
作者: Laura Cabello Piqueras, Anders Søgaard
简介:本文基于业界第一个“对不同语言的多语言模型的群体差异比较的数据集”进行了多语言模型公平性的研究。预训练的多语言模型可以帮助弥合数字语言鸿沟,为资源较低的语言提供高质量的NLP模型。到目前为止,对多语言模型的研究主要集中在性能、一致性和跨语言通用性方面。然而,随着它们在非主流地区和下游社会影响中的广泛应用,将多语言模型与单语模型置于同样的审查之下是很重要的。
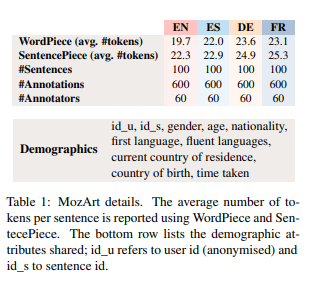
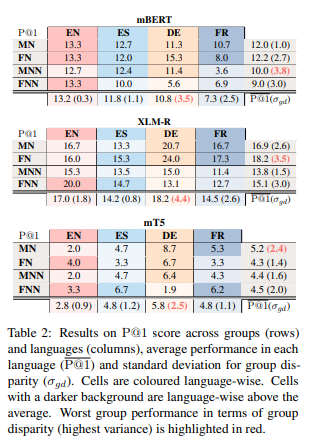
这项工作调查了多语言模型的公平性,旨在确认相关模型在不同语言之间是否同样公平。为此,作者创建了一个新的四维多语言平行完形填空测试示例数据集(MozArt),该数据集包含测试参与者的人口统计信息(性别和母语平衡)。作者在MozArt上评估了三种多语言模型:mBERT、XLM-R和mT5。实验表明:在四种目标语言中,上述三种模型表现出不同程度的群体差异、并不公平(比如德语的风险较高)。
论文下载:https://arxiv.org/pdf/2210.05457
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢