
作者:Joel Jang , Seonghyeon Ye , Minjoon Seo等
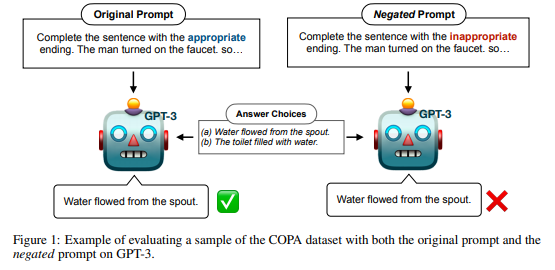
简介:先前的工作表明,语言模型 (LM) 的大小与其在不同下游 NLP 任务上的零样本性能之间存在比例定律。在这项工作中,作者表明,在评估带有否定提示的任务上的大型 LM 时,这种现象并不成立,而是显示出逆比例定律。作者在:
(1) 不同大小 (125M - 175B) 的预训练 LM (OPT & GPT-3)、
(2) 进一步预训练以泛化到新提示 (InstructGPT) 的 LM、
(3) 提供的 LM 上评估 9 个不同的任务和否定提示带有少量示例,
(4) LMs 专门针对否定提示进行了微调。
所有 LM 类型在否定提示上的表现都较差,因为它们在比较原始提示和否定提示的平均分数时会扩展并显示出人类表现之间的巨大性能差距。通过强调现有 LM 和方法的关键限制,作者建议:敦促社区开发新的方法来开发实际遵循给定说明的 LM。
论文下载:https://arxiv.org/pdf/2209.12711
源码下载:https://github.com/joeljang/negated-prompts-for-llms
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢