
背景
近年来,随着深度学习技术与自然语言处理的结合,神经机器翻译技术迅速取得了统治地位,并且使得WMT等诸多研究基线得到提升,翻译服务的质量也取得进步。这些进步很大程度上来自于端到端深度学习方法的成功应用。这也造成了神经机器翻译对数据质量和数量的依赖,然而当前在机器翻译领域不同语言可使用的数据规模存在着非常大的差异,比如英语、德语、汉语等语言存在着数以亿计的双语平行句对,这类语言被称为富资源语言。然而不幸的是,在世界现存超过五千种语言中,富资源语言仅占其非常小的一部分,绝大部分语言的可用平行语料非常稀少,这类语言被称为低资源语言。甚至有些时候,对于特定领域或语种,获取到双语平行语料是十分困难的,被称为“零资源”。同时,在工业界大多数翻译系统只包括了几百种语言,且大多数语言为欧洲地区的印欧语系。如何构建低资源甚至零资源机器翻译系统是当下急需解决的问题。
近期来自谷歌的研究者们发表了名为Building Machine Translation System for The Next Thousand Language (opens new window)的论文,标志着多语言机器翻译又一里程碑式的发展。本文将对这篇论文中所提到的关键技术进行梳理与讲解。
低资源机器翻译的瓶颈
对低资源语言搭建高质量的机器翻译模型有两个关键的瓶颈,第一点是如何构建有效的数据:许多语言的数字化数据有限,几乎没有双语平行语料。第二点是如何根据有限的数据构建高效的翻译模型:常规的机器翻译模型需要大规模双语数据,而在低资源语言上,模型必须在有限的双语句对甚至单语数据上进行学习。只有尝试解决这两个关键问题,才有可能构建出有效的低资源机器翻译模型。
本文主要的贡献
1.针对机器翻译的数据瓶颈,作者通过利用半监督预训练语言识别模型和基于数据驱动的语料过滤技术,为1500多种语言构建高质量的来自于Web挖掘的数据集。
2.通过利用100多种高资源语言的平行语料训练的大规模多语种模型和另外1000多种语言的单语种数据集,为当前服务不足的语言开发实用的机器翻译模型。
数据瓶颈
神经机器翻译需要大量的训练语料来对模型进行训练,这里面包含两类数据:互译的平行语料与单语语料。双语语料是机器翻译模型的核心,模型需要互译的句对作为指导,学习不同语言之间的映射关系。但双语平行语料的数目是十分有限的,当前以英语为代表的近一百种语言有着数以亿计的双语句对可供使用,但在这之外的其他语言大多只有极少数可用的双语平行语料,而更多的是单语数据。近年来,随着反向翻译与自监督训练的兴起,单语数据在机器翻译中的作用也日益凸显,尤其是在低资源语言领域。虽然通过有限的双语平行语料与单语语料的结合促进了低资源翻译的发展,但我们不得不面临的一个问题是,世界上大多数语种并没有大规模的数据集,甚至没有高质量的电子化的数据。
为了解决上述问题,众多的研究者将目光投向了互联网中大量的文档与网页数据。但不幸的是,互联网中的数据存在着大量的噪声,并不能直接使用。且作者发现适用于以往高资源语言的数据收集策略会为低资源语言引入大量的噪声,并不能进行简单的迁移。同时作者在实践中发现,针对互联网中收集到的低资源语言数据,一个首要的挑战是判断该文档是否是由该语言编写的。同时要在大量互联网文档中做到这一点,必须要求语言识别足够快且支持识别的语种要足够多,任何计算消耗型的方法可能都不再适用。
图1 CLD3模型结构
为了解决上述问题,作者首先确定了要收集的语言的范围,选定了1745种语言作为收集的目标。并在收集到的这1745种语言上训练了一个简单且高效的语言识别模型。该模型是一个CLD3模型,其由一个简单的前馈网络构成,其结构如图1所示。在网络的训练过程中,考虑到不同语言的差异性与复杂性,作者并没有使用常见的以词或字词为基础的编码方法,而是采用了基于字符的词袋模型进行训练。并使用该模型将那些分类差异较大的语种进行过滤。最终在这一阶段,作者保留了其中的1629个语言。并在这1629种筛选出来的语言上继续训练了一个CLD3语言识别模型,以求更加精确的对语料所属的语言进行过滤。
随后作者进一步的细化了过滤粒度,以句子为操作单位进行过滤,这一阶段主要过滤了那些与所属文档语言识别结果不同的句子。同时,考虑到CLD3模型的局限性,作者引入了基于规则的过滤,例如删除该语言最常用词少于 20% 的句子等等。
在经过上述的过滤后,数据集的质量已经得到了较为明显的提升,并且数据规模也允许我们使用一些较为复杂的过滤方法。在本文中作者引入了一个基于Transformer的语言分类器,更加精准地对句子的所属语言进行分类。
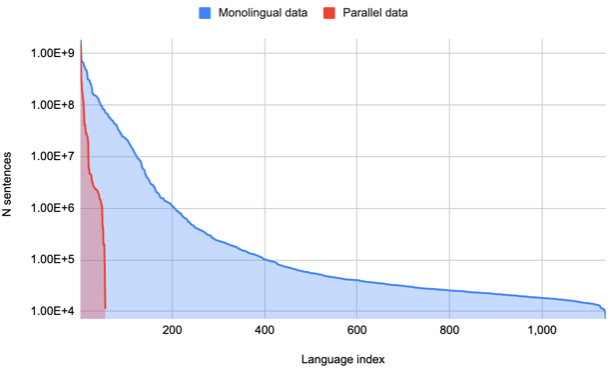
图2 各语言数据规模分布
作者指出,在数据集构建过程中,能够获得以这些稀缺语言为母语的人群的帮助对系统构建是十分重要和关键的,比如如何进行数据过滤、如何正确评估语言质量、保证语言命名规范性等等。同时作者对最终得到的数据质量进行了人工评估,测评人员主要包括母语人士和非母语人士的志愿者。作者选择数据集中的72种语言样本供志愿者评估,最终数据得分中位数为 80%。 该分数是一种简单的启发式方法,分数计算定义为 1.0 * cc + 0.5 * cb + 0.3 * ca + 0.2 * wd,其中 cc 是被标记为“正确”的样本比例,cb 是标记为“正确,低质量”的百分比,ca 是标记为“正确,模棱两可的方言”的百分比,wd 是标记为“正确,错误的方言”的百分比。
最终通过上述步骤,作者最终构建了一个包含1503种语言的多语言单语数据集,如图2所示,各语言的数据规模从1句(巴布亚语(Mape))到83M句(沙巴-马来西亚语)不等。同时作者还构建了一个包含25亿句对,覆盖112种语言的双语平行语料数据集。其单语数据与双语数据的数据规模与涵盖语种如上图所示。
模型方法
常用的低资源机器翻译模型主要包括三类:基于枢轴语言的方法、基于知识蒸馏的方法、基于迁移学习的方法。在本文中作者主要使用了基于迁移学习的方法。迁移学习是一种基于机器学习的方法,指的是将与目标任务相似任务上训练完成的模型,重新用在目标任务上,而不是从头直接训练一个新的模型。
在本文中,作者沿用了Siddhant等人所提出的方法[1],使用MASS作为多语言机器翻译的基础模型,开发了一种简单而实用的零资源翻译方法,即对没有平行文本和特定翻译示例的语言进行翻译。作者首先在112种大规模双语平行语料上对模型进行训练,直接对翻译过程进行建模,使模型学习数据间的映射关系。随后通过大量的单语数据对低资源语言的语言表示进行建模,依靠迁移学习在大规模多语言模型中的优势,提升模型零资源机器翻译的能力。在模型训练过程中,模型的所有输入都拼接上了一个特殊的语言标识,用以指示模型要将该语言翻译成哪种语言。但与常规方法不同的是,在使用单语数据进行训练时,作者依然保留了该任务标记,如<translate_to_french>,而此时,该标记的含义就变为了将输入mask处理后的语言还原为流利的源语言。从而增强模型对具体语言的建模能力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢