

近年来,基于深度学习的图像降噪/去模糊的算法,在图像恢复领域取得了显著的进展。但与此同时,这些方法的系统复杂度相应的也在上升,如图1. 所示。
由此自然产生了一个问题,简单的模型是否也有可能达到最先进的性能?本文尝试回答这个问题,并给出肯定的答复。在本文中,我们先展示如何从零开始搭建一个简单同时性能优秀的基线模型,然后进一步简化该模型:我们发现甚至连传统的激活函数(如ReLU,GELU,Sigmoid等)都不是必须的:它们可以被去除或者被简单的乘法替代。
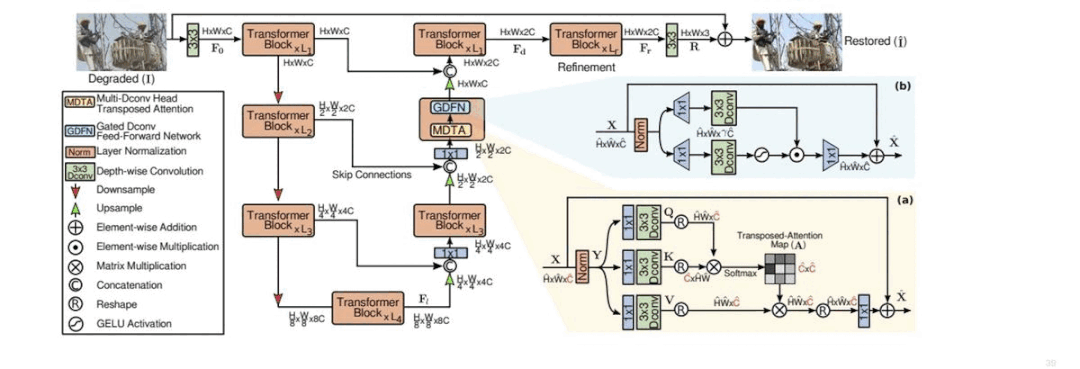
图1. 当前一些图像恢复方法
如何从零搭建简单基线
深度学习模型通常是由一些基础操作(比如卷积/激活函数等)组合而成的模块(block)堆叠在一起构成的。我们先讨论堆叠模块的方式,然后再考虑模块内部的基础元素应该怎样选择。
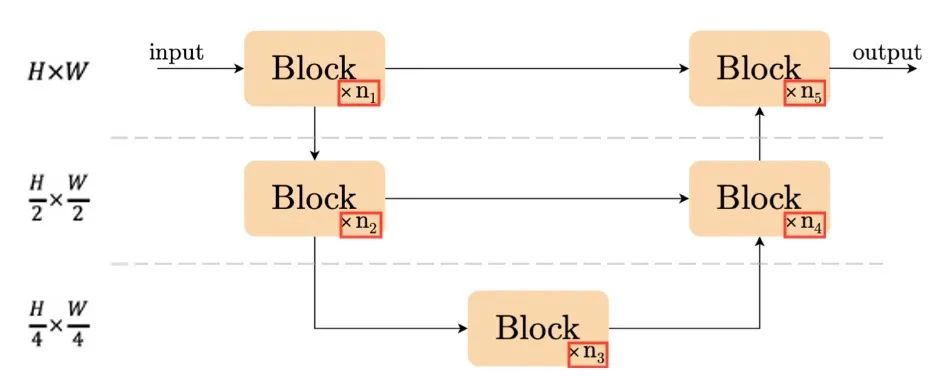
图2. UNet结构示意图
在各种深度学习方法蓬勃发展的当下,堆叠模块的方式也有许多不同方案,比如MPRNet[1]/HINet[2]等网络采用了多阶段的设计,将简单的结构串联起来;MIMO-UNet[3]等方法则考虑将各个不同空间大小的特征连接在一起。
而另一方面,我们发现简单的结构:UNet(如图2.)还是有一战之力的:当前一些性能优秀的方法[4],[5]是基于UNet或其变种。基于以上观察,我们认为UNet结构仍然是构造简单基线的不二之选。
在选定了堆叠方式之后,还有一个容易被忽略的地方,就是堆叠模块的数量。为了确定此选项,我们通过模块的数量这一条线,回顾近年来图像恢复模型的发展。DeepDeblur[6] 发现将Normalization去除之后性能更优,而后续的一些方法如NBNet[7]等也使用了这样的设置,其包含9个模块。我们猜测可能是因为去除了Normalization从而使得图像恢复模型在深度增加时难以稳定训练。
去年5月份,HINet[2]则重新引入了Instance Normalization从而支持18个模块的训练。另一方面, transformer在高层视觉领域的流行也影响到了底层视觉领域,如UFormer[4](包含 18个模块), Restormer[5](进一步将模块数增加到了44个)。有证据表明,深度(或者说模块数)的增加是近期图像恢复模型性能提升的重要原因,所以我们选择了36个模块作为模型的默认配置。
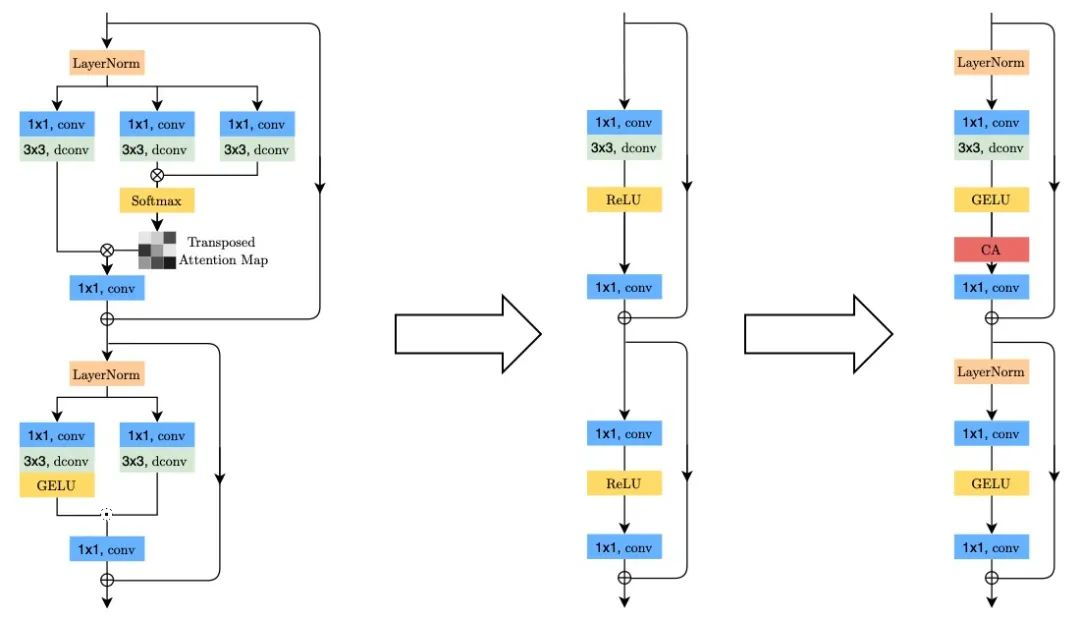
图3.
左箭头:简化Restormer[5]从而获得初始结构。
右箭头:初始结构增加必要内容构成简单基线。
论文:https://arxiv.org/abs/2204.04676
代码:https://github.com/megvii-research/NAFNet/
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢