
如何将人类先验知识低成本融入到预训练模型中一直是个难题。达摩院对话智能团队提出了一种基于半监督预训练的新训练方式,将对话领域的少量有标数据和海量无标数据一起进行预训练,从而把标注数据中蕴含的知识注入到预训练模型中去,打造了 SPACE 1/2/3 系列模型。
-
SPACE-1:注入对话策略知识,AAAI 2022 长文录用;
-
SPACE-2:注入对话理解知识,COLING 2022 长文录用,并获 best paper award 推荐;
-
SPACE-3:集对话理解 + 对话策略 + 对话生成于一体的模型, SIGIR 2022 长文录用。
达摩院对话大模型 SPACE-1/2/3 在 11 个国际对话数据集取得 SOTA。
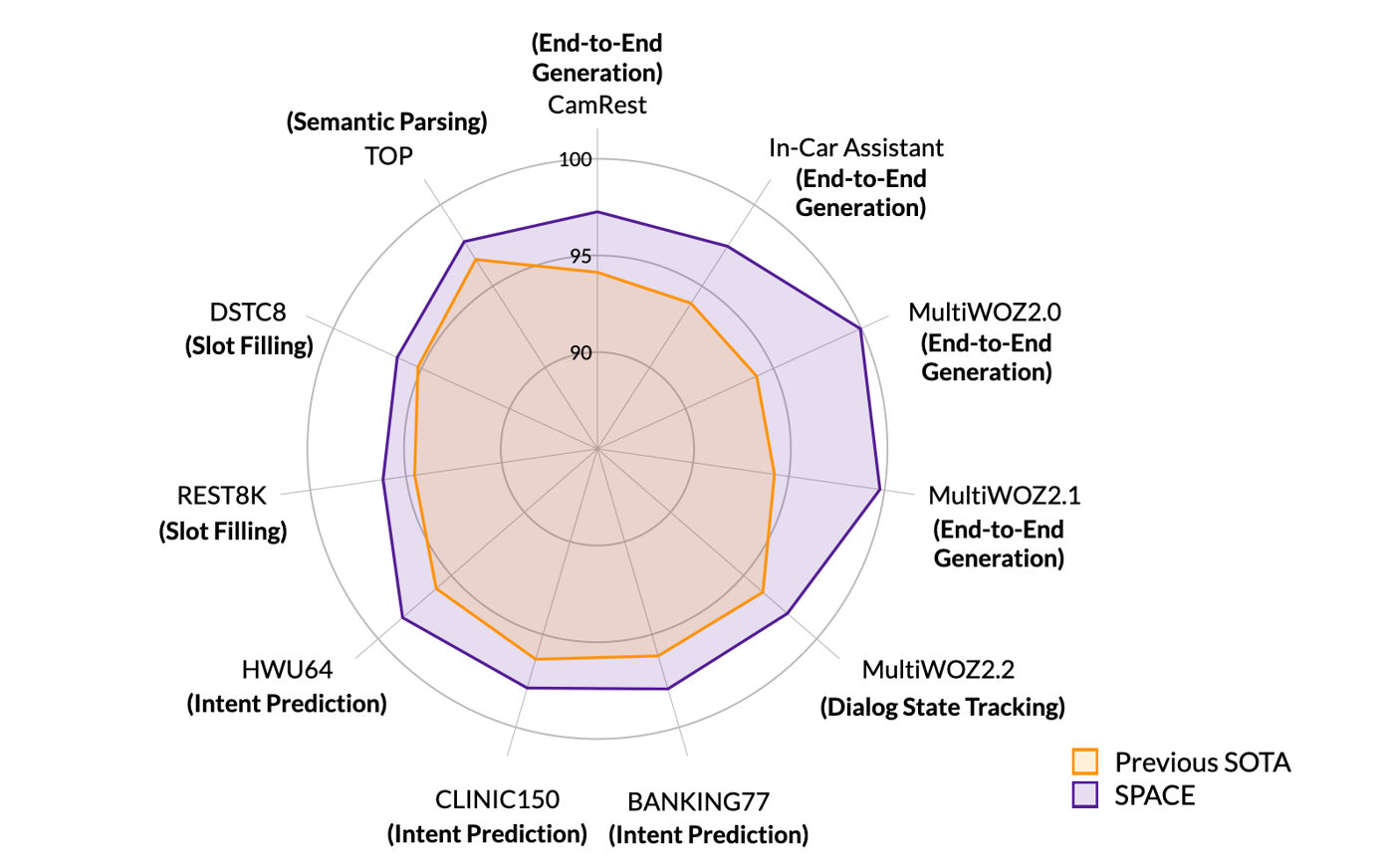
图 1 SPACE 系列模型在 11 个国际对话数据集取得 SOTA,包含 Intent Prediction、Slot Filling、Dialog State Tracking、Semantic Parsing、End-to-End Generation 五大类对话任务
-
SPACE-1: https://arxiv.org/abs/2111.14592
-
SPACE-2: https://arxiv.org/abs/2209.06638
-
SPACE-3: https://arxiv.org/abs/2209.06664
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢