

论文标题:
Pro-KD: Progressive Distillation by Following the Footsteps of the Teacher
论文链接:
https://arxiv.org/abs/2110.08532
导读
随着神经模型规模的不断扩大,知识蒸馏作为模型压缩的重要工具收到越来越多的关注。知识蒸馏在一般的分类交叉熵以外加入一个额外的损失项,来鼓励学生模型模仿教师模型的 soft target 输出。相较于 ground-truth 标签,前者能提供更多的概率分布信息,从而提供更多的知识给学生模型。
尽管知识蒸馏在多个任务上取得了成功,然而仍然存在两个问题:
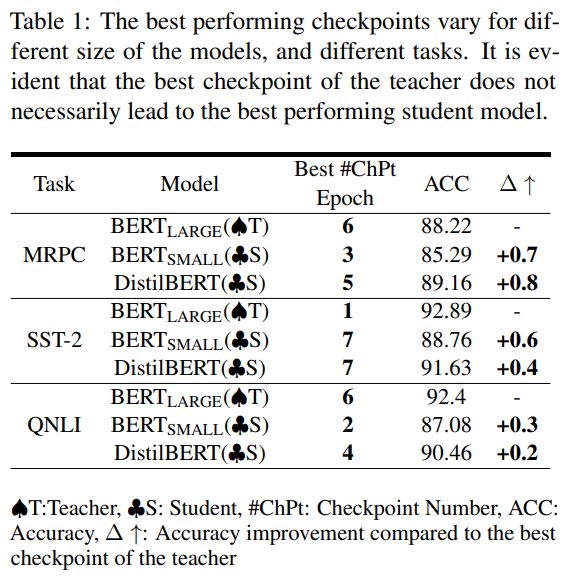
- 检查点搜索问题:表现最好的教师模型checkpoint不一定是最适合蒸馏的教师,early-stopped checkpoint 没准反而是更好的教师模型。但搜索全部 checkpoint 非常耗时耗力,很难获取到最优的 checkpoint;下表展示了 BERT 系模型在不同数据集上的最优 checkpoint:
- 容量差距问题:随着参数量的增大,预训练语言模型一般会表现更好。但很多研究表明,教师模型并不是越大越好,因为蒸馏效果会随着教师模型和学生模型之间容量差距增大而降低。Mirzadeh 等人 [1]提出了 TA-KD,额外训练“助教”模型,学习教师模型的输出,再指导学生模型训练,有效缓解了容量差距问题,但训练中间网络会增加训练时间和计算量,同时还会导致误差累积。在本文中,作者提出了渐进式知识蒸馏(Pro-KD)技术来解决以上两个问题。在 Pro-KD 中,作者假设教师模型的训练路径可以为学生模型提供额外知识信息,所以通过学生模型与教师模型共同训练,可以提升学生模型表现;此外,为了使学生的训练更加顺利,不受容量差距影响,作者受 Jafari 等人 [2]工作的启发,将自适应温度因子应用于教师的输出,并在训练过程中逐步减小该因子。
作者通过对 NLP(GLUE 基准和 SQuAD 1.1 和 2.0)和图像分类任务(CIFAR-10、CIFAR-100)的实验,表明了 Pro-KD 的有效性。
方法
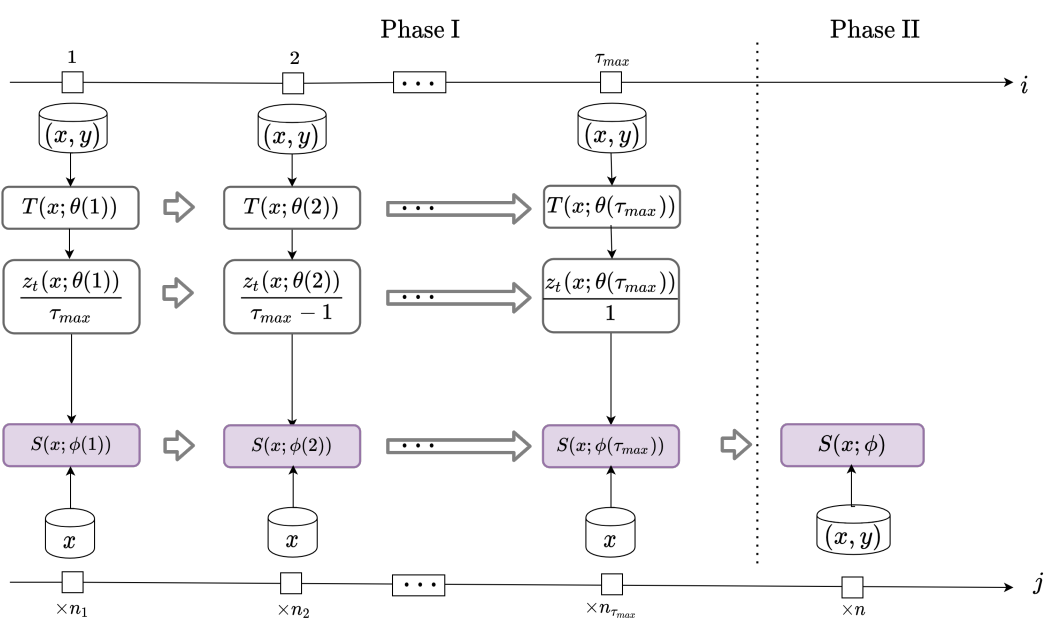
本文提出了 Pro-KD 方法,共分为两个阶段。第一阶段,学生模型仅由自适应平滑版本的教师模型监督训练;第二阶段,学生模型只接受 ground-truth 标签训练。
2.1 General Step-by-Step Training with a Teacher
在第一阶段,学生模型和教师模型共同训练。在第i个 epoch 开始时,设教师模型参数为θ(i)。教师模型首先根据训练数据交叉熵损失进行参数优化:
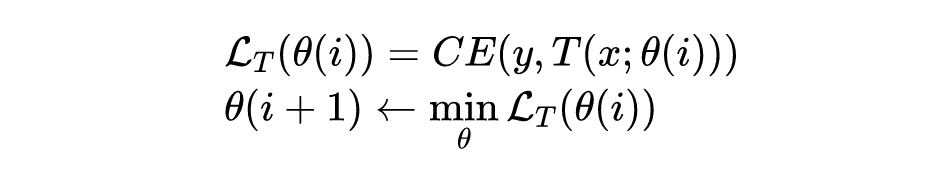
然后,教师模型来监督学生模型训练。与传统蒸馏类似,学生模型学习教师模型的 soft-label 输出,也即输出 logit 的平滑版本:
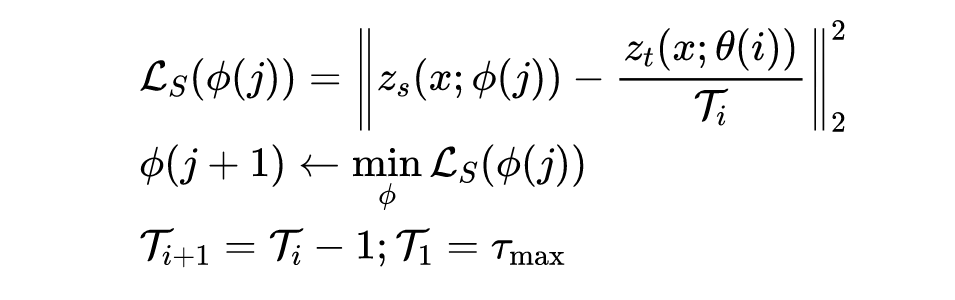
其中,zs,zt分别为学生模型和教师模型的输出 logit,Φ(j)表示学生模型第j个 epoch 的损失函数,Ti为当前 epoch 的温度因子。每个 epoch 减少1,直到T=1为止,其目的是为了让教师模型的输出更流畅,有益于缓解容量差距问题。
考虑到教师模型通常训练周期比学生模型短,所以对于教师模型的第i个 epoch,学生模型可以训练ni个epoch。τmax是训练中的一个超参数,用于控制教师模型的总训练周期数。
2.2 Training with the Ground-Truth Labels
在第二阶段,学生模型则直接在真实标签上进行训练:
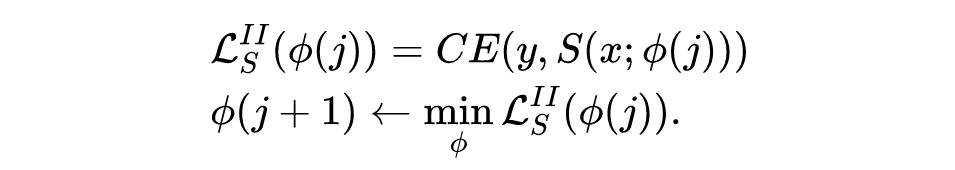
该阶段与一般的 fine-tune 训练基本相同,不再赘述。综上所述,Pro-KD 方法如下图所示。
实验
3.1 Setup
在本节中,作者分别在图像分类、自然语言理解和问答任务上进行了三组实验,来评估 Pro-KD 性能。在所有这三个实验中,作者都将 Pro-KD 与最先进的技术进行了比较,例如 TA-KD [1]、Annealing-KD [2] 和 RCO [3] 技术等 baseline。针对图像分类任务,作者选取了 CIFAR-10 和 CIFAR-100 [4] 数据集,均包含60000个32*32有色图像和10个类别。利用 ResNet-8 和 resNet-110 分别作为学生模型和教师模型。
针对自然语言理解任务,作者选取了 GLUE benchmark 上的 个任务,分别采用 RoBERTa-large-24 layer/DistilRoBERTa-6 layer 和 BERT-base-12 layer/BERT-small-4 layer 两个教师-学生模型对进行了实验。
针对问答任务,作者选取了 SQuAD v1.1/v2.0 数据集,包括 个 QA 对。采用了与自然语言理解任务相同的两个教师-学生模型对进行了实验。
3.2 Results
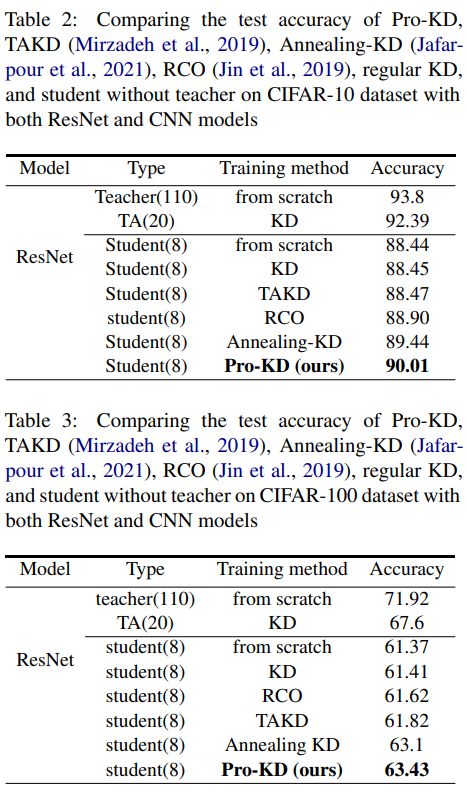
图像分类任务结果如下两表所示,Pro-KD 在两个数据集上均打败了其他的 baseline。
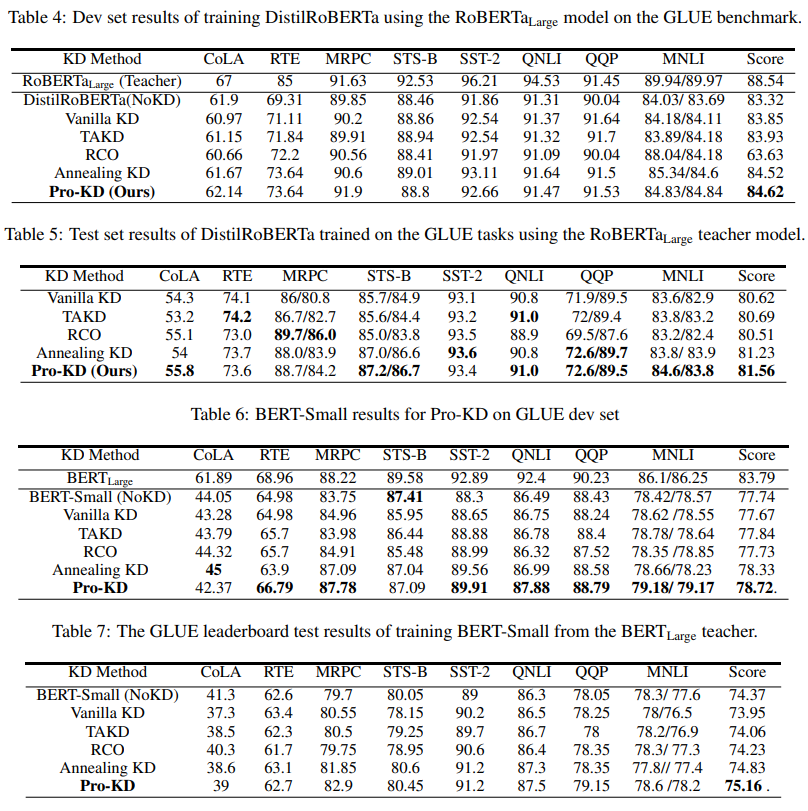
下面的四个表格里,作者列举了自然语言理解任务上学生模型的 dev set 和 test set 结果。
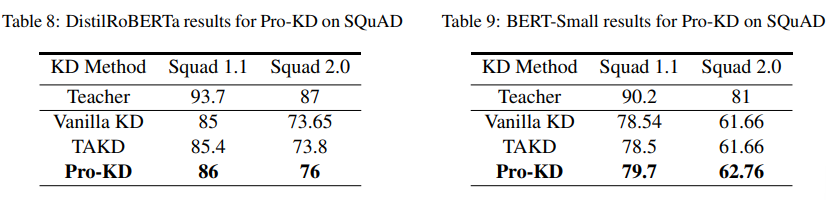
问答任务的实验结果如下表所示,Pro-KD 仍然优于当下最好的 baseline。
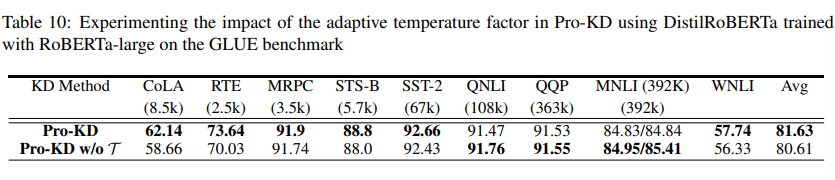
3.3 Ablation Studies of the Temperature Factor
作者还对温度因子进行了消融实验,如下表所示。当取消温度因子(也即 时)后,Pro-KD 方法在 GLUE benchmark 上的综合表现有所下降,说明自适应温度因子有助于学生模型在训练前期更容易模拟教师模型的 soft label 输出。
在本文中,作者针对传统知识蒸馏中遇到的容量差距问题和检查点搜索问题进行了分析,同时提出了 Pro-KD 蒸馏方法,为学生模型提供了一个更加顺畅的训练路线,而并非原有的直接学习成熟的教师模型。在图像分类、NLP 语言理解和问答任务上均获得了比现有 benchmark 更优的表现。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢