
【标题】Stabilizing Off-Policy Deep Reinforcement Learning from Pixels
【作者团队】Edoardo Cetin, Philip J. Ball, Steve Roberts, Oya Celiktutan
【发表日期】2022.7.3
【论文链接】https://arxiv.org/pdf/2207.00986.pdf
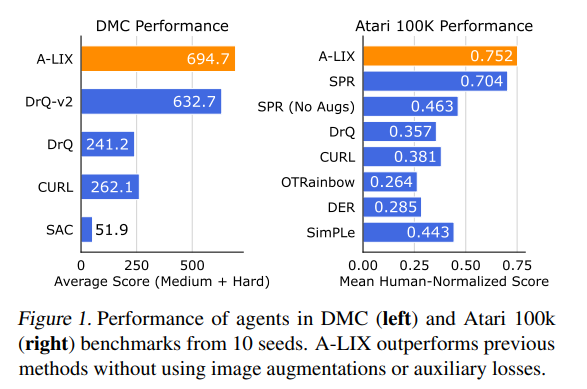
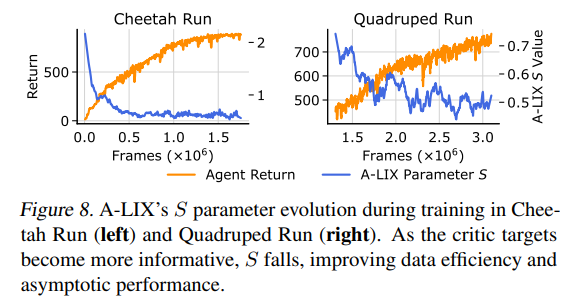
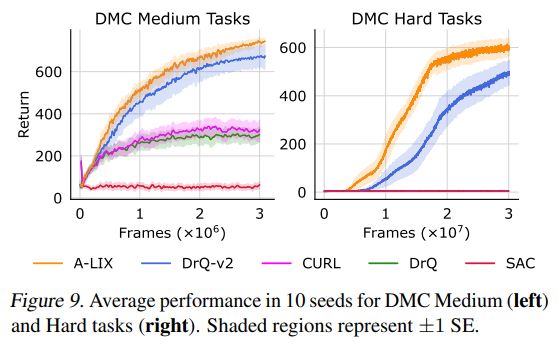
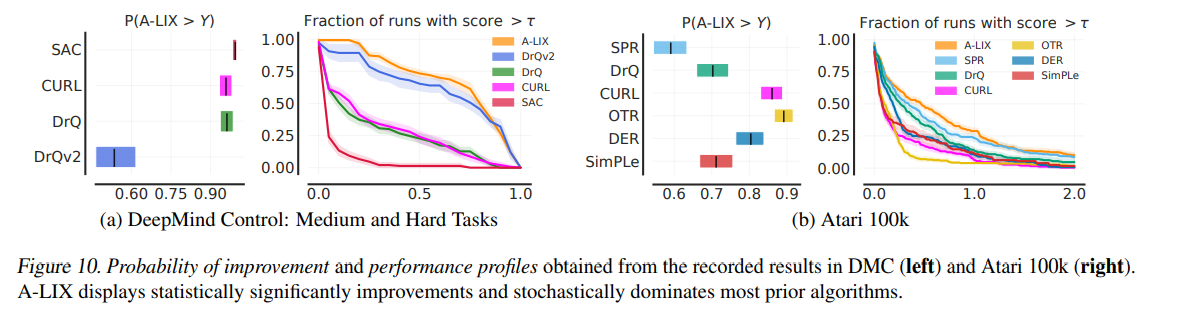
【推荐理由】众所周知,来自像素观察的非策略强化学习 (RL) 是不稳定的。 因此,许多成功的算法必须结合不同的特定领域实践和辅助损失,才能在复杂环境中学习有意义的行为。本文提供了新颖的分析,证明这些不稳定性是由使用卷积编码器和低幅度奖励执行时差学习引起的。这种新的视觉致命三元组会导致不稳定的训练和退化解的过早收敛,这种现象被称之为灾难性的自拟合。 基于分析,本文提出了 A-LIX,这是一种为编码器的梯度提供自适应正则化的方法,可以使用双重目标明确地防止灾难性自过拟合的发生。通过应用A-LIX,在DeepMind Control和Atari 100k基准测试中的表现明显优于先前的最先进水平,且没有任何数据增强或辅助损失。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢