
【标题】Decomposed Mutual Information Optimization for Generalized Context in Meta-Reinforcement Learning
【作者团队】Yao Mu, Yuzheng Zhuang, Fei Ni, Bin Wang, Jianyu Chen, Jianye Hao, Ping Luo
【发表日期】2022.10.9
【论文链接】https://arxiv.org/pdf/2210.04209.pdf
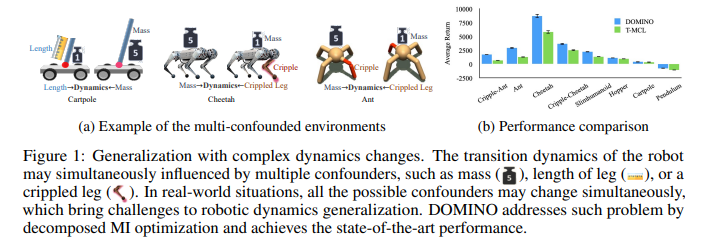
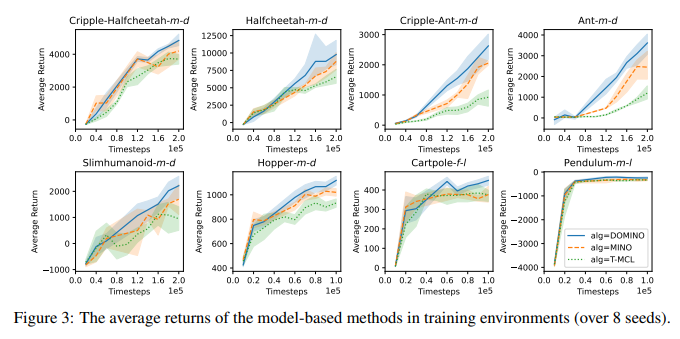
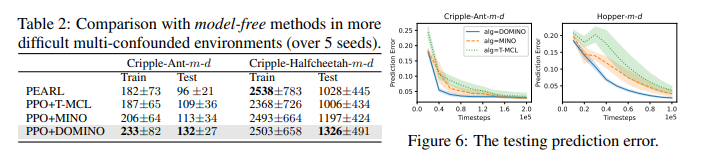
【推荐理由】适应过渡动力学的变化在机器人应用中至关重要。通过学习具有紧凑上下文的条件策略,上下文感知元强化学习提供了一种根据动态变化调整行为的灵活方法。然而,在实际应用中,智能体可能会遇到复杂的动态变化。多个混杂因素会影响过渡动态,因此难以为决策推断准确的背景。本文通过上下文学习的分解互信息优化(DOMINO)解决了这一挑战,DOMINO明确地学习一个不纠缠的上下文,以最大化上下文和历史轨迹之间的互信息,同时最小化状态转移预测误差。通过理论分析表明,DOMINO可以通过学习非纠缠上下文来克服由多个混淆挑战引起的对互信息的低估,并减少在不同环境中收集的样本数量的需求。大量实验表明,DOMINO学习的上下文对基于模型和无模型的强化学习算法在未知环境中的样本效率和性能方面都有利于动力学泛化。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢