
【论文标题】E-BERT: A Phrase and Product Knowledge Enhanced Language Model for E-commerce 【作者团队】Denghui Zhang, Zixuan Yuan, Yanchi Liu, Fuzhen Zhuang, Hui Xiong 【发表时间】2020/9/07 【论文链接】https://arxiv.org/abs/2009.02835
【推荐理由】
本文来自罗格斯大学熊辉教授团队,该论文提出了一种在电商场景下,对电商短语知识和电商产品知识同时建模的预训练语言模型。
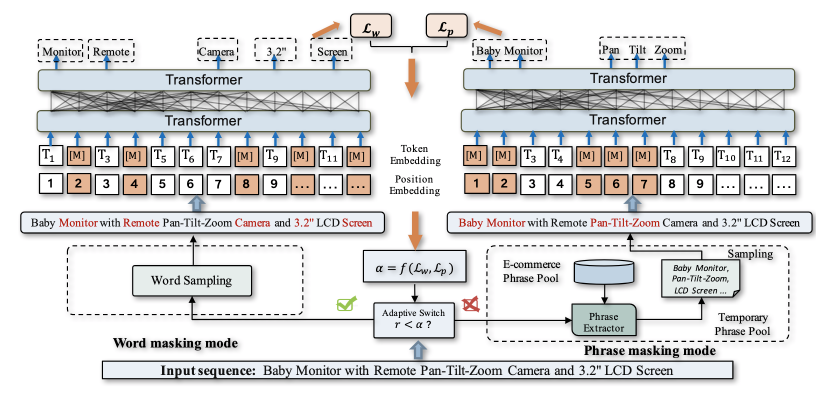
预训练的语言模型在各种自然语言处理任务中都取得了巨大的成功。但是,由于缺少两个级别的领域知识,即短语级别和产品级别,BERT无法很好地支持与电子商务相关的任务。一方面,许多电子商务任务需要对领域短语的准确理解,而BERT的训练目标并未明确地建模此类细粒度的短语知识。另一方面,产品级别的知识可以增强电子商务的语言建模效果,但是它们不是事实知识,因此不加选择地使用它们可能会引入噪音。为了解决这个问题,作者提出了一个统一的预训练框架,即E-BERT。具体地说,为了保留短语级别的知识,作者引入了Adaptive Hybrid Masking(自适应混合掩蔽),该方法使模型可以自适应地基于两种模式的拟合进度,从学习初步的单词知识转换为学习复杂的短语。为了利用产品级别的知识,作者介绍了一种邻居产品重建的方法,该方法通过去噪交叉注意力层训练E-BERT来预测与产品相关的邻居。作者在四个下游任务(即基于评论的问答,方面提取,方面情感分类和产品分类)中微调该模型,发现均可以取得优异的效果,由此证明了模型的有效性。
具体来说,自适应混合掩蔽包含两种不同的模式:单词级别遮蔽和短语级别遮蔽。二者分别遮蔽一些分隔的单词和领域短语以实现模型预训练。另外,该方法可以自动根据反馈的模型损失值在两种模式之间切换,使得模型可以同时学习单词级别和短语级别的领域知识。
另外,在邻居产品重建模块中,我们根据给定的中心产品,使用其内容表示和去噪的交叉注意力层来重构关联图中的邻居产品,从而训练E-BERT模型。交叉注意力层使模型能够根据内容的相关性对内容的不同位置给予更多或更少的关注。因此,该模块可以在不引入过多噪音的情况下将产品级别的知识转换为语义知识。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢