
【标题】Federated Reinforcement Learning: Linear Speedup Under Markovian Sampling
【作者团队】Sajad Khodadadian, Pranay Sharma, Gauri Joshi
【发表日期】2022.6.21
【论文链接】https://arxiv.org/pdf/2206.10185.pdf
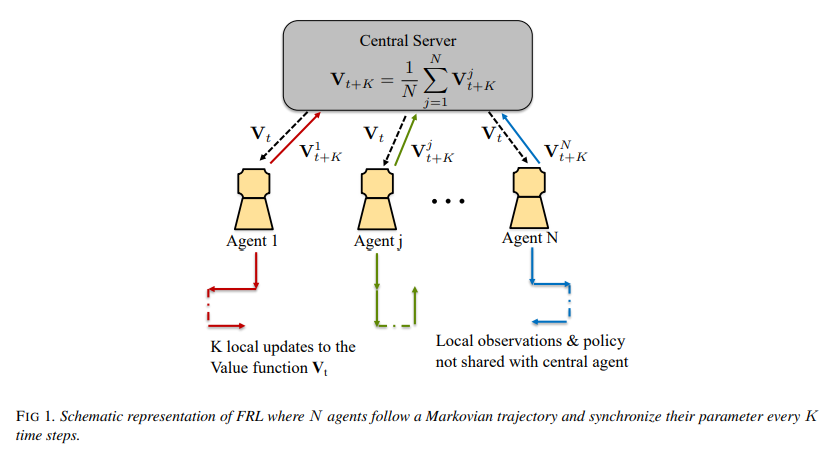
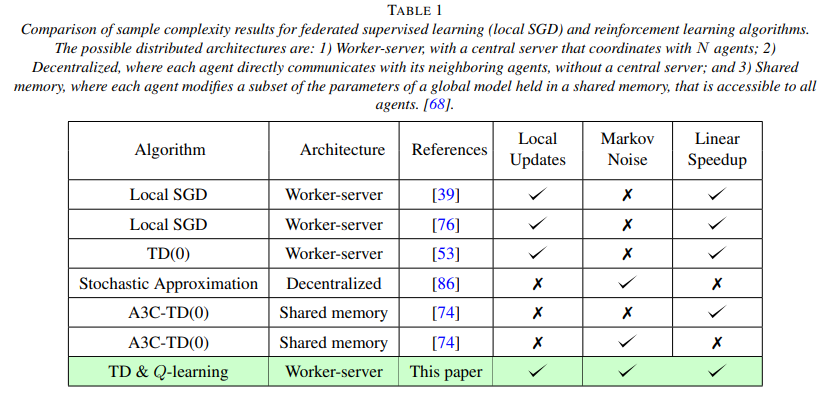
【推荐理由】由于强化学习算法是众所周知的数据密集型算法,因此从环境中采样观测值的任务通常分为多个智能体。然而,从通信成本来看,将这些观察结果从智能体传送到中心位置可能会非常昂贵,并且还会损害每个智能体的本地行为策略的隐私。本文提出了一个联合强化学习框架,其中多个智能体协作学习一个全局模型,而不共享各自的数据和策略。每个智能体都维护模型的本地副本,并使用本地采样数据更新它。本文提出了关于策略TD、非策略TD和Q-learning的联合版本,并分析了它们的收敛性。对于所有这些算法,本文是第一个考虑马尔可夫噪声和多次局部更新的算法,并证明了相对于智能体数量的线性收敛加速。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢