

论文链接:
https://arxiv.org/abs/2209.13325
开源地址:
https://github.com/wimh966/outlier_suppression
https://github.com/ModelTC/MQBench
导读
最近,一些工作[1]指出Transformer架构语言模型中的结构化异常值对量化精度影响极大,如8比特量化能带来12%精度下降。该工作用了更加细粒度的量化方式来应对这种挑战,但是该方法并没有减少或者抑制异常值而且会增加计算复杂度。本文工作从异常值抑制角度出发,通过对异常值的深入分析,提出加速无损的异常值抑制框架。
该工作从这类模型的量化瓶颈-结构化异常值出发,探究了异常值的来源以及裁剪影响。针对这两方面的发现,作者提出了Outlier Suppression framework(异常值抑制框架),其中包括Gamma Migration和Token-Wise Clipping两个组件来抑制异常值从而得到更好的量化精度。该框架能够即插即用,适合多种模型(BERT,RoBERTa,BART等)、多个任务(分类任务、问答任务,摘要生成任务等)。相比于已有的SOTA方法,该框架首次将6比特BERT的离线量化精度提高到接近全精度模型水平。该方法凭借扎实的分析、高效的方法设计和显著的提升效果受到审稿人的一致认可,得到777的高评分。
分析
基于Transformer架构的模型,标准的6/8比特离线量化或者4比特在线量化就会导致严重的精度下降。通过实验,作者发现LayerNorm和GELU激活函数的输出具有的尖锐的异常值导致了严重的量化误差。
为了进一步探究这些有害的异常值和模型量化的关系,作者探讨了异常值的诱因和异常值的裁剪的影响。首先给出异常值的描述来有助于理解后续部分:
- 异常值往往集中在一些特定的维度上;
- 在这些特定的维度上,一些特殊的令牌例如[SEP]和标点等相比其他令牌异常值现象更加严重。
2.1 异常值的诱因

在异常值诱因的探究上, γ 和LayerNorm的输出在相同维度上表现出异常值,即γ 作为异常值放大器放大了输出的异常值。关于有些令牌有更明显的异常值现象,作者猜测这是由于预训练过程中不均匀的词频引起的(具体可见论文)。由于调整预训练成本的高成本,该部分主要研究 γ 的诱因影响来抑制其异常值,对于另一部分的诱因作者通过后续裁剪影响的分析来抑制其异常值。
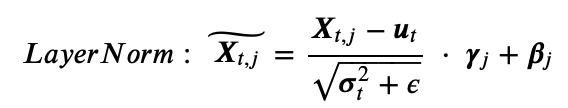
如上是LayerNorm计算公式,作者通过观察LayerNorm的参数分布,作者发现放缩参数γ (图1.b)和LayerNorm的输出X (图1.a)在相同的维度会出现异常值。至于平移参数β ,由于其范围如(0,3)相比输出范围如(-60,0)较小,在关键诱因上可以忽略。即γ 是这些异常值(图1.a)出现的关键因素,并且γ 作为一个共享的参数可以对所有令牌的异常值都有放大效果。
此观察结果启发了作者通过移除LayerNorm中的 γ 来去掉异常值的放大作用。从LayerNorm中提出γ 得到Non-scaling LayerNorm。
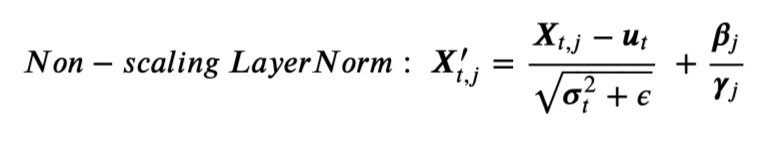
图1.c和图1.a表示Non-scaling LayerNorm的输出比标准LayerNorm的输出在量化上更加友好。表1中量化后的X′ 与X 的余弦相似度(更高的值表示更小的量化误差)也从数值角度证明了这一点。

2.2 异常值的截断影响
在这一部分中,作者探讨了裁剪异常值的影响来帮助在量化上确定合适的裁剪范围。实验针对浮点模型从裁剪对精度的影响和裁剪对令牌的影响两方面开展。
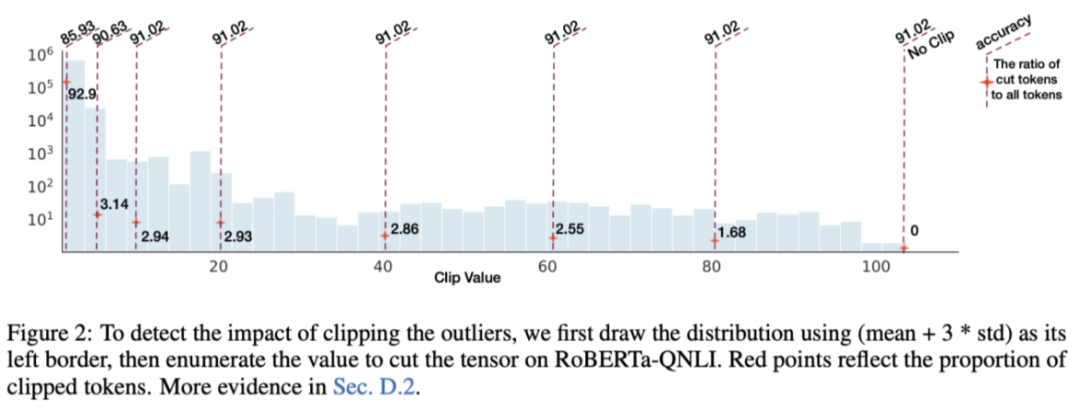
对模型精度的影响: 对异常值进行裁剪并评估模型精度时,作者发现裁剪带来的精度影响差异很大。图2(以GELU激活函数的异常值为例)表明大幅度裁剪异常值(从10-100 的值都裁剪到10)甚至不会引发浮点模型的精度下降(精度仍为 91.02)。但是如果继续进行截断,模型的精度将骤降。
对令牌的影响: 对于不重要的异常值(不影响模型精度的情况下可以被截断),作者发现虽然覆盖的范围很大(例如从10-100),但是实际上这个范围内的值只由非常少的令牌贡献,例如图2的红点(被剪裁的令牌比例)表明仅3%的令牌对这个长尾分布有贡献。这也和前述所说不同令牌的范围差异很大所吻合。
方法
作者提出了异常值抑制框架,其包含两个组件 Gamma Migration和Token-Wise Clipping。这两个组件分别基于前面两个分析来缓解异常值。Gamma Migration通过将γ 转移到后续模块中来得到更友好的量化模型,Token-Wise Clipping借助令牌之间的较大范围差异来快速确定合适的裁剪范围。
3.1 Gamma Migration
正如异常值诱因分析中所述,Non-scaling LayerNorm的输出具有更小的量化误差。因此,作者将LayerNorm中的γ 迁移到后续模块中,并量化Non-scaling LayerNorm的输出(图3)。接下来本文展示这种变换在浮点模型上是等价的,同时不会对量化模型带来额外的计算开销。
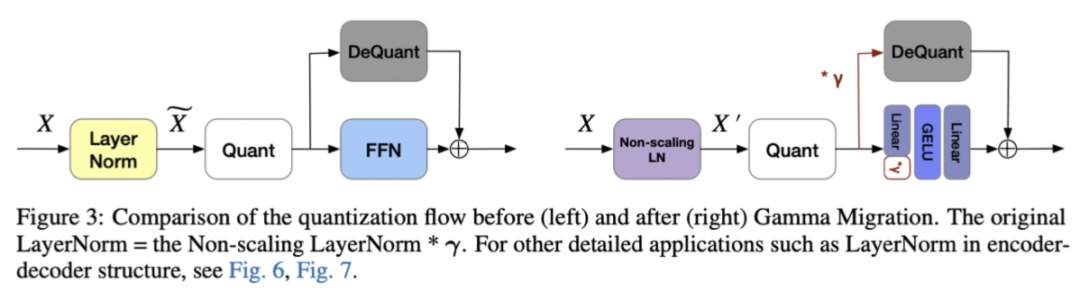
浮点模型的等价变换: 在LayerNorm中抽出γ 从而从\( \widetilde{\mathbf{X}}_{t, j} \) 分离出\( \mathbf{X}_{t, j}^{\prime} \) 。接下来将γ 迁移到后面模块中。
这里给出经典的Post-LN结构的迁移过程,即迁移到残差连接的两个分支上。例如Multi-Head Attention 后面的LayerNorm,抽取出来的γ 一方面在shortcut分支上重新建立,一方面被下一层权重吸收。由于对于线性层,有如下等式成立:
其中 x 为列向量, \( \gamma \in \mathbb{R}^{n} \) 。因为γ 是一个共享参数,所以所有令牌都符合该公式,所以γ 可以被成功转移到权重中。
模型等价变换后的量化: 图 3 标明了进行等价变换后模型的量化范式。可以看到被量化的输出是Non-scaling LayerNorm的输出,且该输出具有量化更加友好的特点。同时,低比特矩阵乘法依旧像原本一样。相当于只是将γ 的计算从LayerNorm上延后到shortcut分支。因此,这样的设计不会增加计算开销。
3.2 Token-Wise Clipping
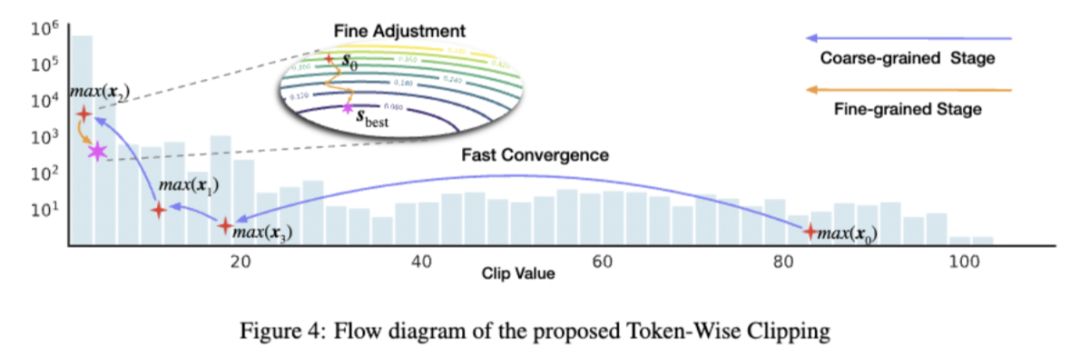
考虑到裁剪带来的精度影响差异很大,作者搜索量化最终损失最小的截断范围(相当于步长参数 s )。损失定义如下:
\( L(s)=\|\hat{f}(s)-f\|_{F}^{2} \)
为了高效地实施这个过程特别对于那些不重要异常值覆盖了很大范围的情况,作者设计 coarse-to-fine的范式。
Coarse-grained stage: 目的是迅速跳过裁剪后对模型精度影响不大的区域。根据前文分析,图4中的长尾区域只对应少数令牌。因此作者使用了令牌 x 的最大值作为该令牌异常值的代表(最小值作为负异常值的代表)。从而可以构建拥有 TT 个元素的向量 \( o^{u} \) 。
\( {o}^{u}=\left\{\max \left({x}_{1}\right), \max \left({x}_{2}\right), \ldots, \max \left({x}_{T}\right)\right\} \)
其中 \( o^{u} \) 为令牌上界的集合, \( o^{l} \)表示令牌下界的集合。
对于\( o^{u} \)上的一个裁剪比率 α ,计算对应的截断值 \( c^{u} \),并用它来作为完整分布的裁剪值。
\( c^{u}=\text { quantile }\left(o^{u}, \alpha\right) \)
通过grid search对α 进行搜索,找到使量化误差最小的裁剪范围或者步长 (\( s=\frac{c^{u}-c^{1}}{2^{b}-1} \) ,其中 b 为位宽)。标记此步骤最终得到的步长为s0 ,用作下一步骤的初始值。
Fine-grained stage: 目的做一些细粒度的调整,为最终模型的效果提供保障。作者使用学习过程来微调 量化步长 s ,其中 ss 初始化值s0 由coarse-grained stage提供。
实验
该框架即插即用,对离线量化和在线量化都能有很好的帮助。
4.1 离线量化
作者将提出的框架在BERT、RoBERTa、BART模型上进行应用,在分类任务、问答任务和摘要生成任务上验证了框架的有效性。如下给出主要实验结果。
4.1.1 消融实验
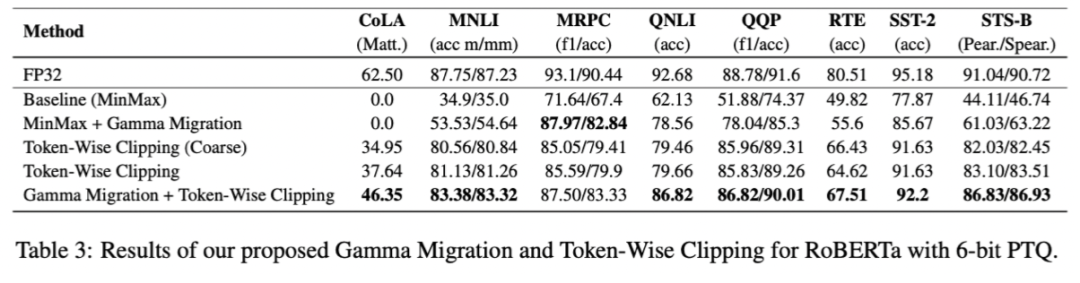
作者在消融实验中,分别验证了Outlier Suppression framework在离线量化和在线量化的有效性。从表3中可以看出,Gamma Migration作为模型结构上的变换对MinMax和Token-Wise Clipping等多种方法均有精度提升。Token-Wise Clipping也大幅度超越了Baseline,在QNLI和MRPC上分别有17.53%、13.22%的提升。
4.1.2 分类任务
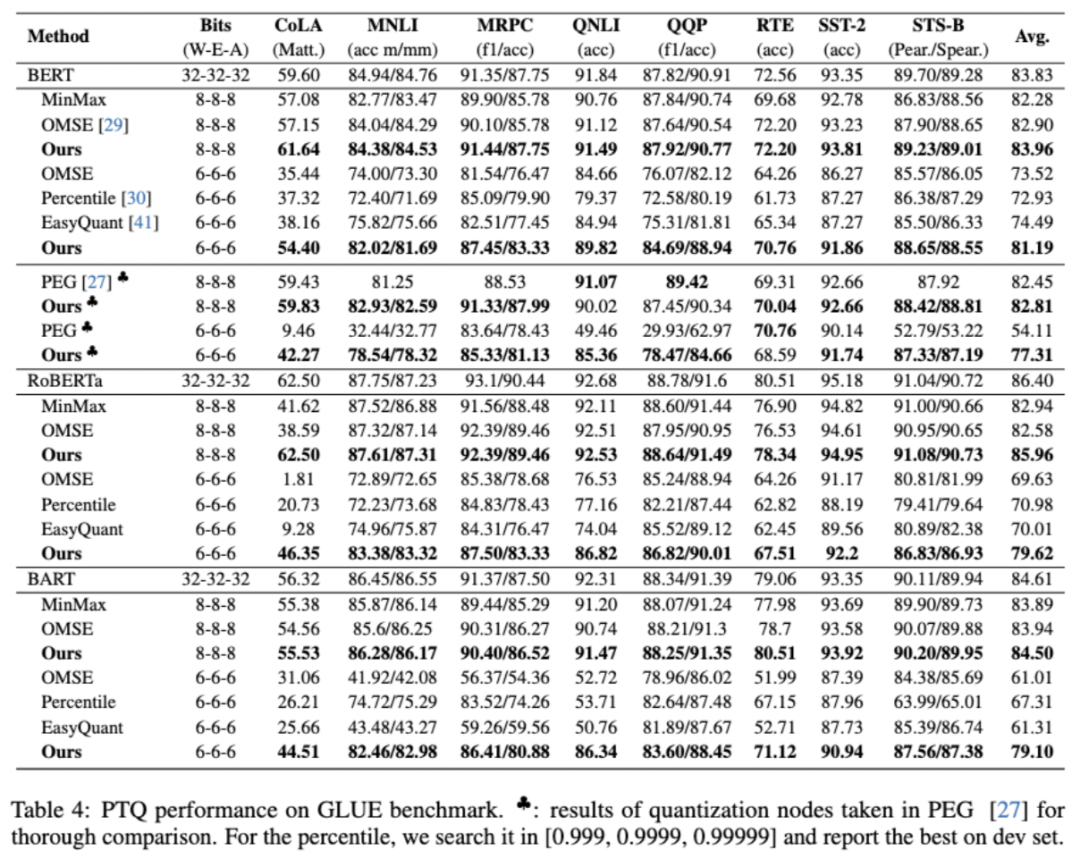
表3表示了离线量化在GLUE分类任务上的结果。对于8比特BERT 模型,虽然以前的方法通常表现良好,但作者的方法在 CoLA(提升了4.49%)和 STS-B(提升了1.33%)等小型数据集上仍然可以取得较好的结果。作者尝试了一个更具有挑战的实验,将权重和激活量化为6比特。可以看出,作者的方法接近全精度模型且差距在2.64%以内。同时,作者还与PEG [1] 设置相同量化节点进行公平比较。需要注意的是,PEG量化会带来额外的计算开销,并且可能无法在实际部署中使用,而outlier suppression framework可以在硬件上享受无损加速。此外,作者的方法在RoBERT和BART相比于已有的方法来说具有明显的优势。平均而言,作者将RoBERT和BART上6比特的准确率分别提高了8.64% 和11.79%。总的来说,作者提出的方法将这些语言模型的6 比特量化推向了一个新的技术水平。
4.1.3 摘要生成
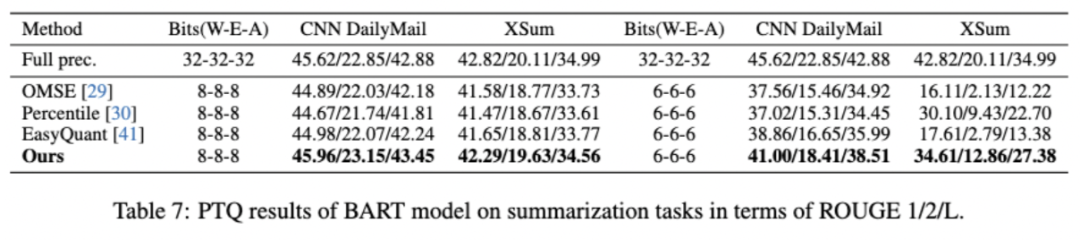
作者选择经典摘要数据集CNN/DailyMail和XSum。表4说明作者的方法也有利于生成任务,并且可以在8比特上带来接近全精度模型的性能,在6比特上带来约4%的提升。
4.2 在线量化
该框架也能和在线量化兼容。该框架取代在线量化的校准阶段,对于训练阶段,作者采用了强有效的经典方法LSQ+进行训练。如下实验表明提供更好的初始化参数(更好的校准结果),在线量化的精度也能大幅增长。
4.2.1 消融实验
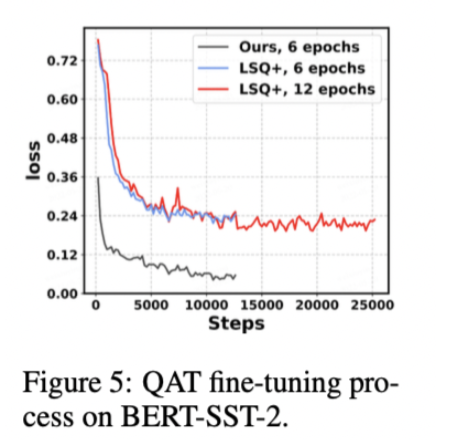
图5表明了作者提出的框架能够提供更好的初始化参数,并且这让在线量化的训练收敛的更容易、更快速。
4.2.2 分类任务
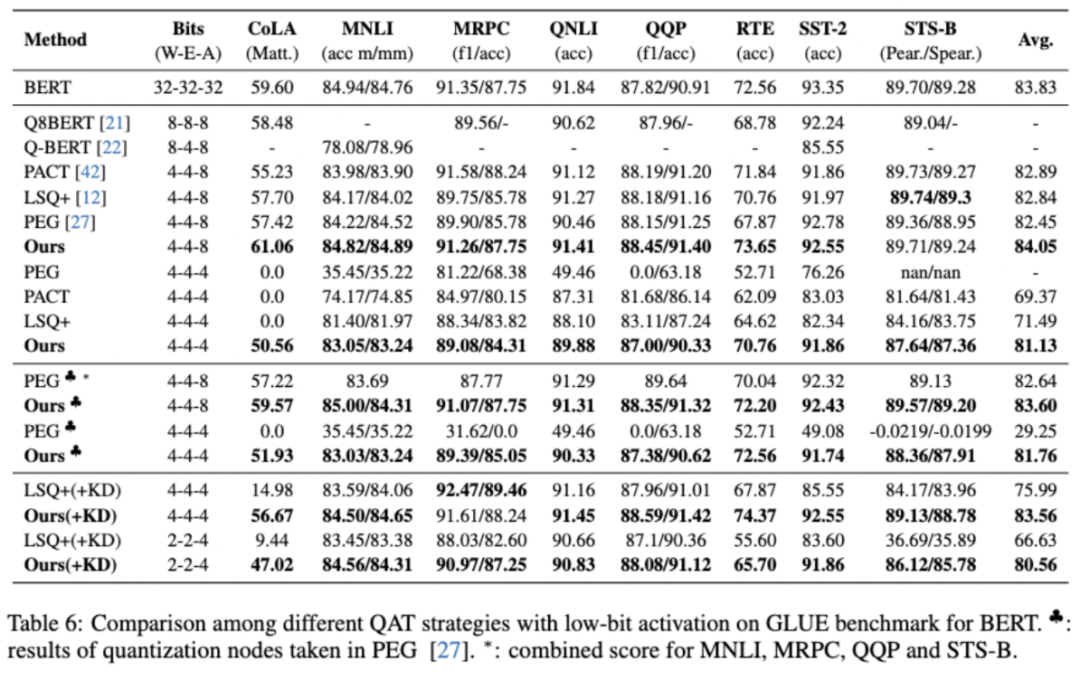
作者也在GLUE benchmark中显示了该框架在在线量化上的有效性。表5列出了 BERT 上的结果,RoBERTa和BART的结果见论文。在更困难的实验设置(4-4-4比特量化)中, 作者的方法取得了接近全精度模型的性能,4比特量化设置下平均降低了 2.70%。在没有任何蒸馏和数据增强技巧下, QQP精度下降了 0.7%,MNLI 精度下降了1.7%,而对比方法 LSQ+ 分别为 4.19% 和 3.16%。此外,使用知识蒸馏可以进一步提高模型性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢