
特征筛选是建模过程中的重要一环。
基于决策树的算法,如 Random Forest,Lightgbm, Xgboost,都能返回模型默认的 Feature Importance,但诸多研究都表明该重要性是存在偏差的。
是否有更好的方法来筛选特征呢?Kaggle 上很多大师级的选手通常采用的一个方法是 Permutation Importance。这个想法最早是由 Breiman(2001)[1] 提出,后来由 Fisher,Rudin,and Dominici(2018)改进 [2]。
通过本文,你将通过一个 Kaggle Amex 真实数据了解到,模型默认的 Feature Importance 存在什么问题,什么是 Permutation Importance,它的优劣势分别是什么,以及具体代码如何实现和使用。
本文完整代码:https://github.com/Qiuyan918/Permutation_Importance_Experiment
另外,本文代码使用 GPU 来完成 dataframe 的处理,以及 XGB 模型的训练和预测。相较于 CPU 的版本,可以提升 10 到 100 倍的速度。具体来说,使用 RAPIDS 的 CUDF 来处理数据。训练模型使用 XGB 的 GPU 版本,同时使用 DeviceQuantileDMatrix 作为 dataloader 来减少内存的占用。做预测时,则使用 RAPIDS 的 INF。
模型默认的Feature Importance存在什么问题?
Strobl et al [3] 在 2007 年就提出模型默认的 Feature Importance 会偏好连续型变量或高基数(high cardinality)的类型型变量。这也很好理解,因为连续型变量或高基数的类型变量在树节点上更容易找到一个切分点,换言之更容易过拟合。
另外一个问题是,Feature Importance 的本质是训练好的模型对变量的依赖程度,它不代表变量在 unseen data(比如测试集)上的泛化能力。特别当训练集和测试集的分布发生偏移时,模型默认的 Feature Importance 的偏差会更严重。
举一个极端的例子,如果我们随机生成一些 X 和二分类标签 y,并用 XGB 不断迭代。随着迭代次数的增加,训练集的 AUC 将接近 1,但是验证集上的 AUC 仍然会在 0.5 附近徘徊。这时模型默认的 Feature Importance 仍然会有一些变量的重要性特别高。这些变量帮助模型过拟合,从而在训练集上实现了接近 1 的 AUC。但实际上这些变量还是无意义的。
什么是Permutation Importance?
Permutation Importance 是一种变量筛选的方法。它有效地解决了上述提到的两个问题。
Permutation Importance 将变量随机打乱来破坏变量和 y 原有的关系。如果打乱一个变量显著增加了模型在验证集上的loss,说明该变量很重要。如果打乱一个变量对模型在验证集上的 loss 没有影响,甚至还降低了 loss,那么说明该变量对模型不重要,甚至是有害的。
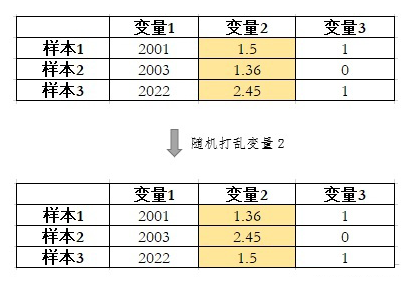
▲ 打乱变量示例
变量重要性的具体计算步骤如下:
- 将数据分为 train 和 validation 两个数据集
- 在 train 上训练模型,在 validation 上做预测,并评价模型(如计算 AUC)
- 循环计算每个变量的重要性:
- (1) 在 validation 上对单个变量随机打乱;
- (2)使用第 2 步训练好的模型,重新在 validation 做预测,并评价模型;
- (3.3)计算第 2 步和第 3.2 步 validation 上模型评价的差异,得到该变量的重要性指标
Python 代码步骤(model 表示已经训练好的模型):
def permutation_importances(model, X, y, metric):
baseline = metric(model, X, y)
imp = []
for col in X.columns:
save = X[col].copy()
X[col] = np.random.permutation(X[col])
m = metric(model, X, y)
X[col] = save
imp.append(baseline - m)
return np.array(imp)内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢