
图像生成模型卷起来了!视频生成模型卷起来了!
下一个,便是音频生成模型。

近日,谷歌研究团队推出了一种语音生成的AI模型——AudioLM。
只需几秒音频提示,它不仅可以生成高质量,连贯的语音,还可以生成钢琴音乐。

论文地址:https://arxiv.org/pdf/2209.03143.pdf
AudioLM是一个具有长期一致性的高质量音频生成框架,将输入的音频映射为一串离散的标记,并将音频生成任务转化为语言建模任务。
现有的音频标记器在音频生成质量和稳定的长期结构之间必须做出权衡,无法兼顾。
为了解决这个矛盾,谷歌采用「混合标记化」方案,利用预训练好的掩膜语言模型的离散化激活,并利用神经音频编解码器产生的离散代码来实现高质量的合成。
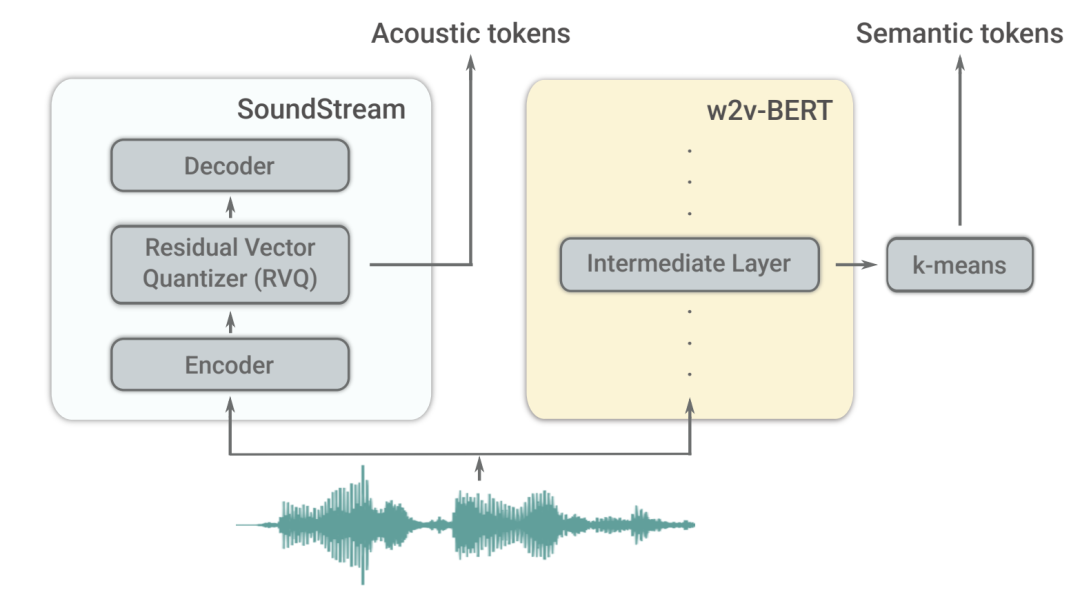
AudioLM模型可以基于简短的提示,学习生成自然和连贯的连续词,当对语音进行训练时,在没有任何记录或注释的情况下,生成了语法上通顺、语义上合理的连续语音,同时保持说话人的身份和语调。
除了语音之外,AudioLM还能生成连贯的钢琴音乐,甚至不需要在任何音乐符号来进行训练。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢