
图像合成(image composition)是指从一张图中剪切出感兴趣的前景部分,并将其粘贴到另一张背景图上,生成一张合成图的技术。但由于合成图的前景和背景是在不同条件(比如时刻、天气、季节、相机性能)下拍摄的,所以前景和背景的外观在亮度、色调等方面存在明显的不匹配的问题。图像和谐化(image harmonization)通过调整合成图中的前景部分,减小前景与背景的差异,使整张图看起来更加和谐一致。近年来,基于深度学习的图像和谐化得到了越来越多的关注。基于深度学习的图像和谐化方法需要大量成对的合成图片和对应的和谐化结果作来训练网络。[1]采取了一种逆向构建成对数据的策略,并公布了第一个大规模的图像和谐化数据库iHarmony4。具体来说,给定一张真实图片,选择一个前景进行调整使其和背景不和谐,得到一张人造的合成图。虽然这种构建数据库的方式可以产生大规模成对的训练数据,但仍然需要人工标注前景区域,以及过滤掉不合格的合成图,这极大地限制了图像和谐化数据库的扩展。我们利用3D渲染技术,构建并公布了渲染图像和谐化数据库。 此外,我们提出了跨域(cross-domain)和谐化的方法,并设计了风格聚合损失(style aggregation loss),可以同时利用真实图片和渲染图片来训练模型,实现对真实图片的和谐化。
在这篇论文中,我们把合成图的前景种类分成两个不相交的集合:基础种类和新种类。基础种类有大量的真实训练图片,而新种类只有少量或者没有真实训练图片。我们旨在用新种类的渲染训练图片帮助提升新种类的性能。这个问题设定有些别扭,也是因为我们发现渲染图片在真实图片充足的情况下起不到提升效果,所以只能退而求其次,着力于真实图片不足的问题设定。如何在真实图片充足的情况下使用渲染图片提升性能是我们尝试未果的方向。这篇工作的主要意义在于探索了图像和谐化任务中跨种类迁移和跨域迁移的问题,论文已被BMVC2022接收。

论文链接:
https://arxiv.org/pdf/2103.17104.pdf
数据库和代码链接:
https://github.com/bcmi/Rendered-Image-Harmonization-Dataset-RdHarmony
数据库构建
当数据库中缺少某个前景种类(比如猫、汽车、人类)的成对训练图片,而存在该种类的测试图片时,我们需要对数据库进行补充扩展。因为我们在实验中发现,跨种类(cross-category)的和谐化会使性能下降。虽然[1]中构建数据库的方式可以产生大规模成对的训练数据,但是在选择真实图片中的前景时,需要人工标注的前景掩码来定位前景物体的位置。另外,在生成合成图之后,也需要通过逐张人工筛选来过滤掉不合格的合成图。制作数据库过程中大量的人工劳动限制了数据库的扩展。
为了对真实图片训练数据中的稀缺种类进行补充,并且避免繁重的人工劳动,我们尝试利用3D渲染技术,构造该种类的渲染图片训练集,来解决跨种类(cross-category)和谐化带来的性能下降问题。我们构建并公布了渲染图像和谐化数据库RdHarmony,共包含225,000对渲染合成图和ground-truth,覆盖了11个前景种类。我们利用Unity3D来搭建3D场景,并拍摄2D场景。
同时我们用其天气系统插件UniStorm来模拟真实世界中的天气、时间变化,为每个2D场景构造不同的拍摄条件,即不同的风格(style),使得每个2D场景可以生成一组具有不同风格的2D渲染图片。我们将不同的天气和一天中不同的时间段进行组合,定义了10种风格,并从每种风格中随机挑选一张渲染图片来构造渲染图片数据库。对于每个2D场景,我们可以获得10张具有不同风格的渲染图片。另外,我们可以利用Unity3D获得精确的前景掩码(mask)。如下图所示,对于同一个2D场景中的10张渲染图片,我们两两交换前景(mask M对应的区域),最终获得成对的渲染合成图( I_{(i \to j)}I(i→j) )和ground-truth( I_iIi )。
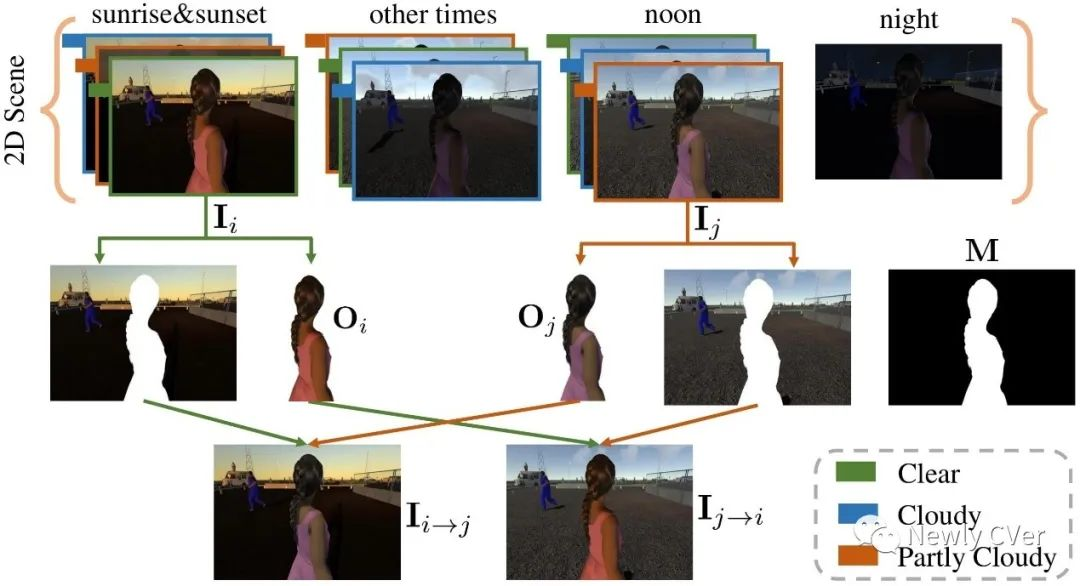
可以看出在渲染合成图中,前景和背景之间存在明显的差异,这与真实合成图的特征一致。我们对渲染图片数据库进行了全面细致的分析,包括渲染图片数据库的丰富性、前景种类的可扩展性,以及渲染图片数据库和真实图片数据库的不同组合对和谐化结果的影响,详见论文的补充材料。接下来,我们选取了六个例子来展示我们的渲染图片数据库。如下图所示,与真实图片数据库相同,我们的渲染图片数据库由成对的渲染合成图、ground-truth和前景掩码构成。此外,每张渲染合成图和ground-truth都有one-hot形式的风格标签,风格标签的定义方式详见论文正文。我们利用渲染图片数据库来对真实图片数据库进行补充,用渲染图片辅助对真实图片的和谐化。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢