
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:基于屏幕截图解析的视觉语言理解预训练、衡量和缩小语言模型的组合性差距、基于非侵入性脑记录的连续语言语义重建、引导扩散模型蒸馏研究、基于局部损失的前向梯度扩展、面向人脸识别的百万数字人脸图像、通过习语理解Transformer记忆召回、物理机器人高速精准乒乓球学习、规则学习对宽神经网络表征动力学的影响
1、[CL] Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
K Lee, M Joshi, I Turc, H Hu, F Liu, J Eisenschlos, U Khandelwal, P Shaw, M Chang, K Toutanova
[Google Research]
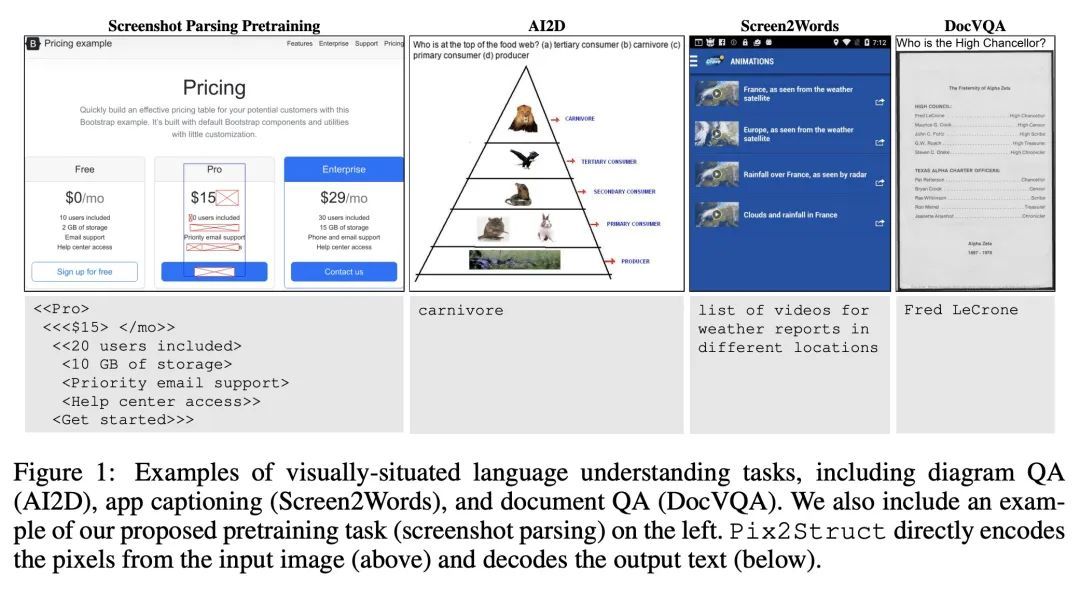
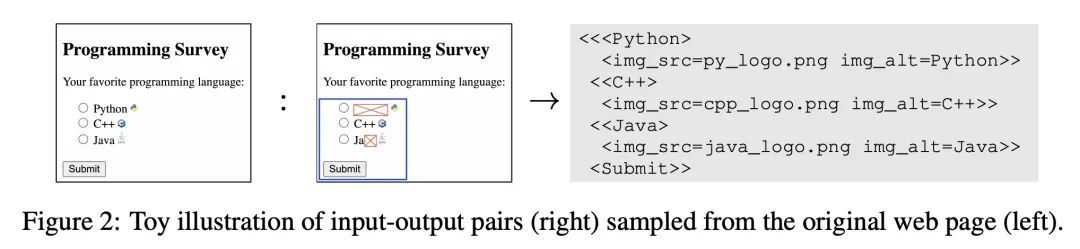
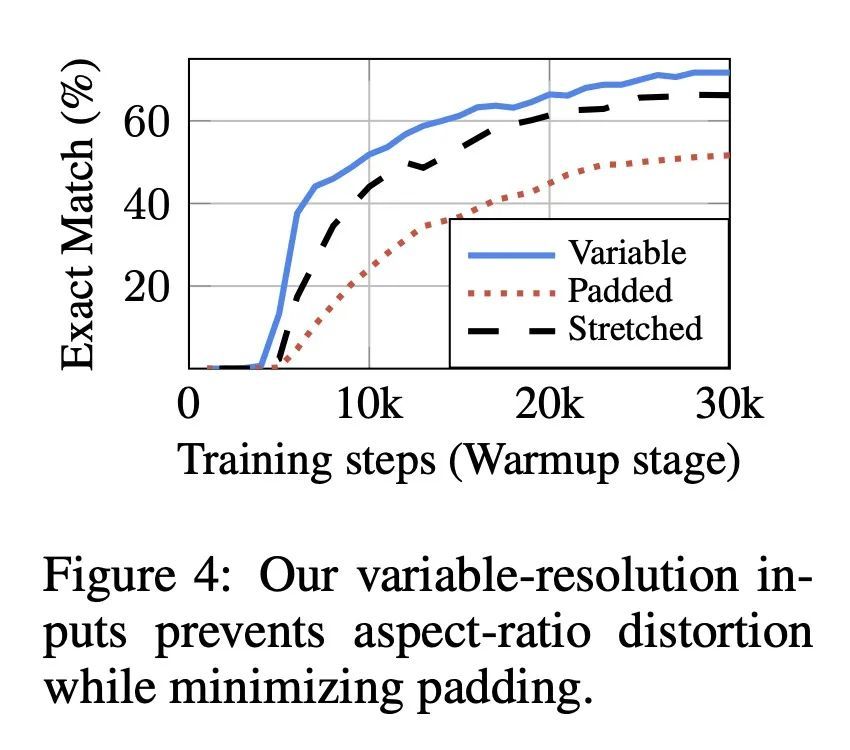
Pix2Struct: 基于屏幕截图解析的视觉语言理解预训练。视觉语言无处不在——来源包括从带有图表的教科书到带有图像和表格的网页,再到带有按钮和表格的移动应用。也许是由于这种多样性,之前的工作通常依赖于特定领域的方案,对基础数据、模型架构和目标的分享有限。本文提出Pix2Struct,一种用于纯视觉语言理解的预训练图像-文本模型,可以在包含视觉语言的任务中进行微调。Pix2Struct通过学习将网页的掩码截图解析为简化HTML来进行预训练。网络具有丰富的视觉元素,可以清晰地反映在HTML结构中,提供了大量的预训练数据,非常适合于下游任务的多样性。直观地说,该目标包含了常见的预训练信号,如OCR、语言建模、图像描述。除了新的预训练策略外,本文还引入了一个可变分辨率的输入表示法和一个更灵活的语言-视觉输入整合,其中语言提示,如问题,直接呈现在输入图像之上。本文首次表明,单一的预训练模型可以在四个领域的九个任务中的六个任务中取得最先进的结果:文档、插图、用户界面和自然图像。
Visually-situated language is ubiquitous -- sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and forms. Perhaps due to this diversity, previous work has typically relied on domain-specific recipes with limited sharing of the underlying data, model architectures, and objectives. We present Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy, we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions are rendered directly on top of the input image. For the first time, we show that a single pretrained model can achieve state-of-the-art results in six out of nine tasks across four domains: documents, illustrations, user interfaces, and natural images.
https://arxiv.org/abs/2210.03347

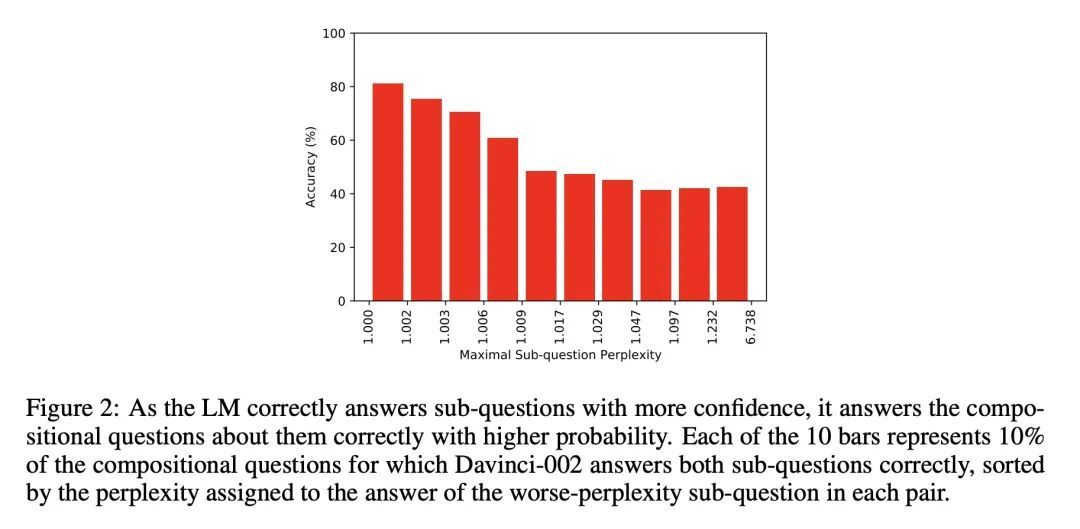
2、[CL] Measuring and Narrowing the Compositionality Gap in Language Models
O Press, SM Muru Zhang, L Schmidt, NA Smith…
[University of Washington & Meta AI Research]
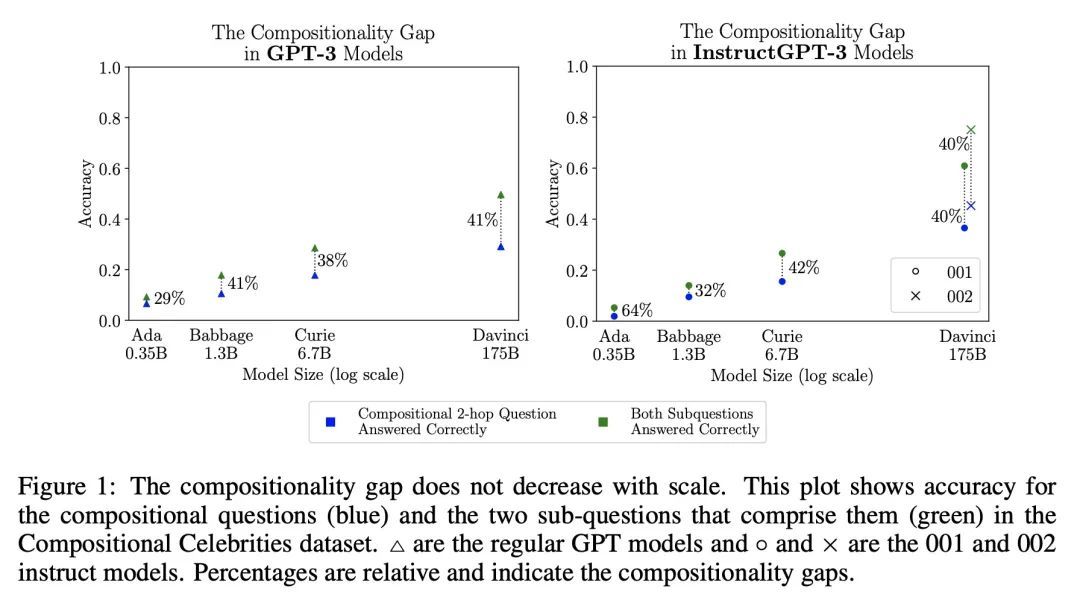
衡量和缩小语言模型的组合性差距。本文研究了语言模型执行组合推理任务的能力,其中整体解决方案取决于对子问题答案的正确组合。本文衡量模型能够正确回答所有子问题但不能产生整体解决方案的频率,这个比率称为组合性差距。通过询问多跳问题来评估该比率,这些问题的答案需要由多个不太可能在预训练中一起观察到的事实组成。在GPT-3系列模型中,随着模型规模的增加,发现单跳问题的回答性能比多跳性能提高得更快,因此组合性差距并没有减少。这个令人惊讶的结果表明,虽然更强大的模型能够记忆和回忆更多的事实性知识,但它们在进行这种组合性推理的能力方面没有显示出相应的改进。本文展示了引导性提示(如思维链)是如何通过显性推理而不是隐性推理来缩小组成性差距的。本文提出一种新方法,即自问(self-ask),进一步改善了思维链。在该方法中,模型在回答最初的问题之前明确地问自己(然后回答)后续问题。自问的结构化提示使得可以很容易地插入一个搜索引擎来回答后续问题,从而进一步提高准确性。
We investigate the ability of language models to perform compositional reasoning tasks where the overall solution depends on correctly composing the answers to sub-problems. We measure how often models can correctly answer all subproblems but not generate the overall solution, a ratio we call the compositionality gap. We evaluate this ratio by asking multi-hop questions with answers that require composing multiple facts unlikely to have been observed together during pretraining. In the GPT-3 family of models, as model size increases we show that the single-hop question answering performance improves faster than the multihop performance does, therefore the compositionality gap does not decrease. This surprising result suggests that while more powerful models memorize and recall more factual knowledge, they show no corresponding improvement in their ability to perform this kind of compositional reasoning. We then demonstrate how elicitive prompting (such as chain of thought) narrows the compositionality gap by reasoning explicitly instead of implicitly. We present a new method, self-ask, that further improves on chain of thought. In our method, the model explicitly asks itself (and then answers) follow-up questions before answering the initial question. We finally show that self-ask’s structured prompting lets us easily plug in a search engine to answer the follow-up questions, which additionally improves accuracy.1
https://ofir.io/self-ask.pdf


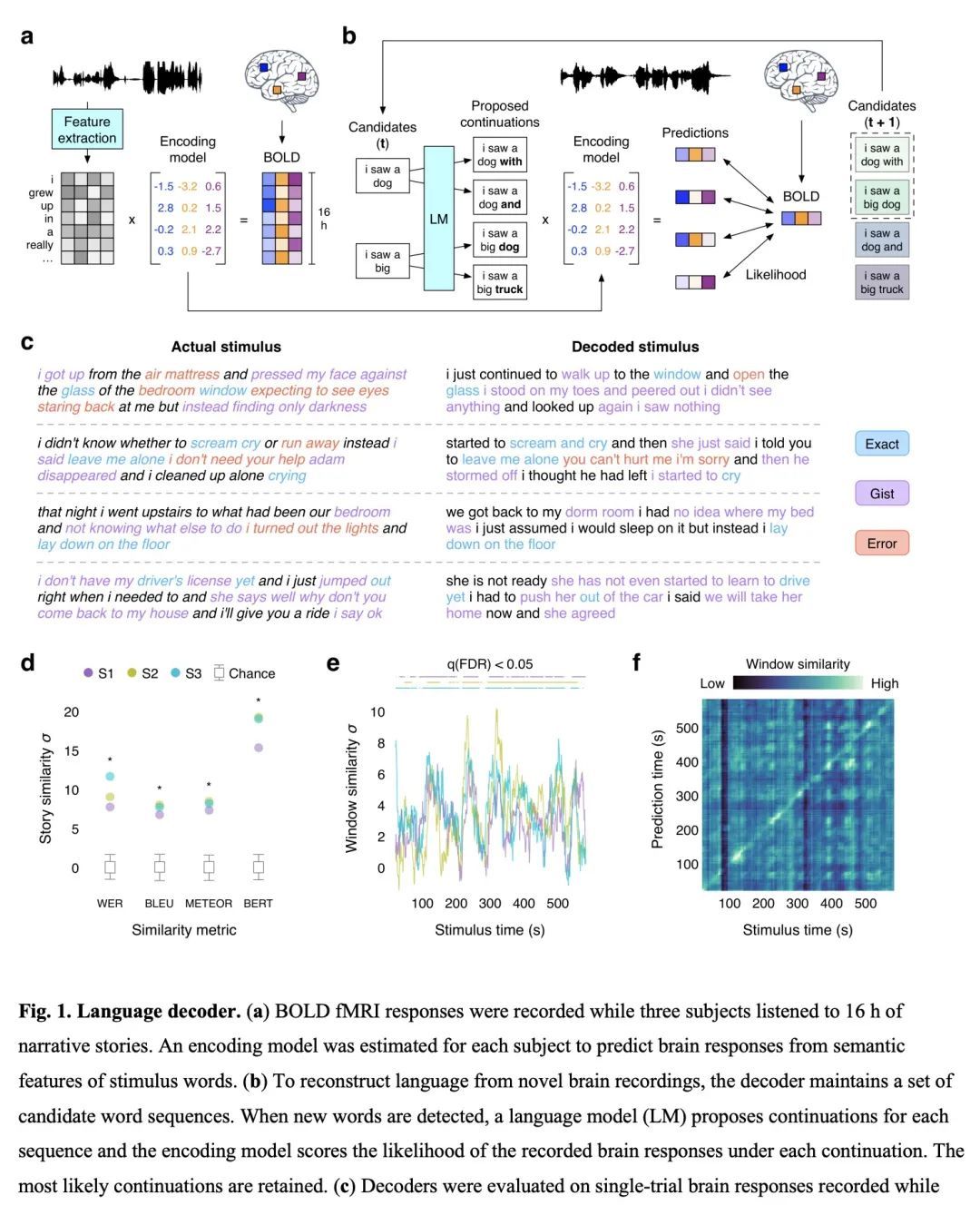
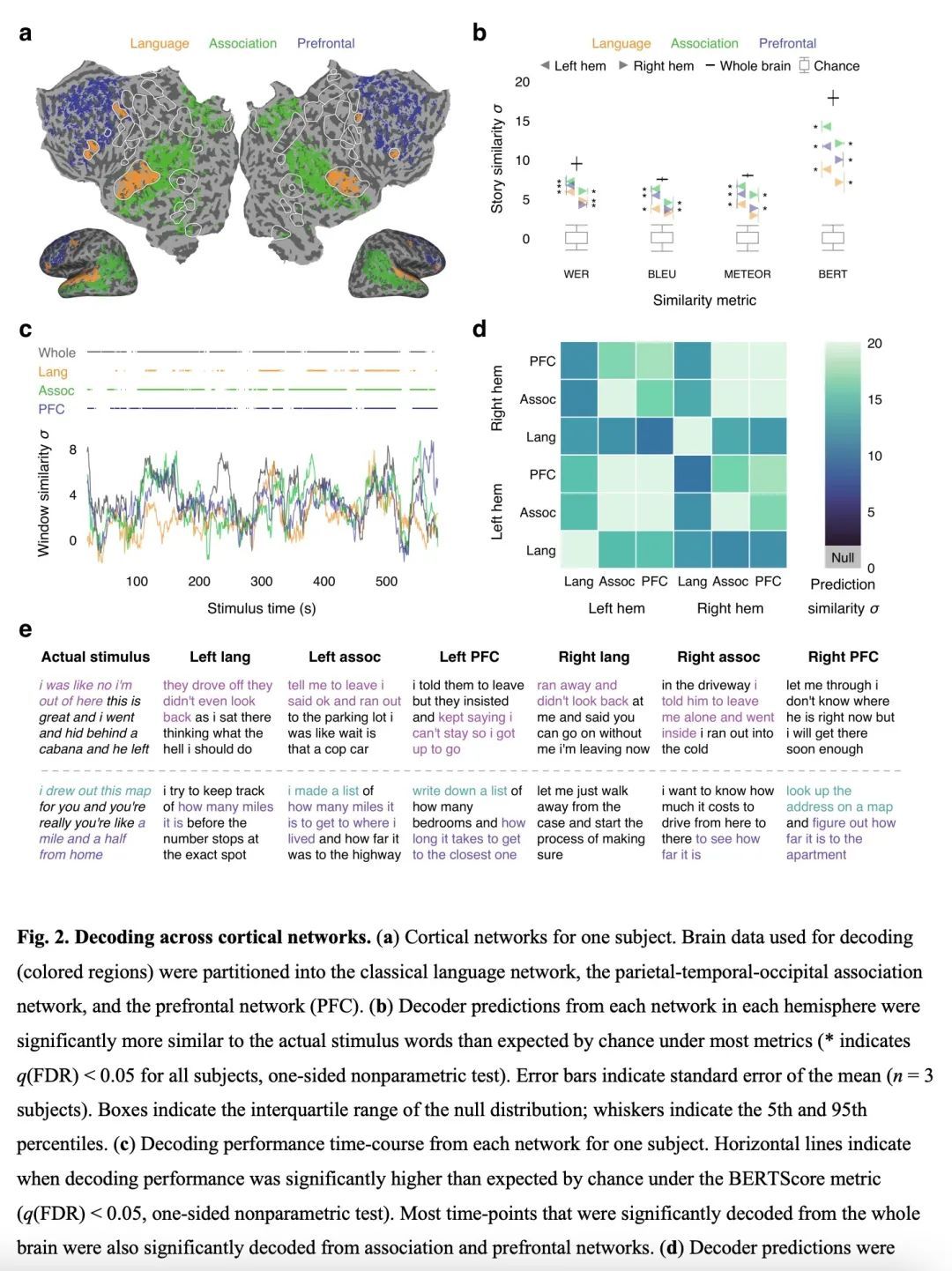
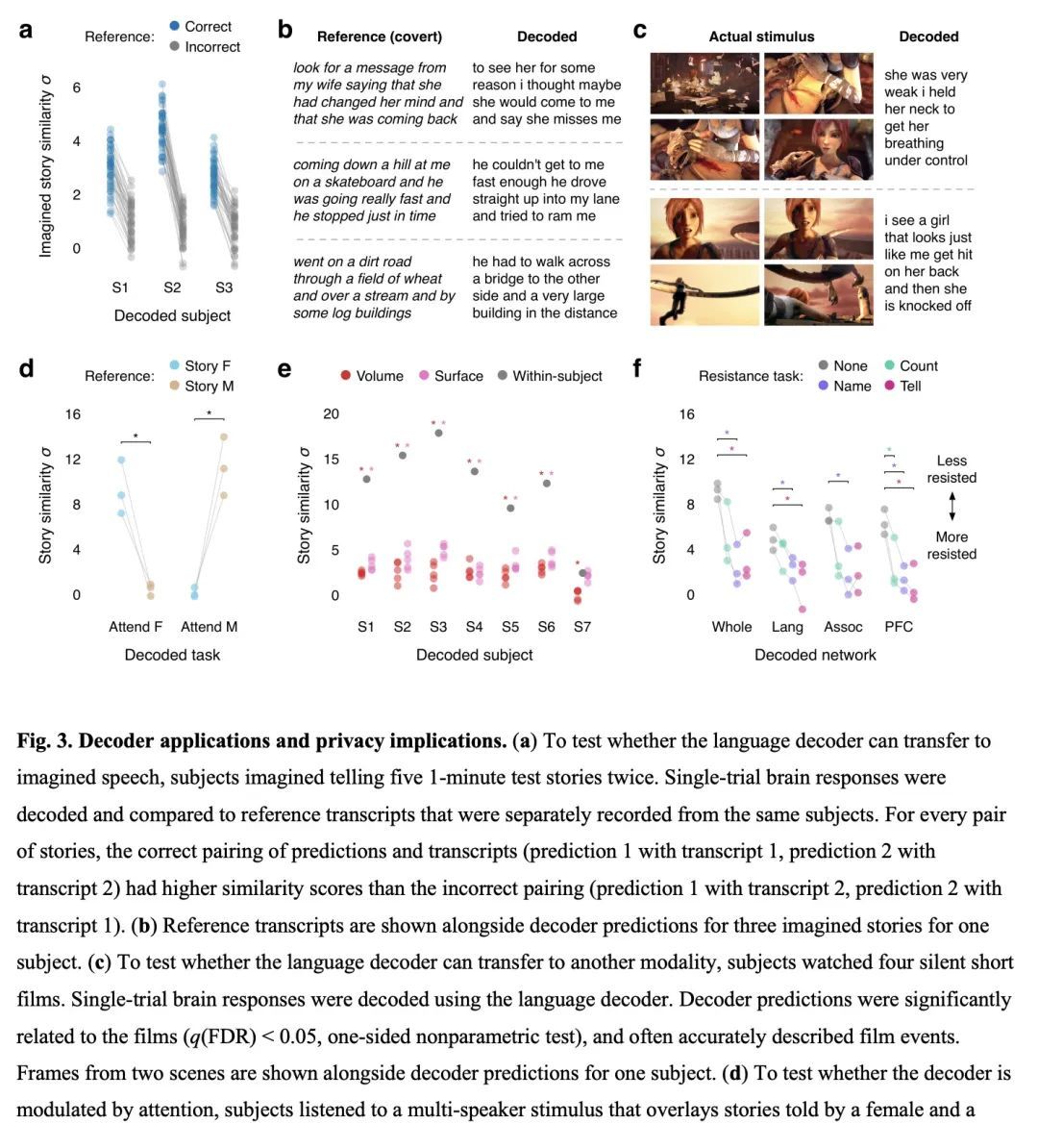
3、[LG] Semantic reconstruction of continuous language from non-invasive brain recordings
J Tang, A LeBel, S Jain, AG Huth
[The University of Texas at Austin]
基于非侵入性脑记录的连续语言语义重建。从非侵入性记录中解码连续语言的脑机接口将有许多科学和实际应用。然而,目前重建连续语言的解码器用的是手术植入电极的侵入性记录,而使用非侵入性记录的解码器只能从一小部分字母、单词或短语中识别刺激反应。本文提出一种非侵入性解码器,能从用功能磁共振成像(fMRI)记录的语义的皮质表征中重建连续的自然语言。考虑到新的脑记录,该解码器产生了可理解的单词序列,恢复了感知到的语音、想象中的语音,甚至是无声视频的意义,证明了单一语言解码器可用于一系列语义任务。为了研究语言是如何在整个大脑中表示的,本文在不同的皮质网络上测试了解码器,发现自然语言可以从每个半球的多个皮质网络中分别进行解码。由于脑机接口应尊重心理隐私,本文测试了成功解码是否需要主体合作,并发现主体合作在训练和应用解码器时都是需要的。本文研究表明,连续的语言可以从非侵入性的大脑记录中解码,从而使未来的多用途脑机接口成为可能。
A brain-computer interface that decodes continuous language from non-invasive recordings would have many scientific and practical applications. Currently, however, decoders that reconstruct continuous language use invasive recordings from surgically implanted electrodes(1–3), while decoders that use non-invasive recordings can only identify stimuli from among a small set of letters, words, or phrases(4–7). Here we introduce a non-invasive decoder that reconstructs continuous natural language from cortical representations of semantic meaning(8) recorded using functional magnetic resonance imaging (fMRI). Given novel brain recordings, this decoder generates intelligible word sequences that recover the meaning of perceived speech, imagined speech, and even silent videos, demonstrating that a single language decoder can be applied to a range of semantic tasks. To study how language is represented across the brain, we tested the decoder on different cortical networks, and found that natural language can be separately decoded from multiple cortical networks in each hemisphere. As brain-computer interfaces should respect mental privacy(9), we tested whether successful decoding requires subject cooperation, and found that subject cooperation is required both to train and to apply the decoder. Our study demonstrates that continuous language can be decoded from non-invasive brain recordings, enabling future multipurpose brain-computer interfaces.
https://biorxiv.org/content/10.1101/2022.09.29.509744v1

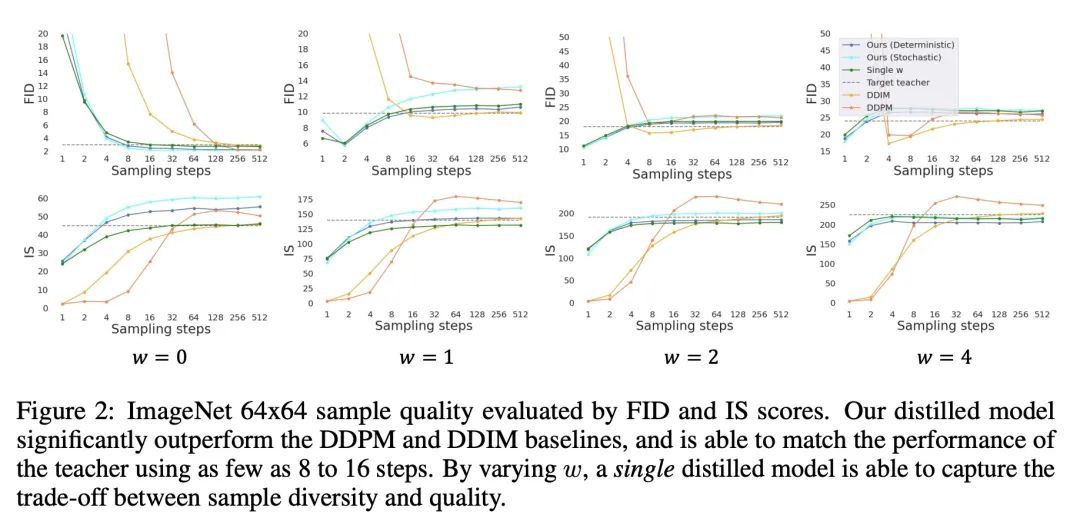
4、[CV] On Distillation of Guided Diffusion Models
C Meng, R Gao, D P. Kingma, S Ermon, J Ho, T Salimans
[Stanford University & Google Research]
引导扩散模型蒸馏研究。最近,无分类的引导扩散模型被证明在高分辨率图像生成方面非常有效,其被广泛用于大规模扩散框架,包括DALL-E 2、GLIDE和Imagen。然而,无分类指导的扩散模型的一个缺点是,其在推理时的计算成本很高,因为需要评估两个扩散模型,一个类别条件模型和一个无条件模型,需要数百次。为了解决该问题,本文提出一种将无分类指导的扩散模型蒸馏成快速采样模型的方法:给定一个预训练好的无分类指导模型,首先学习一个单一模型来匹配合并的条件模型和无条件模型的输出,然后逐步将这个模型蒸馏成一个需要更少采样步骤的扩散模型。在ImageNet 64x64和CIFAR-10上,该方法能在视觉上生成与原始模型相当的图像,只需4个采样步骤,就能获得与原始模型相当的FID/IS分数,而采样速度却高达256倍。
Classifier-free guided diffusion models have recently been shown to be highly effective at high-resolution image generation, and they have been widely used in large-scale diffusion frameworks including DALL-E 2, GLIDE and Imagen. However, a downside of classifier-free guided diffusion models is that they are computationally expensive at inference time since they require evaluating two diffusion models, a class-conditional model and an unconditional model, hundreds of times. To deal with this limitation, we propose an approach to distilling classifier-free guided diffusion models into models that are fast to sample from: Given a pre-trained classifier-free guided model, we first learn a single model to match the output of the combined conditional and unconditional models, and then progressively distill that model to a diffusion model that requires much fewer sampling steps. On ImageNet 64x64 and CIFAR-10, our approach is able to generate images visually comparable to that of the original model using as few as 4 sampling steps, achieving FID/IS scores comparable to that of the original model while being up to 256 times faster to sample from.
https://arxiv.org/abs/2210.03142



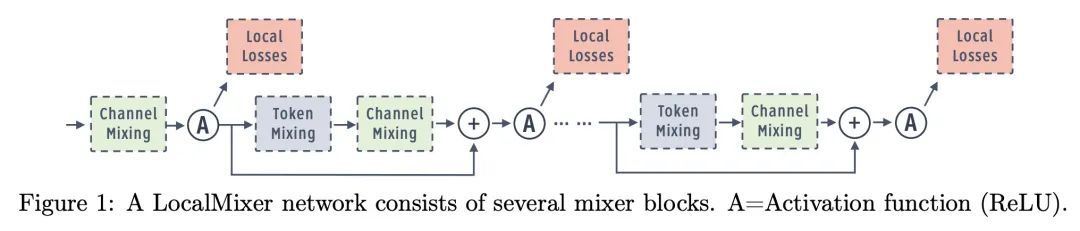
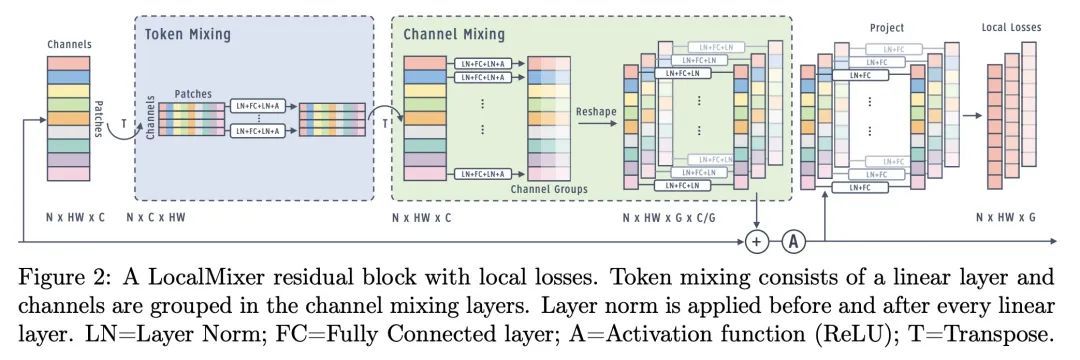
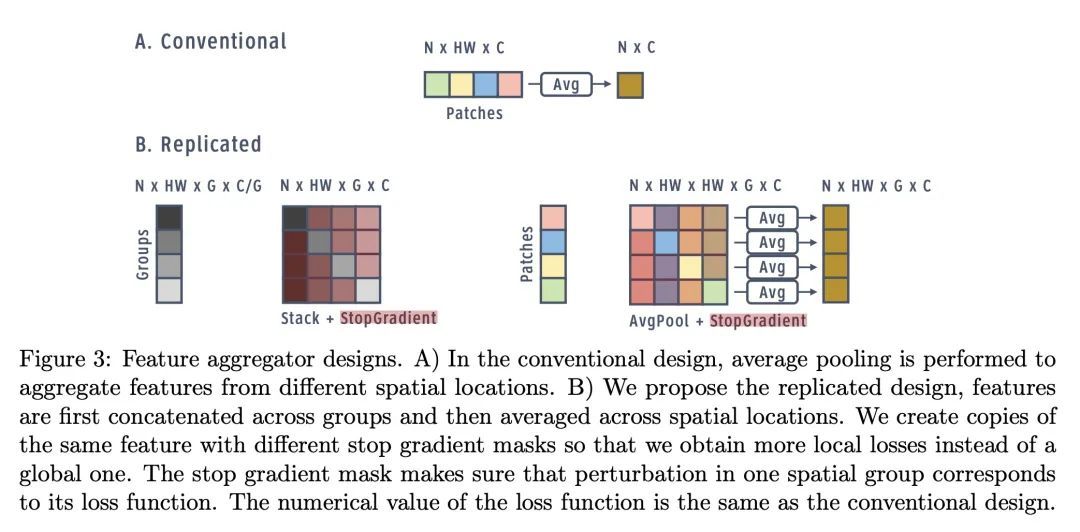
5、[LG] Scaling Forward Gradient With Local Losses
M Ren, S Kornblith, R Liao, G Hinton
[NYU & Google & UBC]
基于局部损失的前向梯度扩展。前向梯度学习计算的是一个有噪声的方向性梯度,在生物学上是一个替代反向传播深度神经网络学习的合理选择。然而,标准的前向梯度算法,当被学习的参数数量较多时,会出现高方差问题。本文提出一系列架构和算法的修改,这些修改使前向梯度学习在标准深度学习基准任务中变得实用。通过对激活而非权重进行扰动,有可能大幅降低前向梯度估计器方差。通过引入大量的局部贪婪损失函数(每个函数只涉及少量的可学习参数)和一个新的受MLPMixer启发的架构LocalMixer来进一步提高前向梯度的可扩展性,该架构更适合于局部学习。该方法在MNIST和CIFAR-10上与反向传播相匹配,并在ImageNet上明显优于之前提出的非反向传播算法。
Forward gradient learning computes a noisy directional gradient and is a biologically plausible alternative to backprop for learning deep neural networks. However, the standard forward gradient algorithm, when applied naively, suffers from high variance when the number of parameters to be learned is large. In this paper, we propose a series of architectural and algorithmic modifications that together make forward gradient learning practical for standard deep learning benchmark tasks. We show that it is possible to substantially reduce the variance of the forward gradient estimator by applying perturbations to activations rather than weights. We further improve the scalability of forward gradient by introducing a large number of local greedy loss functions, each of which involves only a small number of learnable parameters, and a new MLPMixer-inspired architecture, LocalMixer, that is more suitable for local learning. Our approach matches backprop on MNIST and CIFAR-10 and significantly outperforms previously proposed backprop-free algorithms on ImageNet.
https://arxiv.org/abs/2210.03310

另外几篇值得关注的论文:
[CV] DigiFace-1M: 1 Million Digital Face Images for Face Recognition
DigiFace-1M:面向人脸识别的百万数字人脸图像
G Bae, M d L Gorce, T Baltrusaitis, C Hewitt, D Chen, J Valentin, R Cipolla, J Shen
[University of Cambridge & Microsoft]
https://arxiv.org/abs/2210.02579




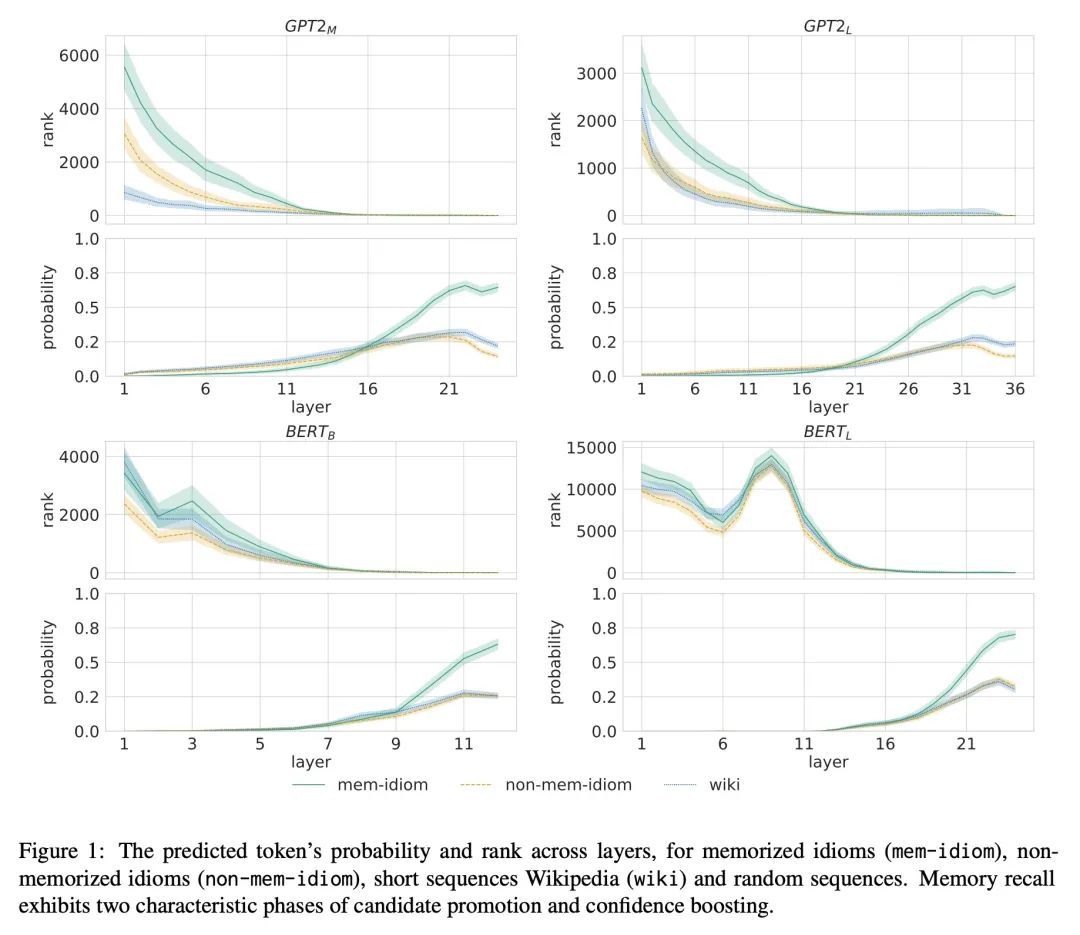
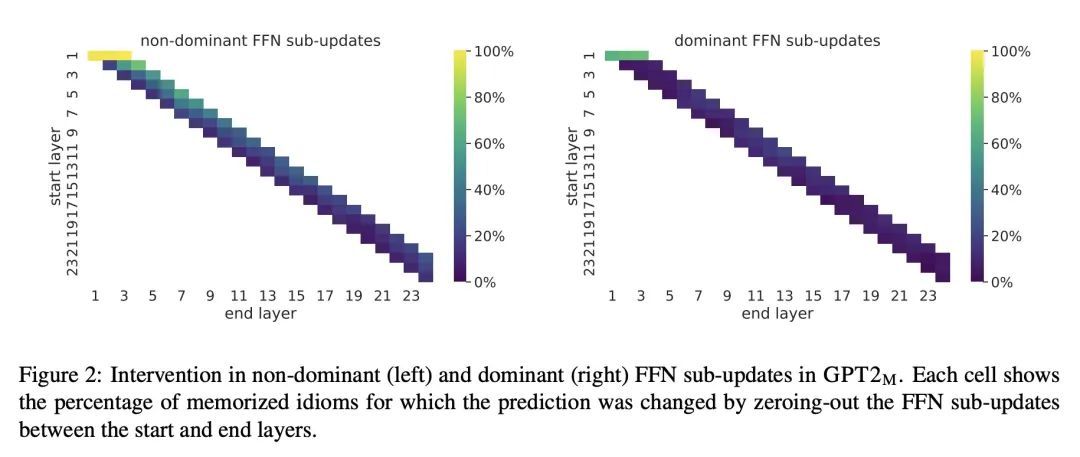
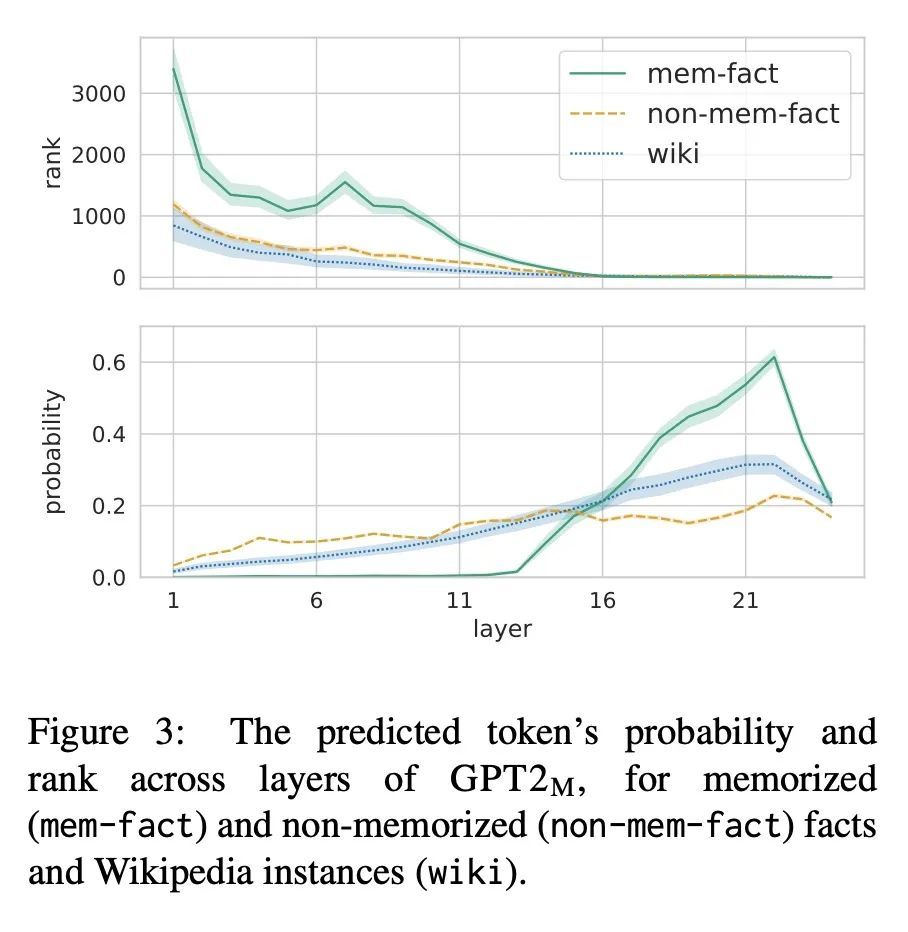
[CL] Understanding Transformer Memorization Recall Through Idioms
通过习语理解Transformer记忆召回
A Haviv, I Cohen, J Gidron, R Schuster, Y Goldberg, M Geva
[Tel Aviv University & Vector Institute for AI & Allen Institute for AI] https://arxiv.org/abs/2210.03588

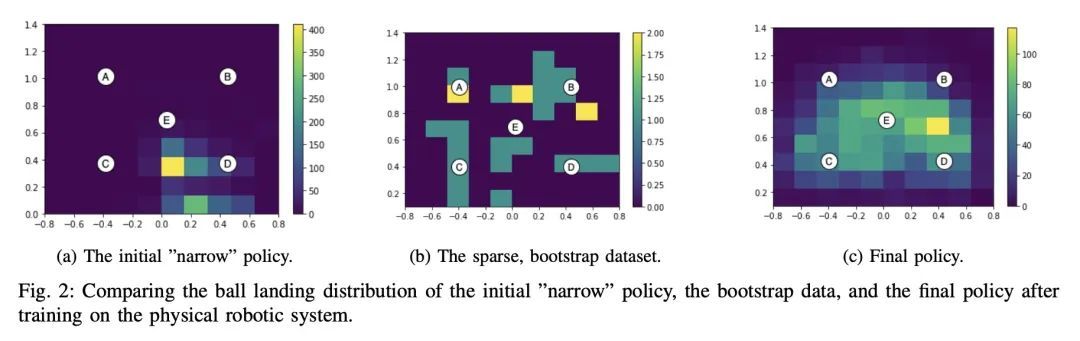
[RO] Learning High Speed Precision Table Tennis on a Physical Robot
物理机器人高速精准乒乓球学习
T Ding, L Graesser, S Abeyruwan, D B. D'Ambrosio, A Shankar, P Sermanet, P R. Sanketi, C Lynch
[Robotics at Google]
https://arxiv.org/abs/2210.03662

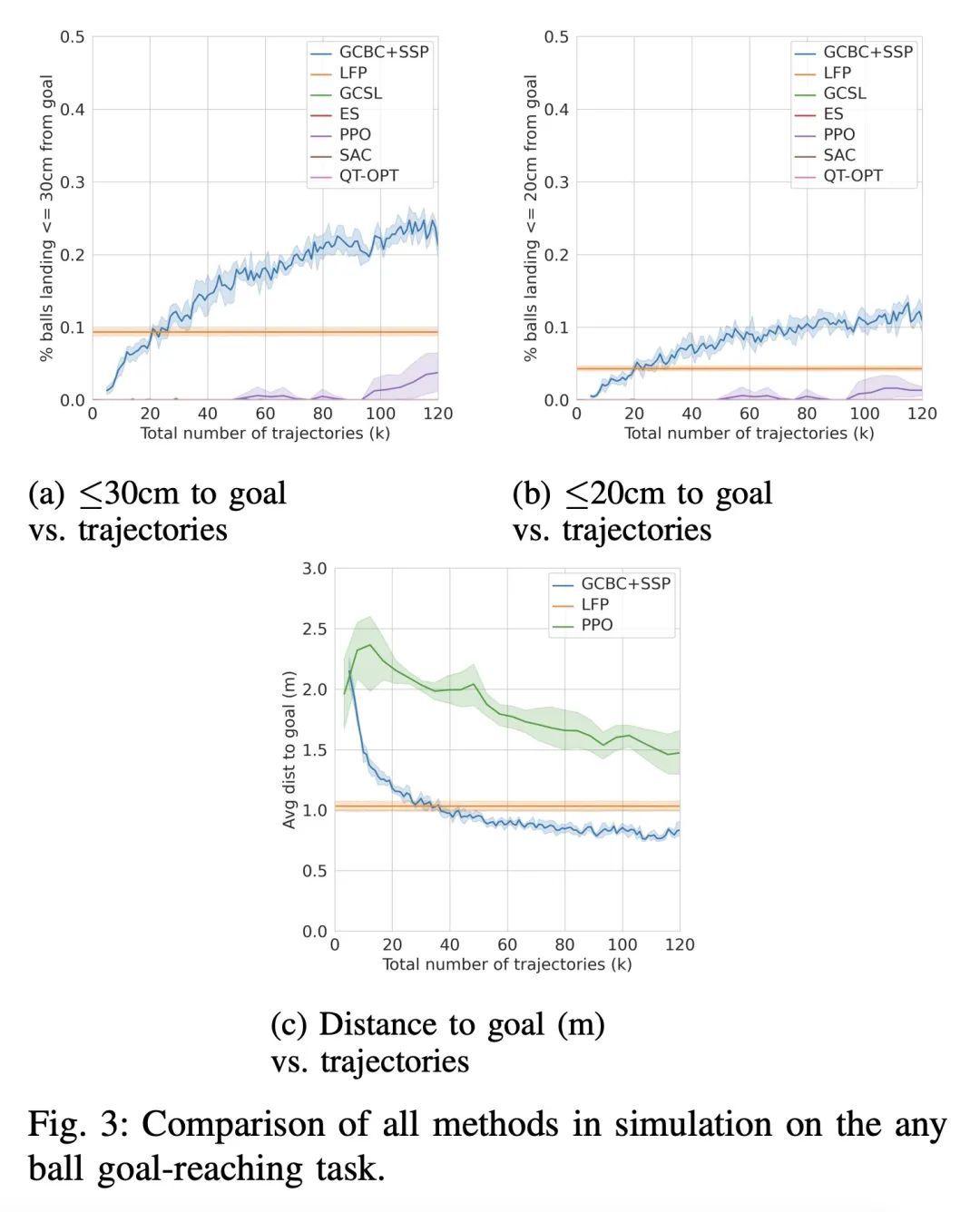
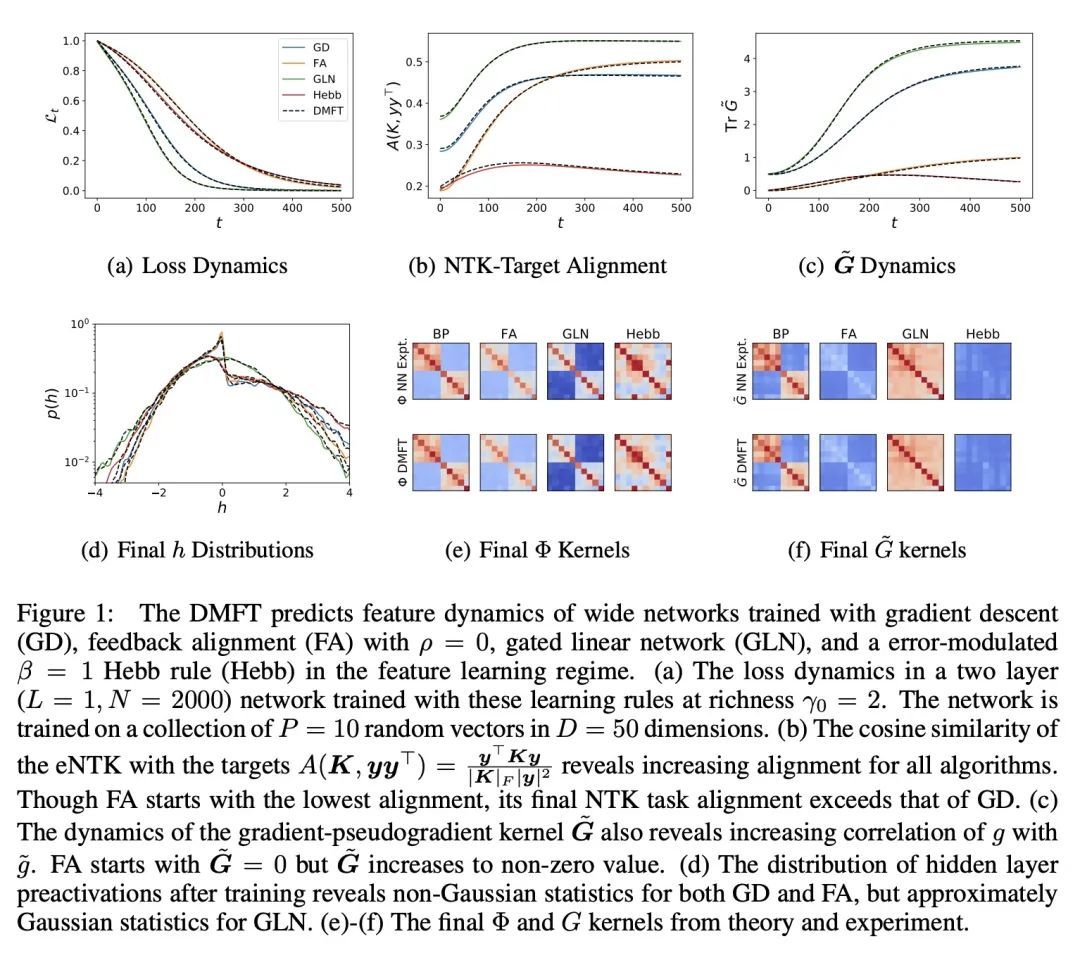
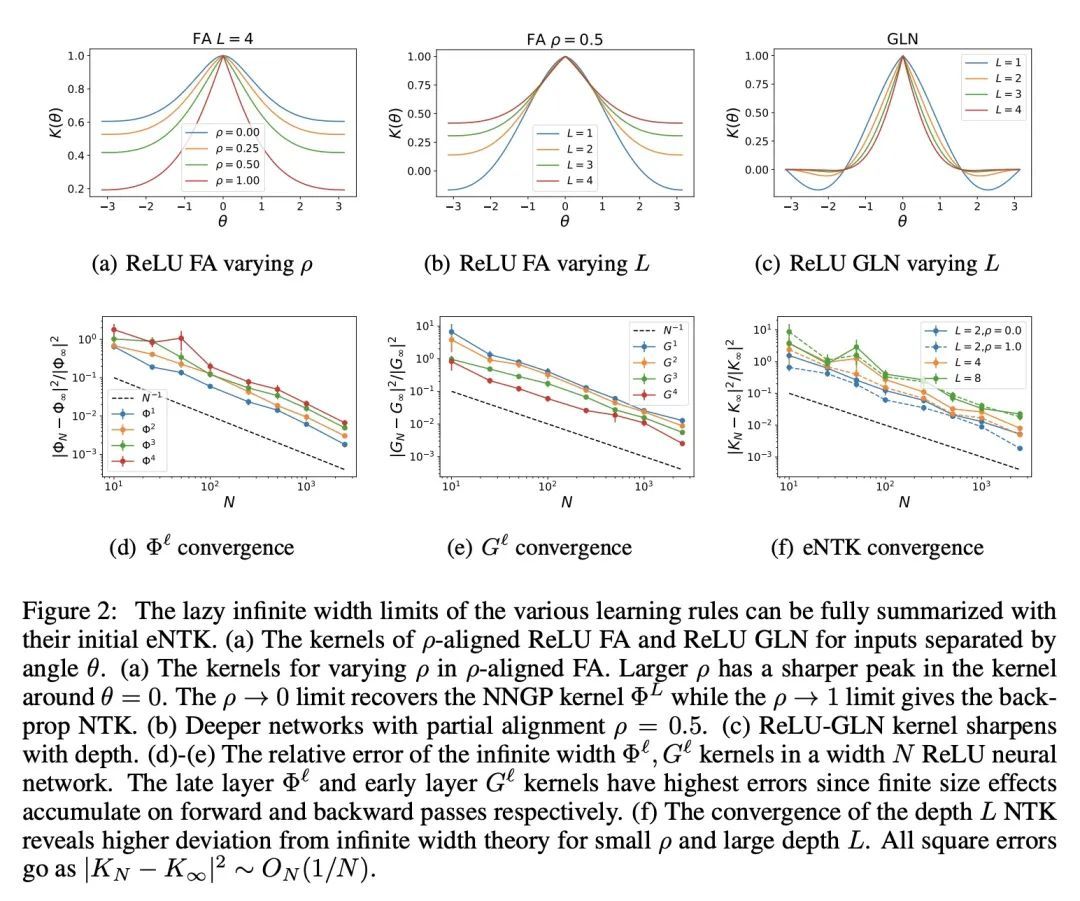
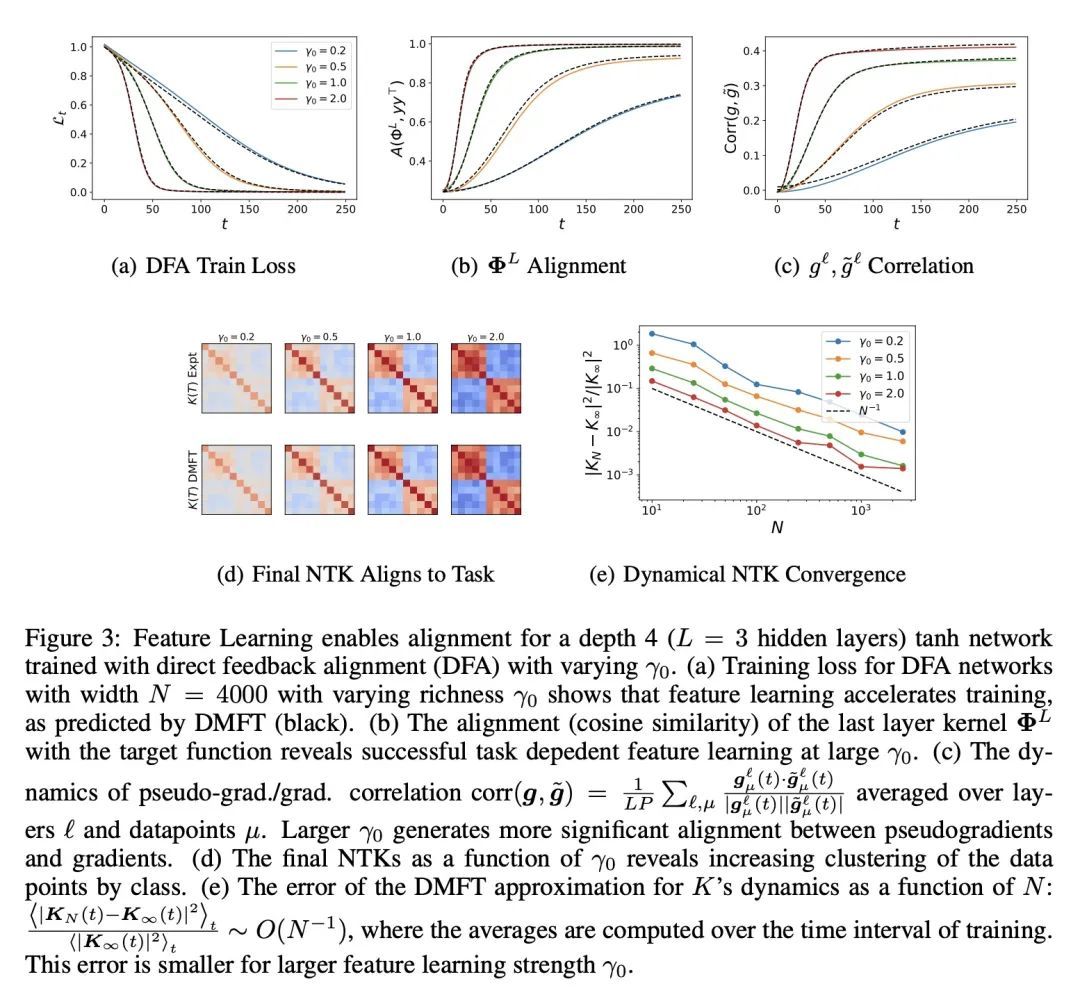
[LG] The Influence of Learning Rule on Representation Dynamics in Wide Neural Networks
规则学习对宽神经网络表征动力学的影响
B Bordelon, C Pehlevan
[Harvard University]
https://arxiv.org/abs/2210.02157

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢