AI驱动,以实现可扩展性和质量。总的来说,本文公开发布了257个物体类别的272个手动语义掩码,9.9M的插值密集掩码,67K的手-物体关系,覆盖了36小时的179个未修剪的视频。除标注以外,本文还介绍了视频目标分割、交互理解和长期推理方面的三个挑战。
We introduce VISOR, a new dataset of pixel annotations and a benchmark suite for segmenting hands and active objects in egocentric video. VISOR annotates videos from EPIC-KITCHENS, which comes with a new set of challenges not encountered in current video segmentation datasets. Specifically, we need to ensure both shortand long-term consistency of pixel-level annotations as objects undergo transformative interactions, e.g. an onion is peeled, diced and cooked where we aim to obtain accurate pixel-level annotations of the peel, onion pieces, chopping board, knife, pan, as well as the acting hands. VISOR introduces an annotation pipeline, AI-powered in parts, for scalability and quality. In total, we publicly release 272K manual semantic masks of 257 object classes, 9.9M interpolated dense masks, 67K hand-object relations, covering 36 hours of 179 untrimmed videos. Along with the annotations, we introduce three challenges in video object segmentation, interaction understanding and long-term reasoning. For data, code and leaderboards: http://epic-kitchens.github.io/VISOR
https://arxiv.org/abs/2209.13064



2、[CV] UniCLIP: Unified Framework for Contrastive Language-Image Pre-training
J Lee, J Kim, H Shon, B Kim, S H Kim, H Lee, J Kim
[LG AI Research & KAIST]
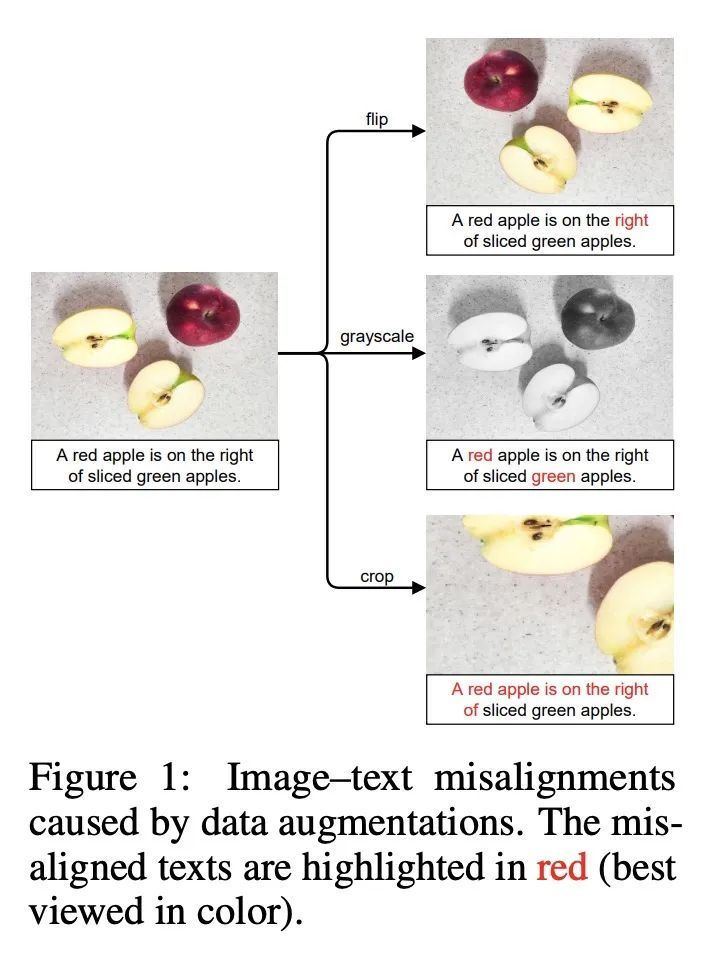
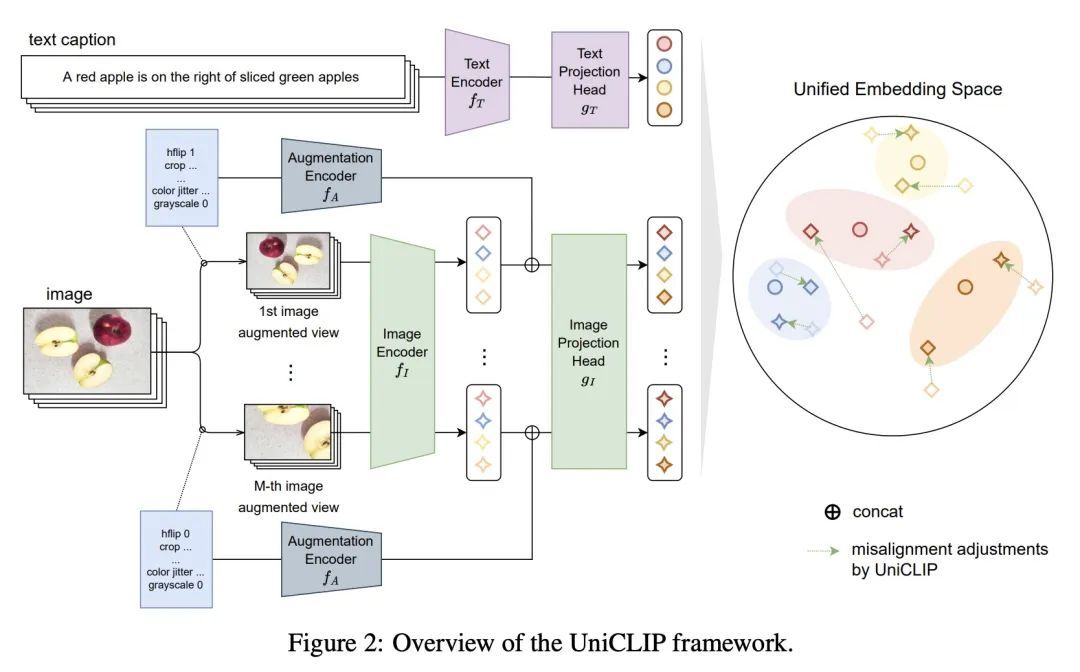
UniCLIP: 对比语言-图像预训练统一框架。用对比目标对视觉-语言模型进行预训练,已经显示出很有希望的结果,这些结果既可以扩展到大的未经整理的数据集,又可以迁移到许多下游应用中。一些后续工作旨在通过增加自监督条款来提高数据效率,但在这些工作中,域间(图像-文本)对比损失和域内(图像-图像)对比损失是在单独的空间上定义的,因此许多可行的监督组合被忽略了。为了克服这个问题,本文提出UniCLIP,一种统一的对比语言-图像预训练框架。UniCLIP将域间对和域内对的对比损失整合到一个单一的通用空间。UniCLIP的三个关键部分解决了在整合不同领域之间的对比损失时出现的差异:(1)增强感知特征嵌入,(2)MP-NCE损失,以及(3)依赖于域的相似性测量。UniCLIP在各种单模态和多模态的下游任务上的表现优于之前的视觉-语言预训练方法,实验表明组成UniCLIP的每个组件都对最终的性能做出了很好的贡献。
Pre-training vision–language models with contrastive objectives has shown promising results that are both scalable to large uncurated datasets and transferable to many downstream applications. Some following works have targeted to improve data efficiency by adding self-supervision terms, but inter-domain (image–text) contrastive loss and intra-domain (image–image) contrastive loss are defined on individual spaces in those works, so many feasible combinations of supervision are overlooked. To overcome this issue, we propose UniCLIP, a Unified framework for Contrastive Language–Image Pre-training. UniCLIP integrates the contrastive loss of both inter-domain pairs and intra-domain pairs into a single universal space. The discrepancies that occur when integrating contrastive loss between different domains are resolved by the three key components of UniCLIP: (1) augmentationaware feature embedding, (2) MP-NCE loss, and (3) domain dependent similarity measure. UniCLIP outperforms previous vision–language pre-training methods on various singleand multi-modality downstream tasks. In our experiments, we show that each component that comprises UniCLIP contributes well to the final performance.
https://arxiv.org/abs/2209.13430

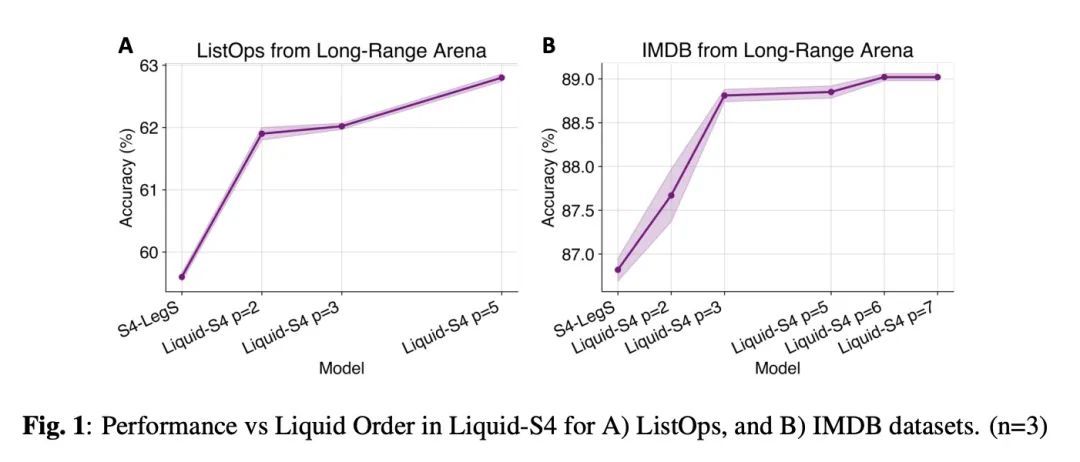
3、[CV] Totems: Physical Objects for Verifying Visual Integrity
J Ma, L Chai, M Huh, T Wang, S Lim, P Isola, A Torralba
[University of Washington & MIT & Meta AI]
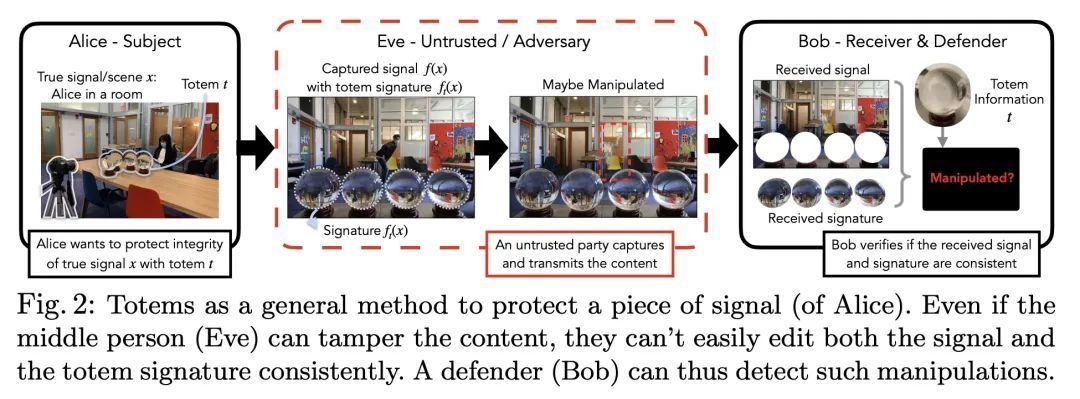
Totems:验证视觉完整性的物理折射体。本文提出一种新的图像取证方法:在场景中放置物理折射物体,称为Totem,以保护该场景的任何照片。图腾会弯曲和重定向光线,从而在一张图像中提供多个尽管是扭曲了的场景视图。防御者可以利用这些扭曲的Totem像素来检测图像是否被篡改过。该方法是通过估计Totem在场景中的位置并利用其已知的几何和材料属性来解读通过Totem的光线。为了验证一个受Totem保护的图像,检测从Totem视角重建的场景和从摄像机视角重建的场景外观之间的不一致。这种方法使对抗性操纵任务更加困难,因为对抗者必须在不知道Totem物理属性的情况下以几何上一致的方式修改Totem和图像像素。与之前基于学习的方法不同,该方法不需要对具体操作的数据集进行训练,而是利用场景和相机的物理属性来解决取证问题。
We introduce a new approach to image forensics: placing physical refractive objects, which we call totems, into a scene so as to protect any photograph taken of that scene. Totems bend and redirect light rays, thus providing multiple, albeit distorted, views of the scene within a single image. A defender can use these distorted totem pixels to detect if an image has been manipulated. Our approach unscrambles the light rays passing through the totems by estimating their positions in the scene and using their known geometric and material properties. To verify a totem-protected image, we detect inconsistencies between the scene reconstructed from totem viewpoints and the scene’s appearance from the camera viewpoint. Such an approach makes the adversarial manipulation task more difficult, as the adversary must modify both the totem and image pixels in a geometrically consistent manner without knowing the physical properties of the totem. Unlike prior learning-based approaches, our method does not require training on datasets of specific manipulations, and instead uses physical properties of the scene and camera to solve the forensics problem.
https://arxiv.org/abs/2209.13032


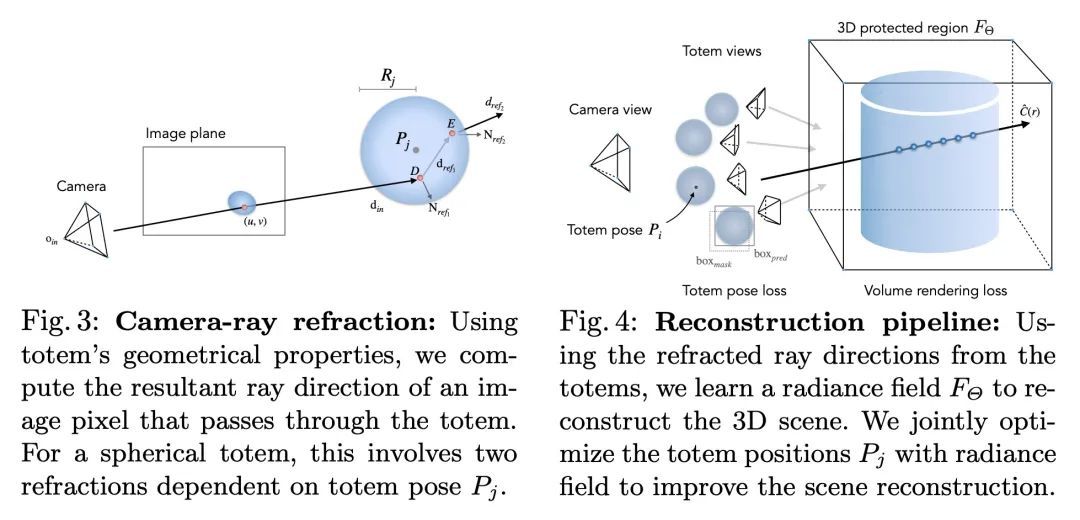
4、[IR] PROD: Progressive Distillation for Dense Retrieval
Z Lin, Y Gong, X Liu, H Zhang, C Lin, A Dong, J Jiao, J Lu, D Jiang, R Majumder, N Duan
[Xiamen University & Microsoft Research]
PROD:稠密检索的渐进式蒸馏。知识蒸馏是将知识从一个强大的教师模型转移到一个高效的学生模型的有效途径。理想情况下,期望老师越好,学生就越好。然而,这种期望并不总是能实现。由于教师和学生之间存在不可忽视的差距,一个更好的教师模型通过蒸馏导致一个糟糕的学生是很常见的。为了弥补这一差距,本文提出PROD,一种用于稠密检索的渐进蒸馏(PROgressive Distillation)方法。PROD包括一个教师渐进蒸馏法和一个数据渐进蒸馏法,以逐步提高学生的水平。在五个广泛使用的基准上进行了广泛的实验,包括MS MARCO Passage、TREC Passage 19、TREC Document 19、MS MARCO Document和Natural Questions,其中PROD实现了稠密检索的蒸馏方法中的最先进水平。
Knowledge distillation is an effective way to transfer knowledge from a strong teacher to an efficient student model. Ideally, we expect the better the teacher is, the better the student. However, this expectation does not always come true. It is common that a better teacher model results in a bad student via distillation due to the nonnegligible gap between teacher and student. To bridge the gap, we propose PROD, a PROgressive Distillation method, for dense retrieval. PROD consists of a teacher progressive distillation and a data progressive distillation to gradually improve the student. We conduct extensive experiments on five widely-used benchmarks, MS MARCO Passage, TREC Passage 19, TREC Document 19, MS MARCO Document and Natural Questions, where PROD achieves the state-of-the-art within the distillation methods for dense retrieval. The code and models will be released.
https://arxiv.org/abs/2209.13335

5、[LG] Liquid Structural State-Space Models
R Hasani, M Lechner, T Wang, M Chahine, A Amini, D Rus
[MIT]
流动性结构化状态-空间模型。对线性状态-空间模型(SSM)的状态转换矩阵进行适当的参数化,再加上标准的非线性,使其能够有效地从序列数据中学习表示,在一大系列的长程序列建模基准上确立了最先进的水平。本文表明,当诸如S4的结构性SSM由线性流动性时间常数(LTC)状态-空间模型给出时,可以进一步提高。LTC神经网络是因果连续时间神经网络,具有输入依赖的状态转换模块,这使得其在推理时学会自适应传入的输入。本文表明,通过使用S4中引入的状态转换矩阵的对角线加低秩分解,以及一些简化,基于LTC的结构状态空间模型,被称为Liquid-S4,在具有长程依赖性的序列建模任务中实现了新的最先进的泛化,如图像、文本、音频和医疗时间序列,在Long-Range Arena基准上的平均性能为87.32%。在完整的原始语音命令识别上,数据集Liquid-S4的准确率达到96.78%,与S4相比,参数数量减少了30%。性能的额外增益是Liquid-S4的核结构的直接结果,它在训练和推理期间考虑到了输入序列样本的相似性。
A proper parametrization of state transition matrices of linear state-space models (SSMs) followed by standard nonlinearities enables them to efficiently learn representations from sequential data, establishing the state-of-the-art on a large series of long-range sequence modeling benchmarks. In this paper, we show that we can improve further when the structural SSM such as S4 is given by a linear liquid time-constant (LTC) state-space model. LTC neural networks are causal continuous-time neural networks with an input-dependent state transition module, which makes them learn to adapt to incoming inputs at inference. We show that by using a diagonal plus low-rank decomposition of the state transition matrix introduced in S4, and a few simplifications, the LTC-based structural state-space model, dubbed Liquid-S4, achieves the new state-of-the-art generalization across sequence modeling tasks with long-term dependencies such as image, text, audio, and medical time-series, with an average performance of 87.32% on the Long-Range Arena benchmark. On the full raw Speech Command recognition, dataset Liquid-S4 achieves 96.78% accuracy with a 30% reduction in parameter counts compared to S4. The additional gain in performance is the direct result of the Liquid-S4's kernel structure that takes into account the similarities of the input sequence samples during training and inference.
https://arxiv.org/abs/2209.12951

另外几篇值得关注的论文:
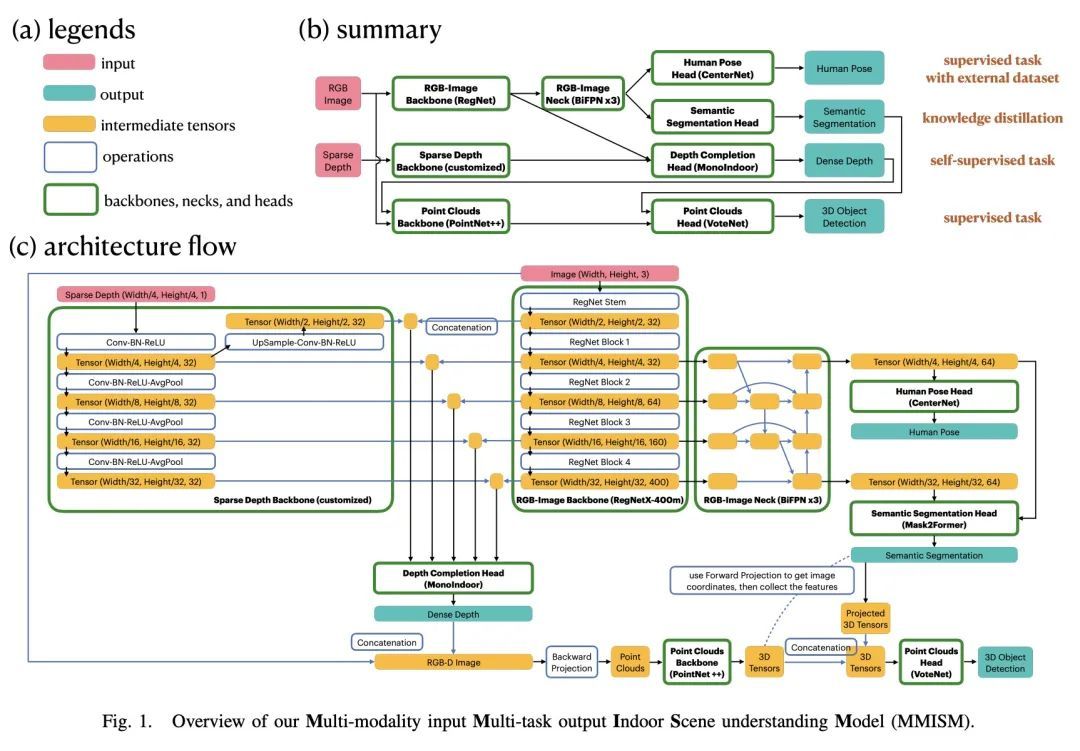
[CV] Towards Multimodal Multitask Scene Understanding Models for Indoor Mobile Agents室内移动智能体多模态多任务场景理解模型研究
Y H Tsai, H Goh, A Farhadi, J Zhang
[Apple]
https://arxiv.org/abs/2209.13156


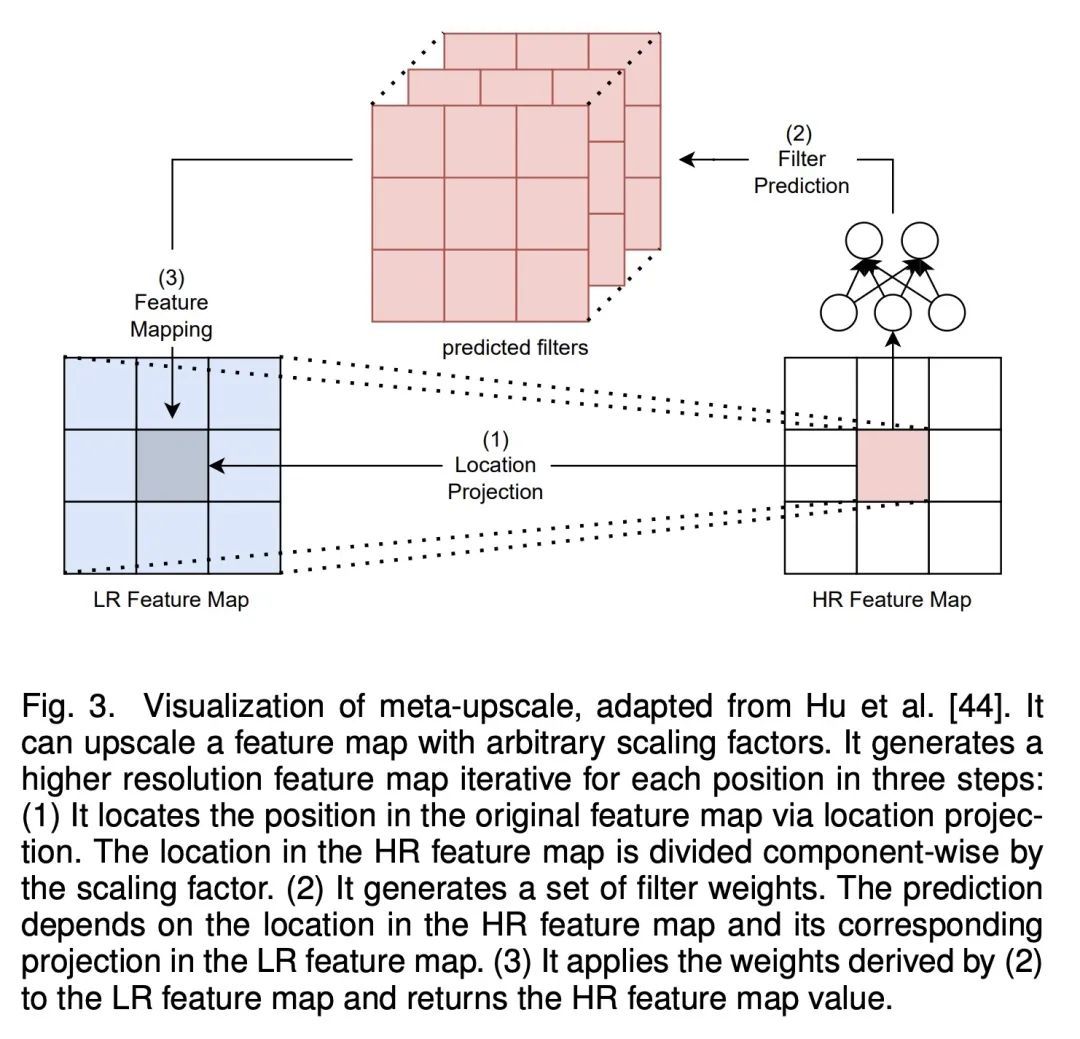
[CV] Hitchhiker's Guide to Super-Resolution: Introduction and Recent Advances
超级分辨率综述指南
B Moser, F Raue, S Frolov, J Hees, S Palacio, A Dengel
[German Research Center for Artificial Intelligence (DFKI)]
https://arxiv.org/abs/2209.13131


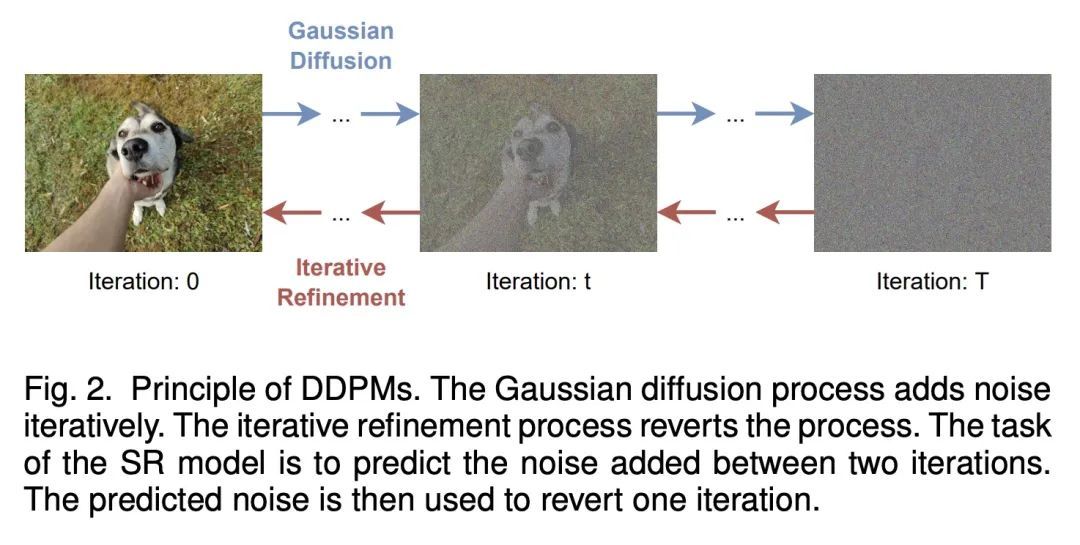
[LG] A Deep Learning Approach to Analyzing Continuous-Time Systems
连续时间系统分析的深度学习方法
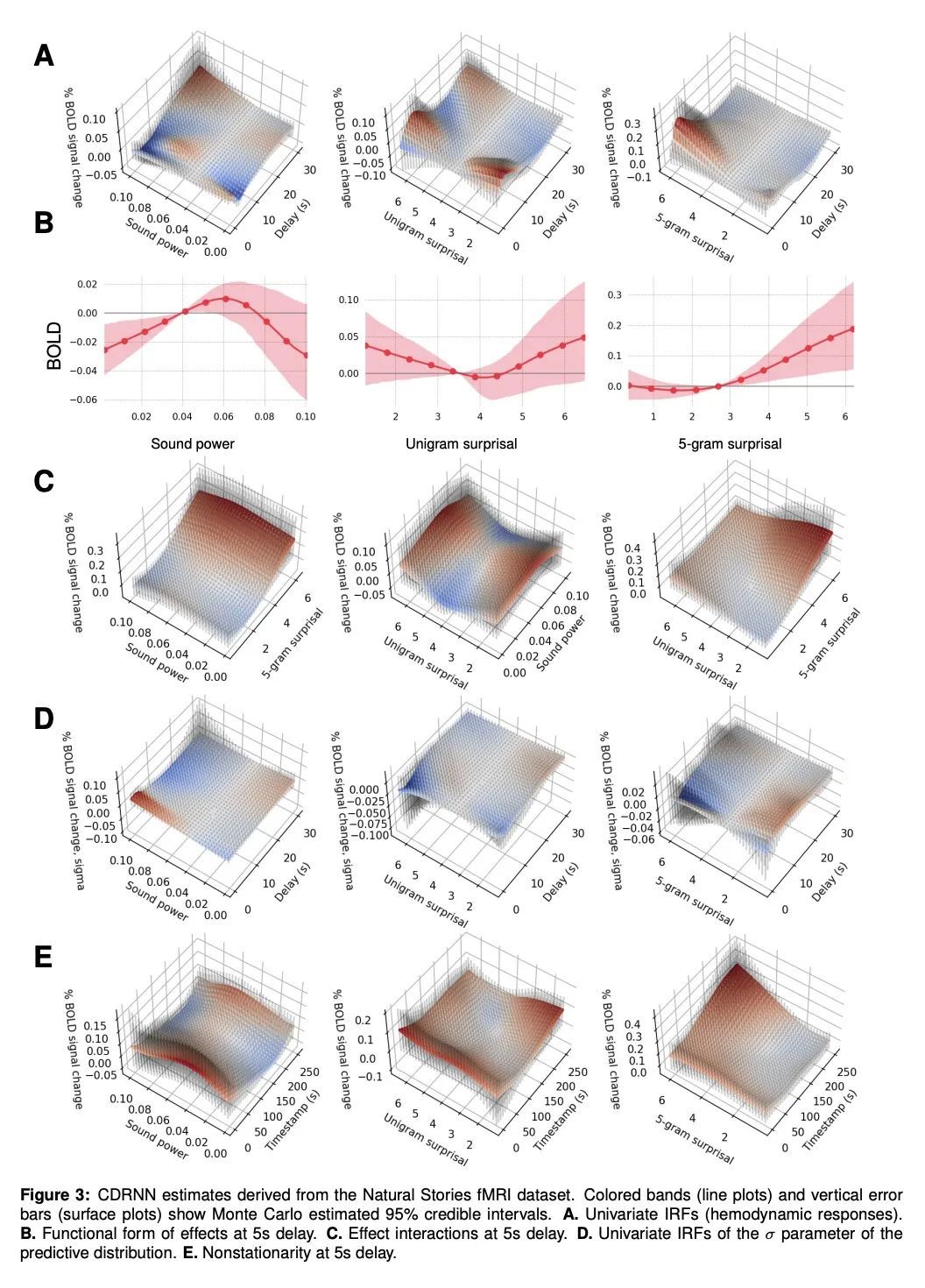
C Shain, W Schuler
[MIT]
https://arxiv.org/abs/2209.12128

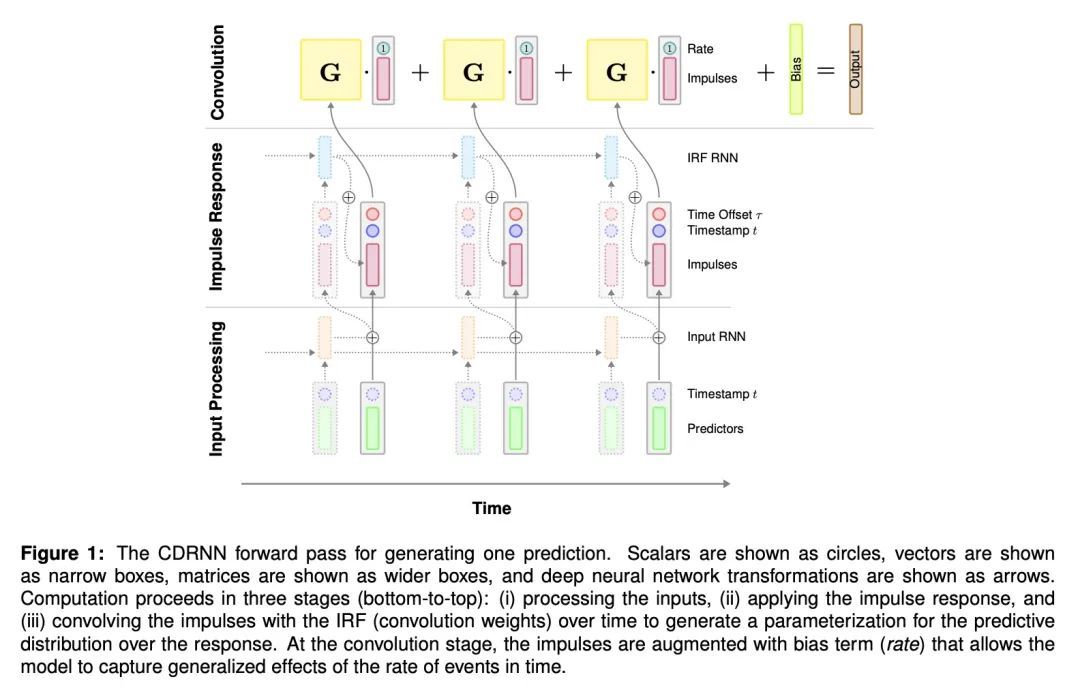
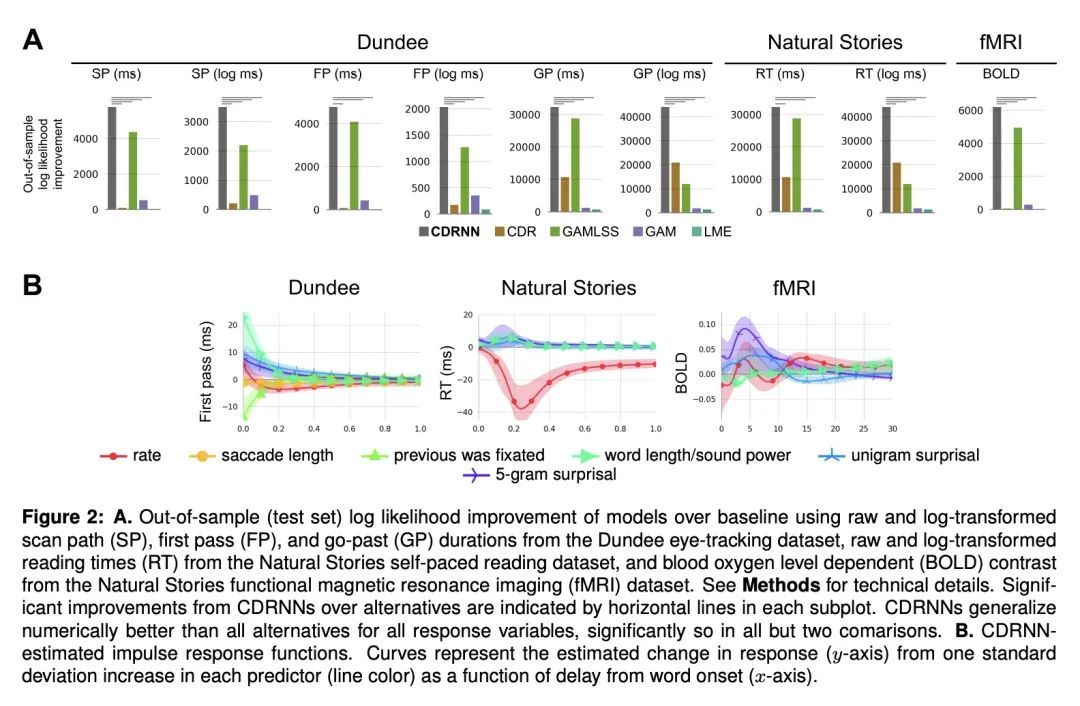
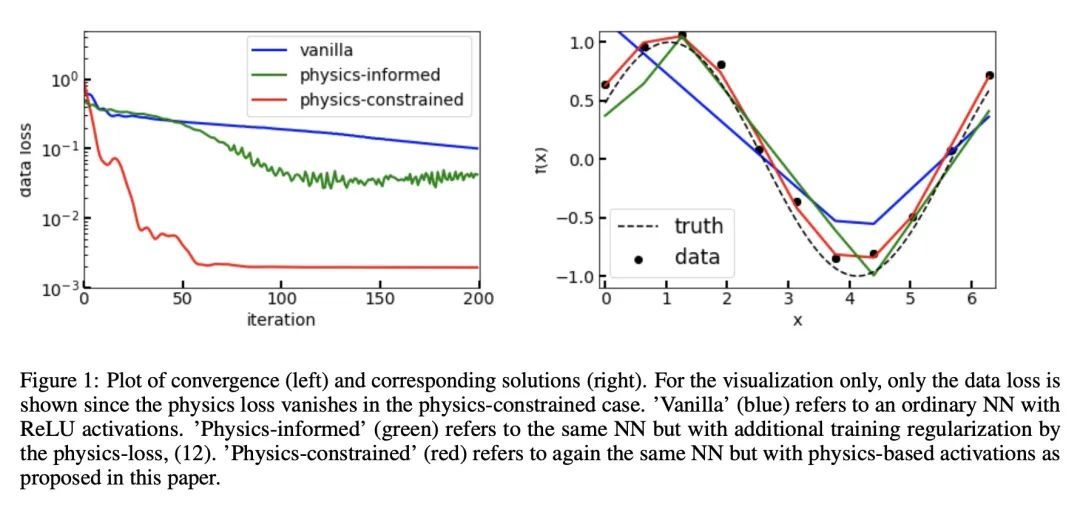
[LG] A connection between probability, physics and neural networks
概率、物理和神经网络之间的联系
S Ranftl
[Graz University of Technology]
https://arxiv.org/abs/2209.12737

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢