
作者:Kundan Krishna, Saurabh Garg, Jeffrey P. Bigham, 等
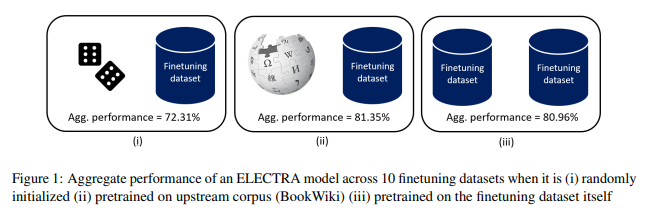
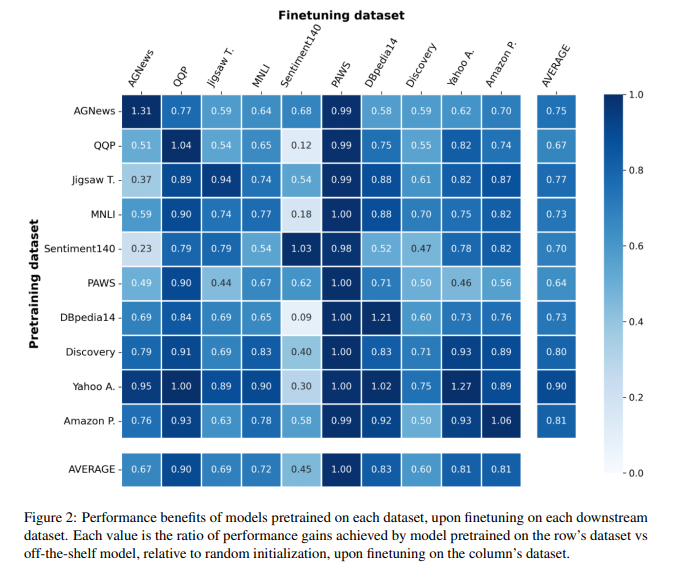
简介:对于大多数自然语言处理任务,主要做法是使用较小的下游数据集微调大型预训练transformer模型(例如,BERT)。尽管这种方法取得了成功,但仍不清楚这些收益在多大程度上归因于用于预训练的大量背景语料库与预训练目标本身。本文介绍了自我预训练的大规模研究,其中相同的(下游)训练数据用于预训练和微调。在针对 ELECTRA 和 RoBERTa 模型以及 10 个不同的下游数据集的实验中,作者观察到自我预训练与 BookWiki 语料库上的标准预训练相媲美(尽管使用了大约 10 ×--500 ×更少的数据),分别在第7和第5 数据集上优于 BookWiki 。令人惊讶的是,这些特定于任务的预训练模型通常在其他任务上表现良好,包括 GLUE 基准。作者的结果表明,在许多情况下,可归因于预训练的性能提升主要由预训练目标本身驱动,并不总是归因于大量数据集的合并。鉴于对网络规模预训练数据中的知识产权和攻击性内容的担忧,这些发现尤其重要。
论文下载:https://arxiv.org/pdf/2209.14389.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢