
【论文速读】是OpenBMB发起的大模型论文学习栏目。栏目初期,我们邀请了 清华大学自然语言处理实验室 的大牛分享业界经典论文。未来,我们也诚邀各大高校、科研机构的领域人才作为主讲人,用 高效的思维导图 形式,带领大家在 10min 内快速掌握一篇 前沿经典 论文。
EMNLP ( Conference on Empirical Methods in Natural Language Processing ) 是计算语言学和自然语言处理领域的顶级国际学术会议。本期论文速读我们选取了一篇有关 大模型提示微调 的经典工作—— EMNLP 2021 的发表工作:The Power of Scale for Parameter-Efficient Prompt Tuning ,由清华大学自然语言处理实验室的博士后韩旭进行领读讲解。
![]()
01 作者信息
三位作者 Brian Lester、Rami Al-Rfou 和 Noah Constant 均来自 Google Research,参与了 mT5 、FLAN(Fine-tuned language models are zero-shot learners)的研究,前者是基础模型、后者是大模型 zero-shot 的范式。
![]()
02 论文简介
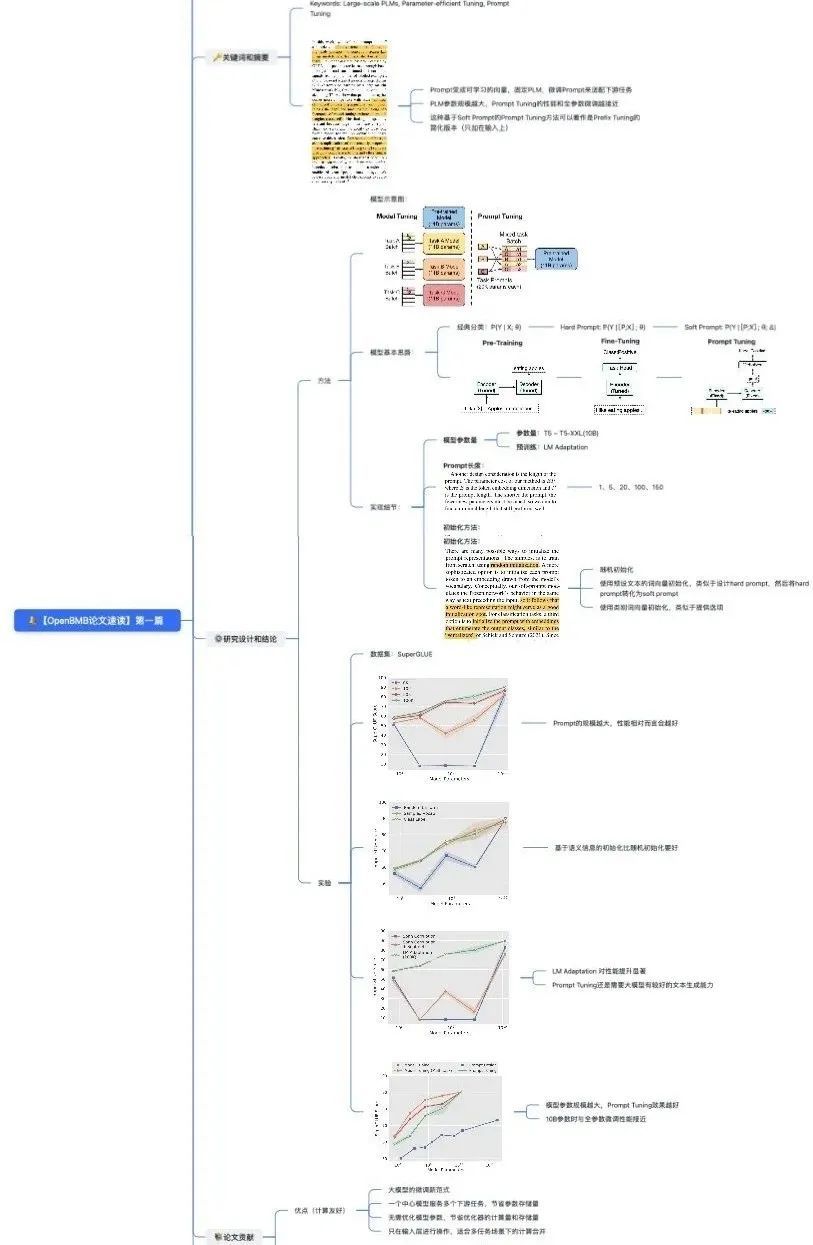
关键词 KeyWords
Parameter-efficient Tuning
摘要概览 Abstract
![]()
03 研究设计
提示微调让 P 作为可学习向量,提示的参数用 Δ 表示,在训练过程中 θ 固定,只对 Δ 进行调整。
预训练模型要在每个任务上单独微调,而每个任务会得到一个任务相关的模型;而提示微调的每个任务只学一个提示,再将提示和数据一起输入到统一的预训练模型里面。
运用提示微调,所有下游任务都围着一个模型进行,因此 存储和部署性能会大幅提升。
(1)模型参数量
(3)提示初始化方法
![]()
04 实验及结论
数据集:SuperGLUE
结论:
(1)提示的规模越大,性能相对而言会越好
(2)基于语义信息的初始化比随机初始化要好
(3)语言模型的 Adaptation 对性能提升显著
(4)模型参数规模越大,Prompt Tuning 效果越好,10B 参数时与全参数微调性能接近
![]()
05 优点及局限
优点:计算友好
论文提供了大模型的微调新范式。用一个中心模型服务多个下游任务,节省了参数存储量;无需优化模型参数,节省优化器的计算量和存储量;只在输入层进行操作,适合多任务场景下的计算合并。
局限:性能和收敛性存在问题
Prompt Tuning 的收敛速度很慢,模型性能不稳定,Few-shot 场景上表现不如全参数微调。
即可获得高清完整版思维导图 ![]()
我们为读者准备了一份高清思维导图,包括了论文中的重点亮点以及直观的示意图。点击下方名片 关注 OpenBMB ,后台回复“论文速读” ,即可领取论文学习高清思维导图和 FreeMind !
本期论文领读视频版已发布于 视频号 和 B站 ,欢迎大家 一键三连 !
以上是本期论文领读的全部内容,后续 OpenBMB 会围绕大模型介绍更多的高效微调方法,欢迎大家持续关注!👏
论文文章链接:
🔗 https://aclanthology.org/2021.emnlp-main.243/
B站观看链接:
🔗 https://www.bilibili.com/video/BV18P411E7VK/?spm_id_from=333.337.search-card.all.click&vd_source=bdd62f2879017ebb1eddfb3f5191bc6d
内容中包含的图片若涉及版权问题,请及时与我们联系删除




评论
沙发等你来抢