
上海交通大学自动化系图像处理与模式识别研究所黄晓霖副教授团队,与鲁汶大学、加州大学圣克鲁兹分校的研究者合作,关注真实场景的防御,提出主动对攻击者实施攻击,在保证用户正常使用模型(无精度/速度损失)的同时,有效阻止黑盒攻击者通过查询模型输出生成对抗样本。经Rebuttal极限提分(2 4 4 5 -> 7 7 4 7),该研究已被机器学习顶级会议 NeurIPS 2022 录用,代码已开源。

Adversarial Attack on Attackers: Post-Process to Mitigate Black-Box Score-Based Query Attacks
论文:https://arxiv.org/abs/2205.12134
代码:https://github.com/Sizhe-Chen/AAA
【 研究背景 】
基于查询分数的攻击(score-based query attacks, SQAs)极大增加了真实场景中的对抗风险,因为其仅需数十次查询模型输出概率,即可生成有效的对抗样本。
然而,现有针对worst-case扰动的防御,并不适用于真实场景中,因为他们通过预处理输入或更改模型,显著降低了模型的推理精度/速度,影响正常用户使用模型。
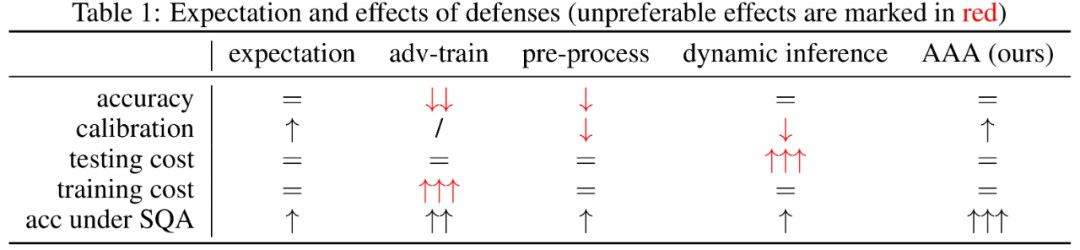
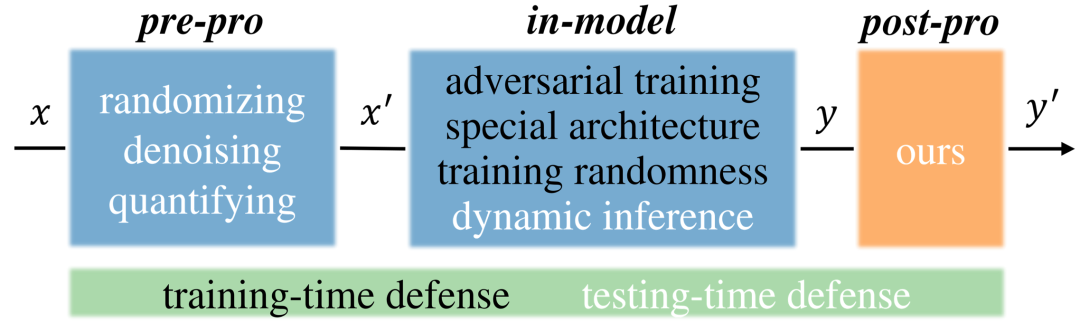
因此,本文考虑通过后处理来防御,其自带以下优点
- 有效防御基于查询分数的攻击
- 不影响模型精度,甚至还能使模型的置信度更加准确
- 是一种轻量化,即插即用的方法
可是在真实的黑盒场景中,攻击者和用户得到的,是相同的模型输出信息,如何在服务用户的同时,防御潜在攻击者?
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢