
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:基础Transformer、与机器人实时对话、高确定性流形的有效维度和低置信界、用自监督视频预训练产生强大图像表示、Transformer对储存在上下文和权重中的信息有不同的泛化能力、基于分层错误合成的文本生成指标学习、识别和消除多语言Transformer中的干扰、机器人记忆弱监督语义场、用离线强化学习从少量试错学习新任务
1、[LG] Foundation Transformers
H Wang, S Ma, S Huang, L Dong, W Wang, Z Peng, Y Wu, P Bajaj, S Singhal, A Benhaim, B Patra, Z Liu, V Chaudhary, X Song, F Wei
[Microsoft]
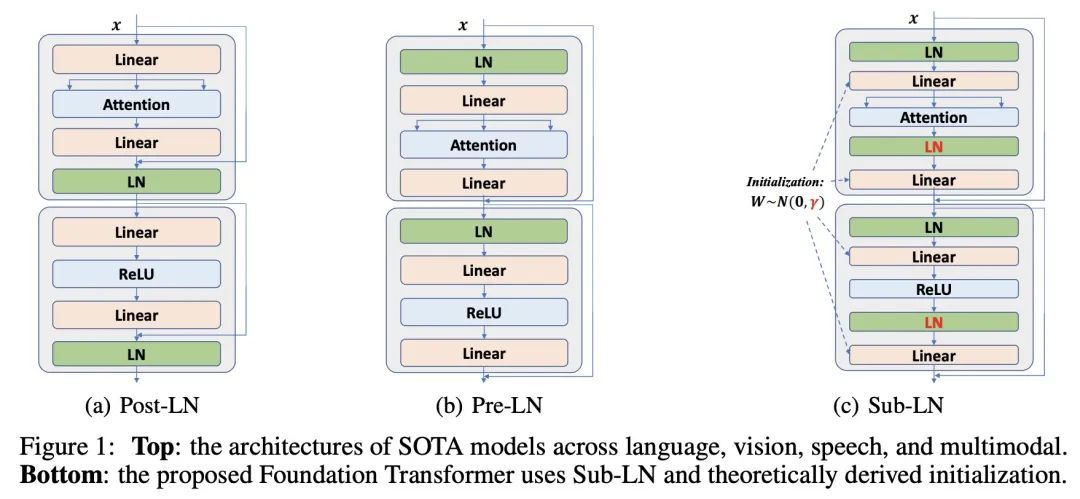
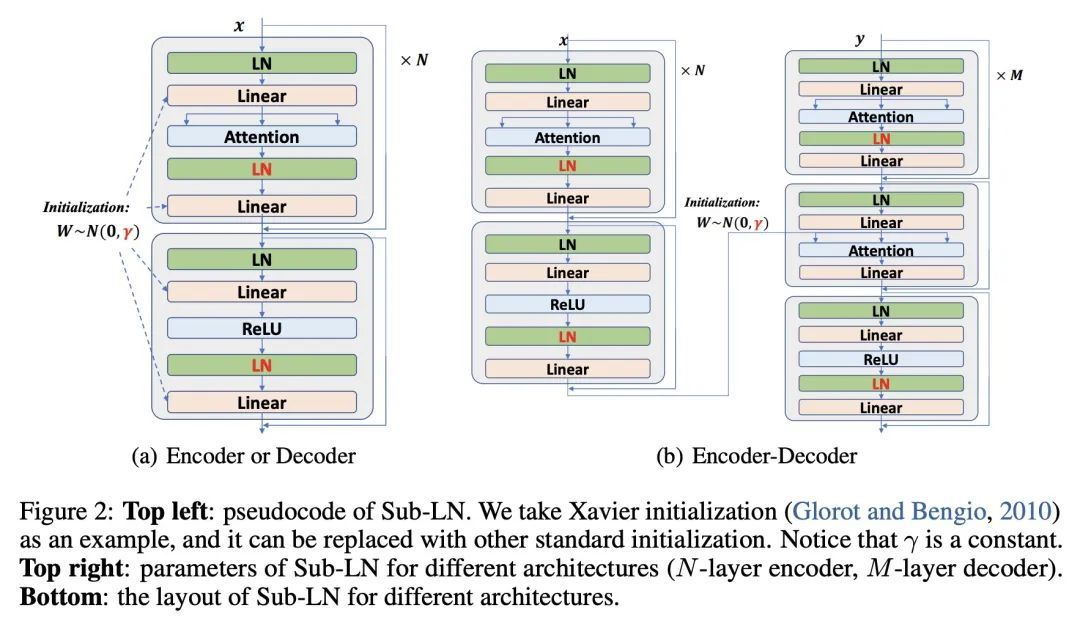
基础Transformer。一种跨语言、视觉、语音和多模态的模型架构的大融合正在出现。然而,在同一名称"Transform "下,上述领域使用不同的实现方式以获得更佳的性能,例如,BERT用Post-LayerNorm,而GPT和视觉Transform用Pre-LayerNorm。本文呼吁为真正的通用建模开发基础Transformer,其可作为各种任务和模态的首选架构,并保证训练的稳定性。本文提出一种Transformer变体Magneto,以实现这一目标。具体来说,本文提出Sub-LayerNorm来实现良好的表达能力,并从理论上提出了DeepNet的初始化策略来实现稳定扩展。广泛的实验证明了它比为各种应用设计的事实上的Transformer变体更出色的性能和更好的稳定性,包括语言建模(即BERT和GPT)、机器翻译、视觉预训练(即BEiT)、语音识别和多模态预训练(即BEiT-3)。
A big convergence of model architectures across language, vision, speech, and multimodal is emerging. However, under the same name "Transformers", the above areas use different implementations for better performance, e.g., Post-LayerNorm for BERT, and Pre-LayerNorm for GPT and vision Transformers. We call for the development of Foundation Transformer for true general-purpose modeling, which serves as a go-to architecture for various tasks and modalities with guaranteed training stability. In this work, we introduce a Transformer variant, named Magneto, to fulfill the goal. Specifically, we propose Sub-LayerNorm for good expressivity, and the initialization strategy theoretically derived from DeepNet for stable scaling up. Extensive experiments demonstrate its superior performance and better stability than the de facto Transformer variants designed for various applications, including language modeling (i.e., BERT, and GPT), machine translation, vision pretraining (i.e., BEiT), speech recognition, and multimodal pretraining (i.e., BEiT-3).
https://arxiv.org/abs/2210.06423

2、[RO] Interactive Language: Talking to Robots in Real Time
C Lynch, A Wahid, J Tompson, T Ding, J Betker, R Baruch, T Armstrong, P Florence
[Robotics at Google]
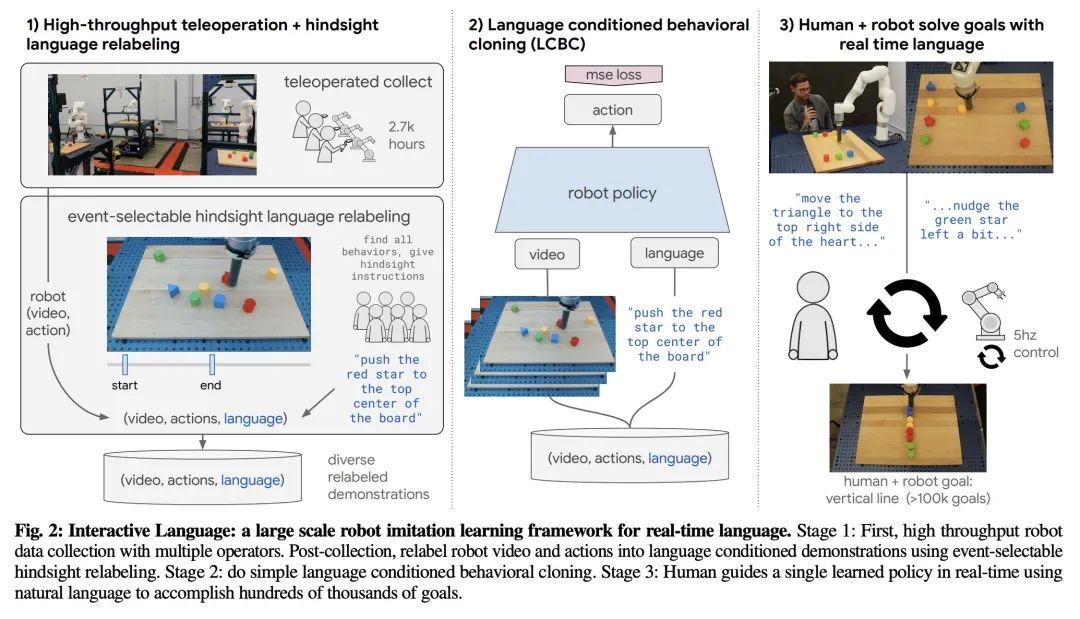
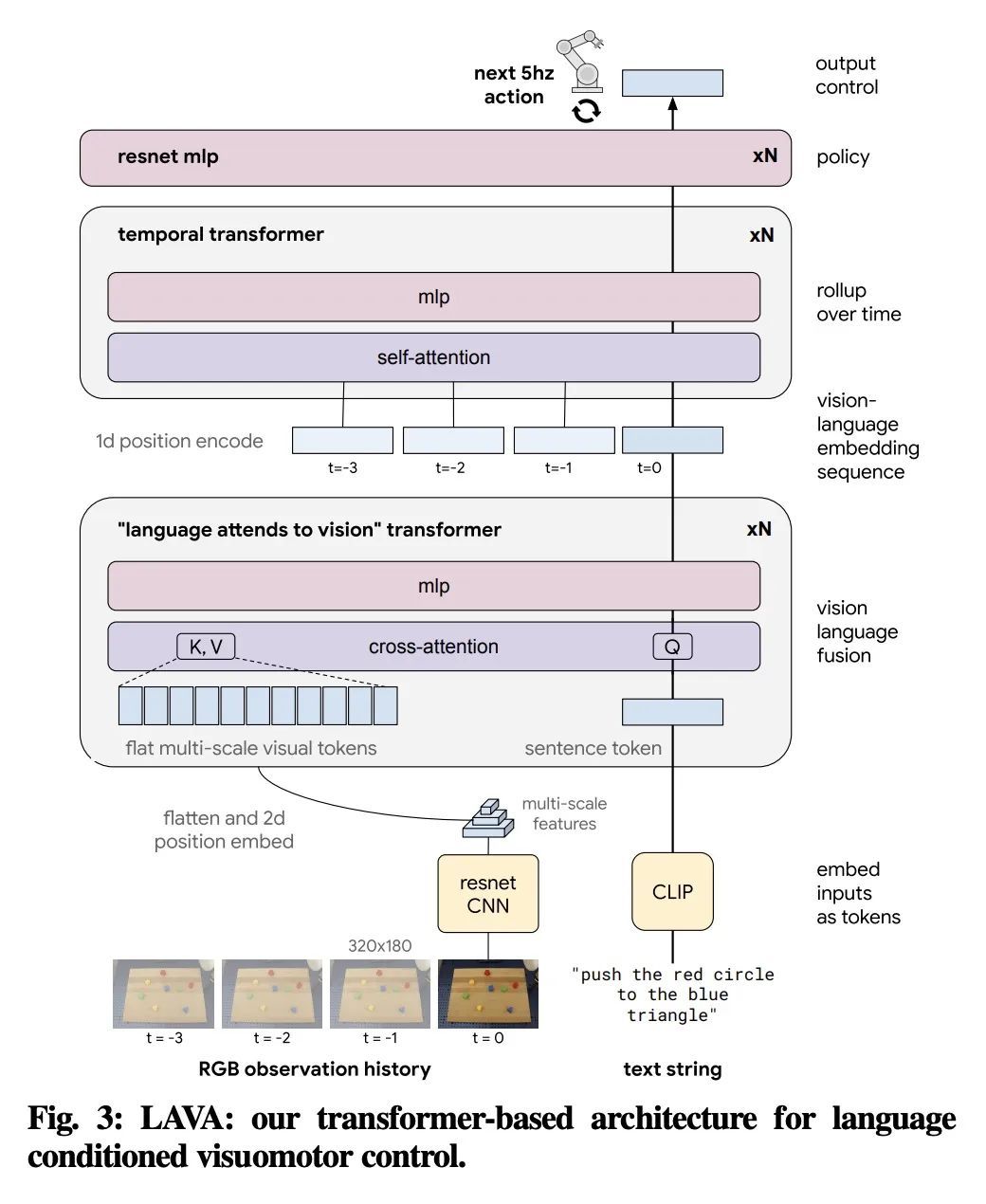
交互式语言:与机器人实时对话。本文提出一种在现实世界构建交互式、实时、可用自然语言的机器人的框架,并开放了相关资产(数据集、环境、基准和策略)。通过对几十万个语言标注轨迹的数据集进行行为克隆训练,产生的策略可以熟练地执行比以前的工作多一个数量级的命令:在现实世界中,对于特定的原始端到端视觉-语言-运动技能,在一组87000个独特的自然语言字符串上估计达到93.5%的成功率。本文发现,同样的策略能被人工通过实时语言引导,以解决广泛的精确的长程重排目标,例如 "用积木做一个笑脸"。本文发布的数据集包括近60万个语言标记的轨迹,比之前的可用数据集大一个数量级。希望所展示的结果和相关资产能够进一步推动有益的、有能力的、可进行自然语言交互的机器人的发展。
We present a framework for building interactive, real-time, natural language-instructable robots in the real world, and we open source related assets (dataset, environment, benchmark, and policies). Trained with behavioral cloning on a dataset of hundreds of thousands of language-annotated trajectories, a produced policy can proficiently execute an order of magnitude more commands than previous works: specifically we estimate a 93.5% success rate on a set of 87,000 unique natural language strings specifying raw end-to-end visuo-linguo-motor skills in the real world. We find that the same policy is capable of being guided by a human via real-time language to address a wide range of precise long-horizon rearrangement goals, e.g. "make a smiley face out of blocks". The dataset we release comprises nearly 600,000 language-labeled trajectories, an order of magnitude larger than prior available datasets. We hope the demonstrated results and associated assets enable further advancement of helpful, capable, natural-language-interactable robots. See videos at this https URL.
https://arxiv.org/abs/2210.06407


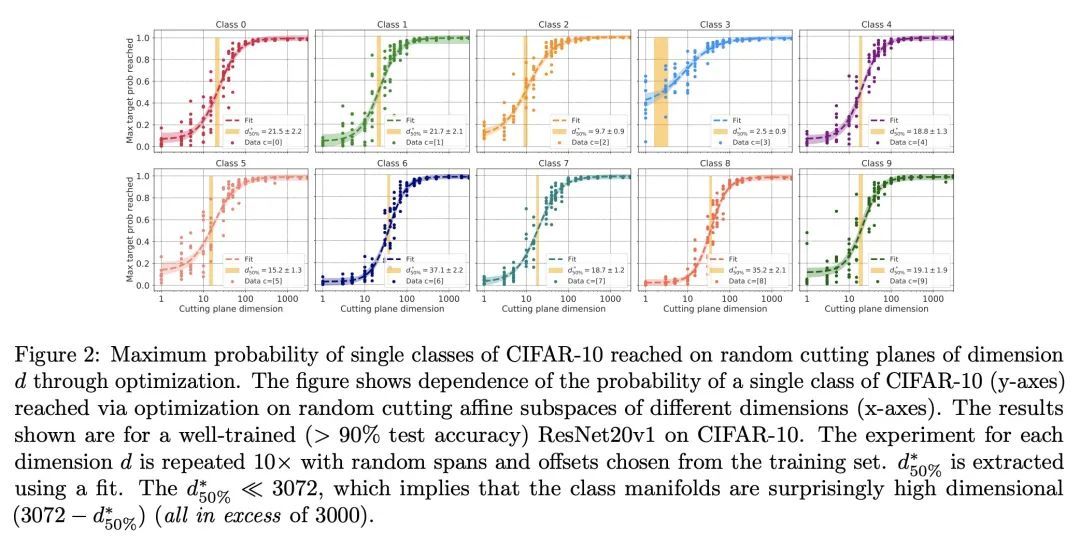
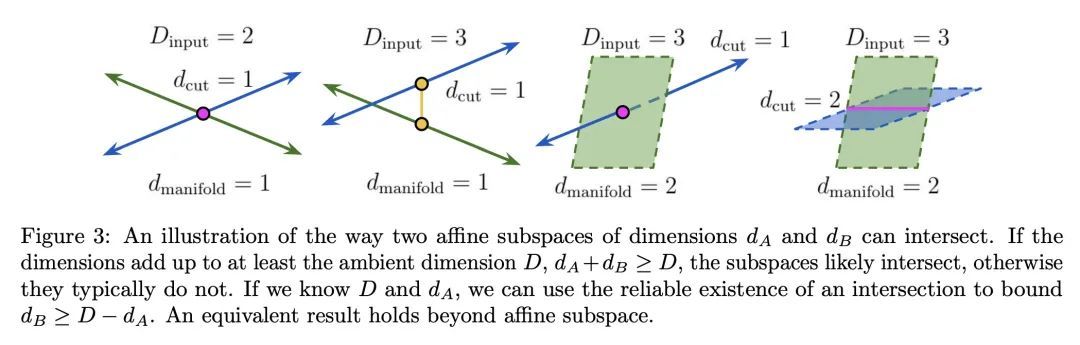
3、[LG] What does a deep neural network confidently perceive? The effective dimension of high certainty class manifolds and their low confidence boundaries
S Fort, E D Cubuk...
[Stanford University & Google Research]
深度神经网络可以置信地感知到什么?高确定性流形的有效维度和低置信界。深度神经网络分类器将输入空间划分为每个类别的高置信区域。这些类流形(CM)的几何形状被广泛研究,并与模型性能密切相关;例如,边际取决于CM的界。本文利用高斯宽度和戈登逃逸定理的概念,通过与不同维度的随机仿射子空间的断层相交来切实地估计CMs的有效维度及其界。本文展示了CM的维度、泛化和鲁棒性之间的一些联系。特别是研究了CM的维度如何取决于1)数据集,2)架构(包括ResNet、WideResNet/Vision Transformer),3)初始化,4)训练阶段,5)类别,6)网络宽度,7)集合大小,8)标签随机化,9)训练集大小,以及 10)对数据损坏的鲁棒性。一起出现的情况是,性能更高的和更鲁棒的模型具有更高的维度的CM。此外,本文通过CM的交集提供了一个关于集合的新视角。
Deep neural network classifiers partition input space into high confidence regions for each class. The geometry of these class manifolds (CMs) is widely studied and intimately related to model performance; for example, the margin depends on CM boundaries. We exploit the notions of Gaussian width and Gordon's escape theorem to tractably estimate the effective dimension of CMs and their boundaries through tomographic intersections with random affine subspaces of varying dimension. We show several connections between the dimension of CMs, generalization, and robustness. In particular we investigate how CM dimension depends on 1) the dataset, 2) architecture (including ResNet, WideResNet \& Vision Transformer), 3) initialization, 4) stage of training, 5) class, 6) network width, 7) ensemble size, 8) label randomization, 9) training set size, and 10) robustness to data corruption. Together a picture emerges that higher performing and more robust models have higher dimensional CMs. Moreover, we offer a new perspective on ensembling via intersections of CMs. Our code is at this https URL
https://arxiv.org/abs/2210.05546


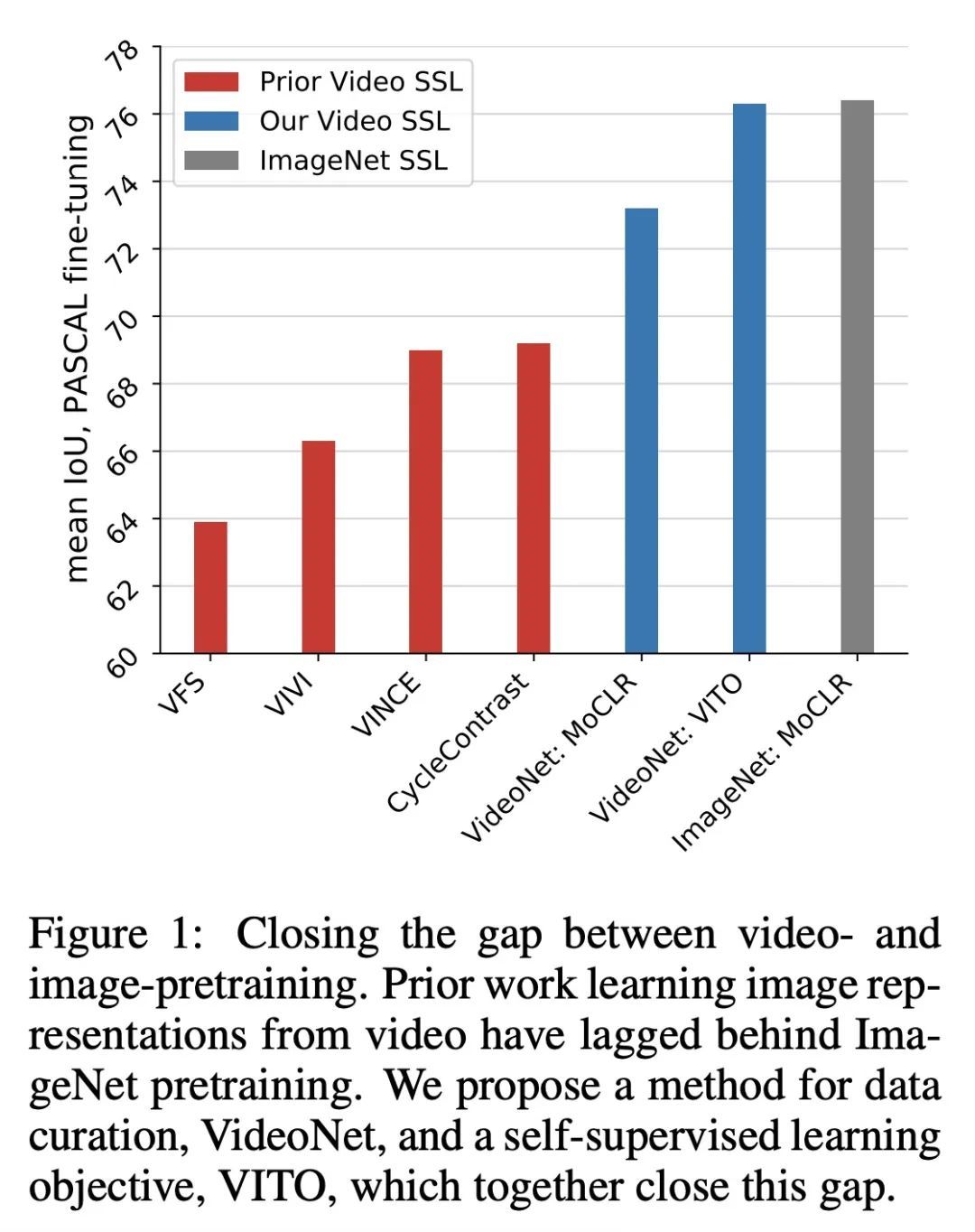
4、[CV] Self-supervised video pretraining yields strong image representations
N Parthasarathy, S. M. A Eslami, J Carreira, O J. Hénaff
[DeepMind]
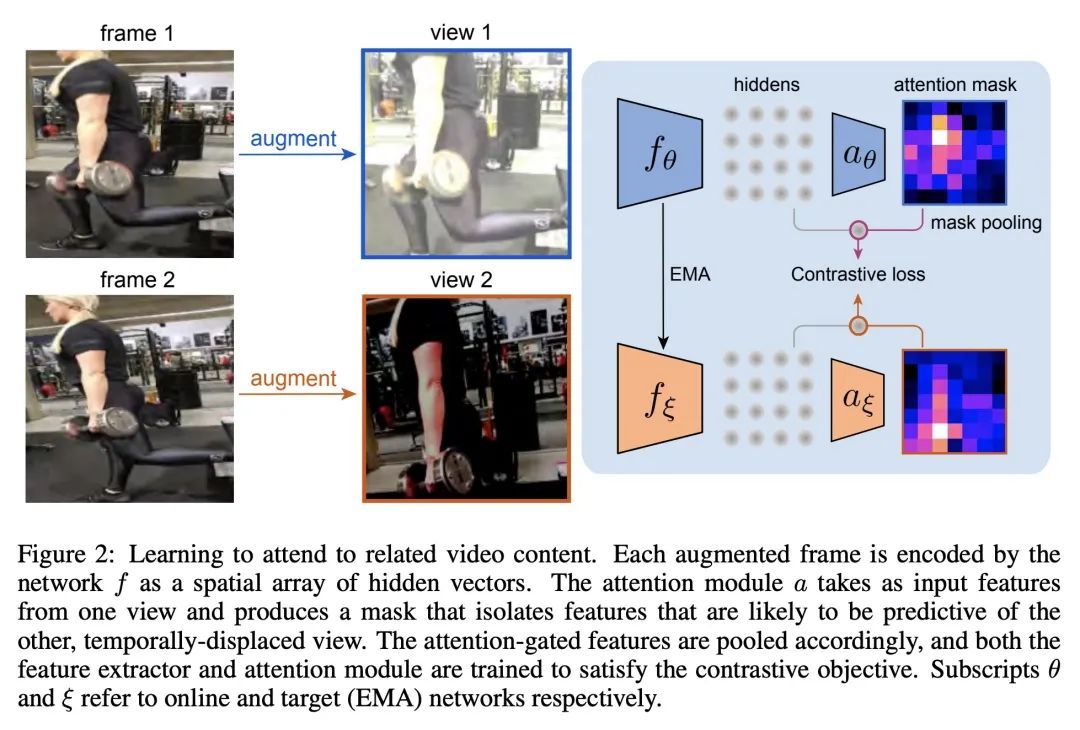
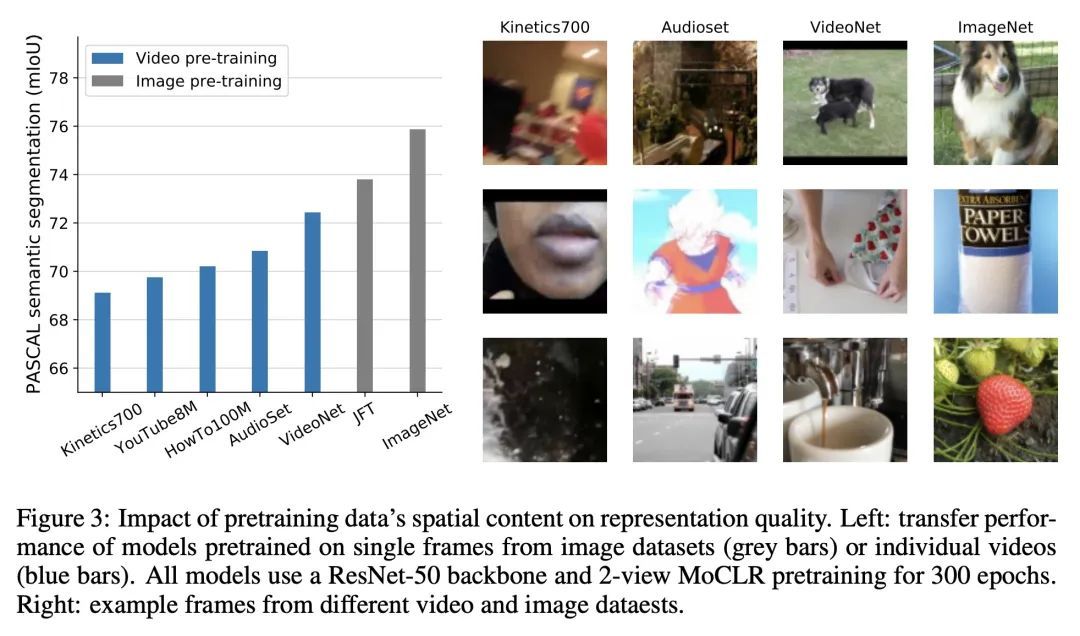
用自监督视频预训练产生强大图像表示。视频所包含的信息远远多于静态图像,并具有学习视觉世界的丰富表示的潜力。然而,对图像数据集的预训练仍然是学习捕捉空间信息的表征的主流范式,之前在视频预训练方面的尝试在图像理解任务中是失败的。本文重新审视了从视频帧的动态演变中对图像表示的自监督学习。本文提出一种数据集策划程序,以解决视频和图像数据集之间的域不匹配问题,并开发了一个对比学习框架,以处理自然视频中存在的复杂转换。这种将知识从视频提炼成图像表示的简单范式,称为VITO,在各种基于图像的迁移学习任务中表现得出奇地好。在PASCAL和ADE20K的语义分割以及COCO和LVIS的物体检测方面,所提出的视频预训练模型首次缩小了与ImageNet预训练的差距,这表明视频预训练可以成为学习图像表示的新的默认方法。
Videos contain far more information than still images and hold the potential for learning rich representations of the visual world. Yet, pretraining on image datasets has remained the dominant paradigm for learning representations that capture spatial information, and previous attempts at video pretraining have fallen short on image understanding tasks. In this work we revisit self-supervised learning of image representations from the dynamic evolution of video frames. To that end, we propose a dataset curation procedure that addresses the domain mismatch between video and image datasets, and develop a contrastive learning framework which handles the complex transformations present in natural videos. This simple paradigm for distilling knowledge from videos to image representations, called VITO, performs surprisingly well on a variety of image-based transfer learning tasks. For the first time, our video-pretrained model closes the gap with ImageNet pretraining on semantic segmentation on PASCAL and ADE20K and object detection on COCO and LVIS, suggesting that video-pretraining could become the new default for learning image representations.
https://arxiv.org/abs/2210.06433
5、[CL] Transformers generalize differently from information stored in context vs in weights
S C.Y. Chan, I Dasgupta, J Kim, D Kumaran, A K. Lampinen, F Hill
[DeepMind]
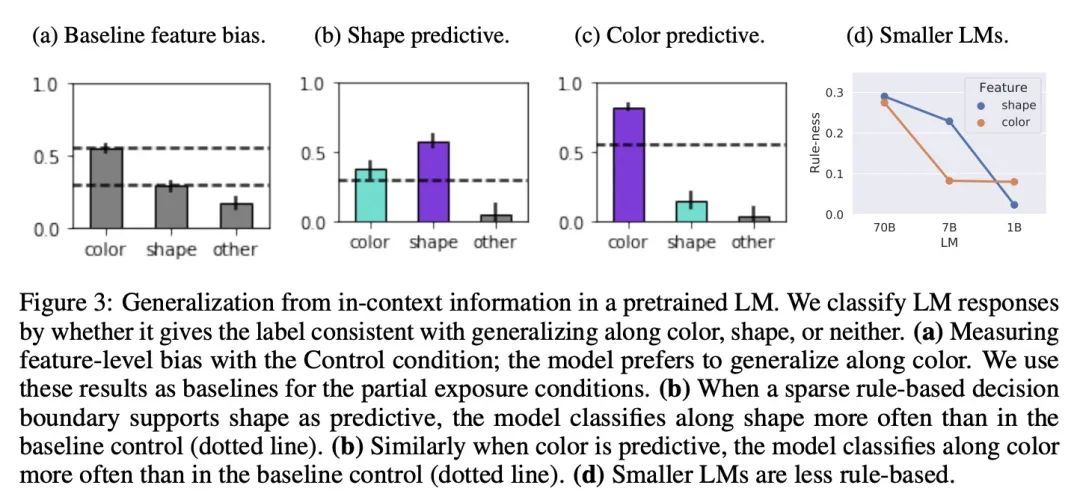
Transformer对储存在上下文和权重中的信息有不同的泛化能力。Transformer模型可以使用两种根本不同的信息:训练期间存储在权重中的信息和推理时提供的"上下文"中的信息。本文表明Transformer在如何表示和归纳这两个来源的信息方面表现出不同的归纳偏差。特别是,本文描述了它们是通过解析规则(基于规则的泛化)还是通过与观察到的样本直接比较(基于范例的泛化)来进行泛化。这具有重要的实际意义,因为它告诉我们是在权重中编码信息还是在上下文中编码信息,这取决于我们希望模型如何使用这些信息。在对受控刺激词进行训练的Transformer中,本文发现从权重中进行的泛化更多的是基于规则的,而从上下文中进行的泛化则主要是基于范例。与此相反,在对自然语言进行预训练的Transformer中,上下文学习明显是基于规则的,较大的模型显示出更多的规则性。本文假设,从上下文信息中进行的基于规则的泛化可能是对语言进行大规模训练的结果,而语言具有稀疏的规则式结构。使用受控的刺激词,本文验证了在含有稀疏规则样结构的数据上预训练的Transformer表现出更多的基于规则的泛化。
Transformer models can use two fundamentally different kinds of information: information stored in weights during training, and information provided ``in-context'' at inference time. In this work, we show that transformers exhibit different inductive biases in how they represent and generalize from the information in these two sources. In particular, we characterize whether they generalize via parsimonious rules (rule-based generalization) or via direct comparison with observed examples (exemplar-based generalization). This is of important practical consequence, as it informs whether to encode information in weights or in context, depending on how we want models to use that information. In transformers trained on controlled stimuli, we find that generalization from weights is more rule-based whereas generalization from context is largely exemplar-based. In contrast, we find that in transformers pre-trained on natural language, in-context learning is significantly rule-based, with larger models showing more rule-basedness. We hypothesise that rule-based generalization from in-context information might be an emergent consequence of large-scale training on language, which has sparse rule-like structure. Using controlled stimuli, we verify that transformers pretrained on data containing sparse rule-like structure exhibit more rule-based generalization.
https://arxiv.org/abs/2210.05675



另外几篇值得关注的论文:
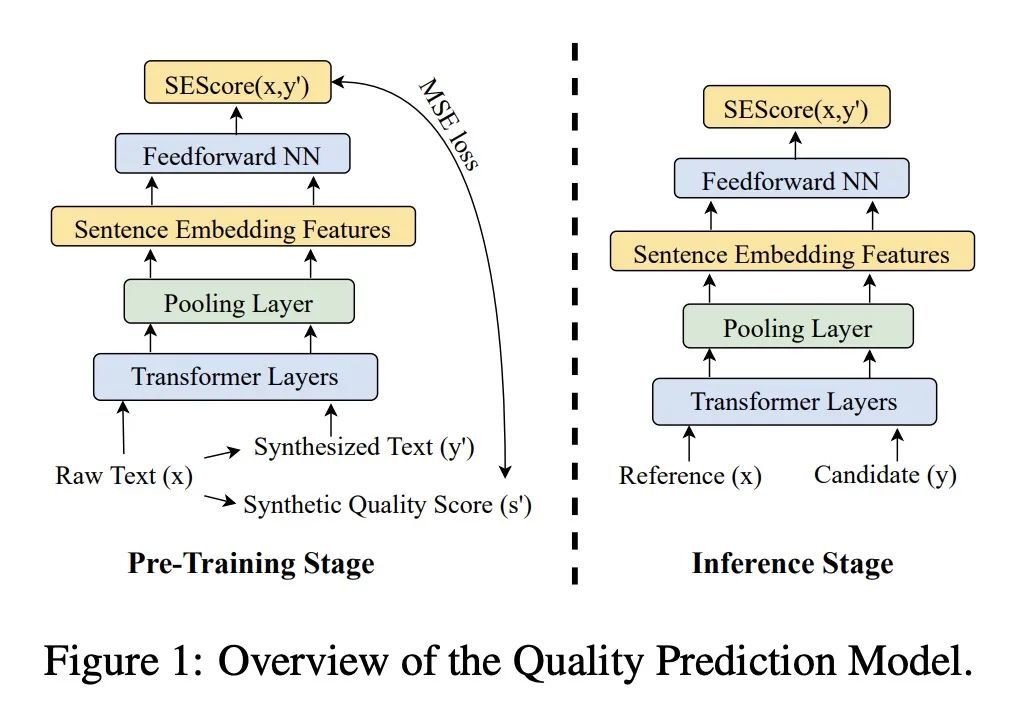
[CL] Not All Errors are Equal: Learning Text Generation Metrics using Stratified Error Synthesis
所有错误并非一律平等:基于分层错误合成的文本生成指标学习W Xu, Y Tuan, Y Lu, M Saxon, L Li, W Y Wang
[UC Santa Barbara]
https://arxiv.org/abs/2210.05035


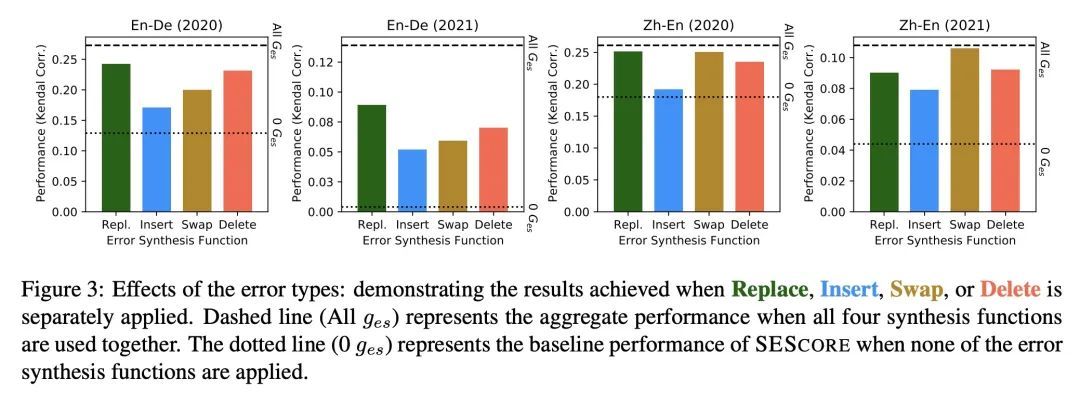
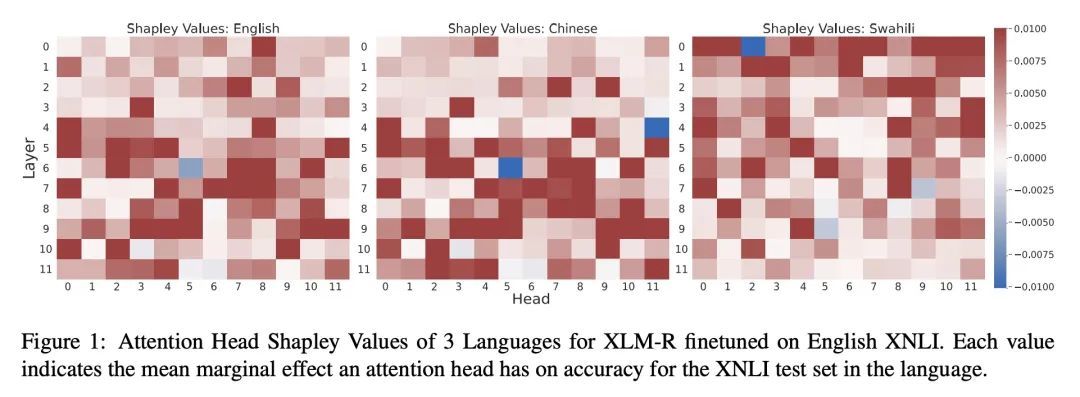
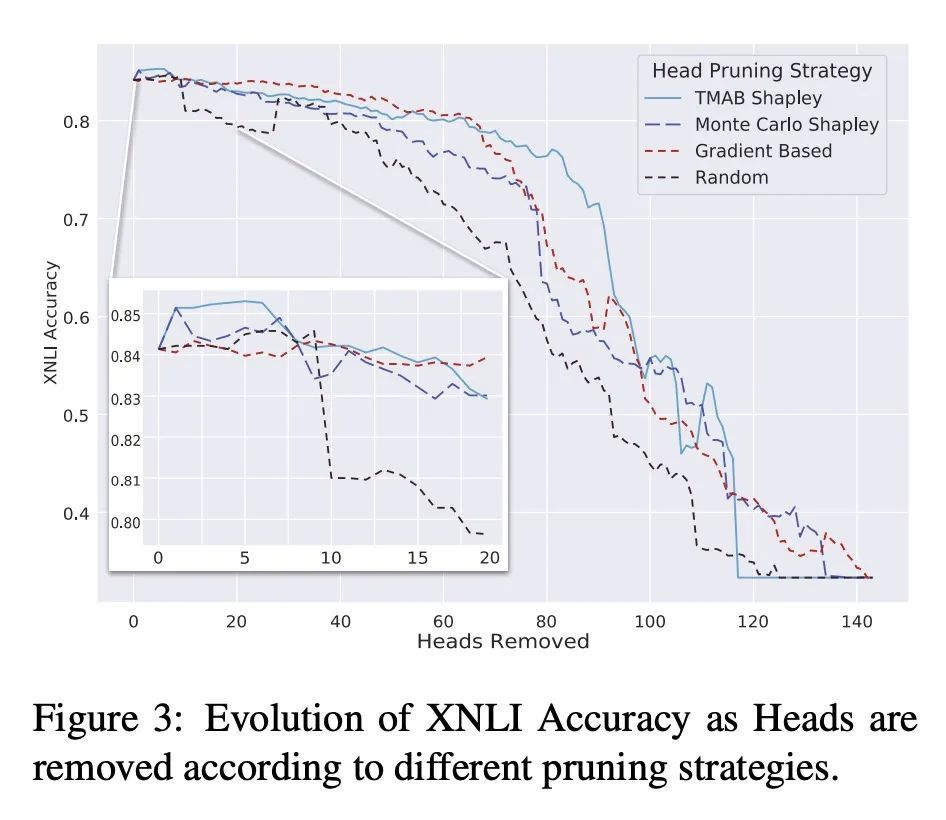
[CL] Shapley Head Pruning: Identifying and Removing Interference in Multilingual Transformers
Shapley Head Pruning:识别和消除多语言Transformer中的干扰
W Held, D Yang
[The Georgia Institute of Technology & Stanford University] https://arxiv.org/abs/2210.05709


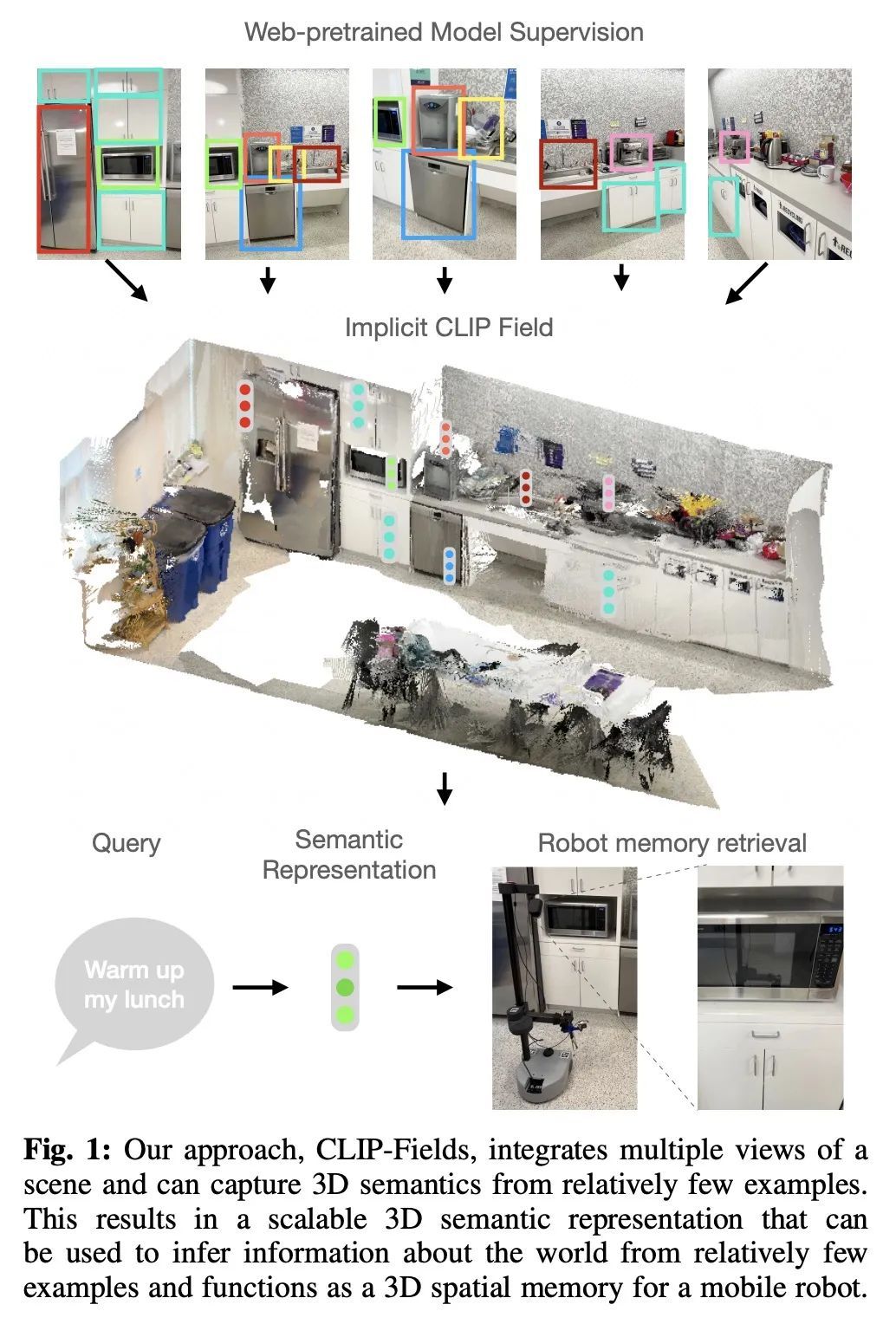
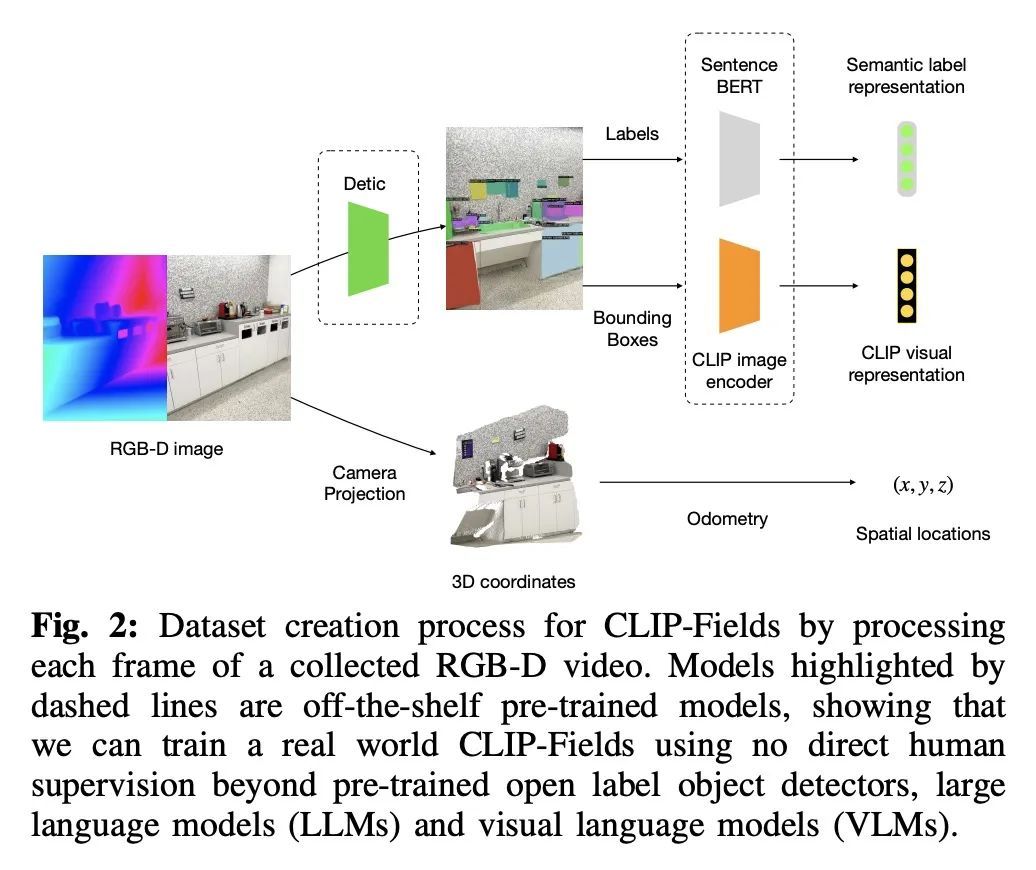
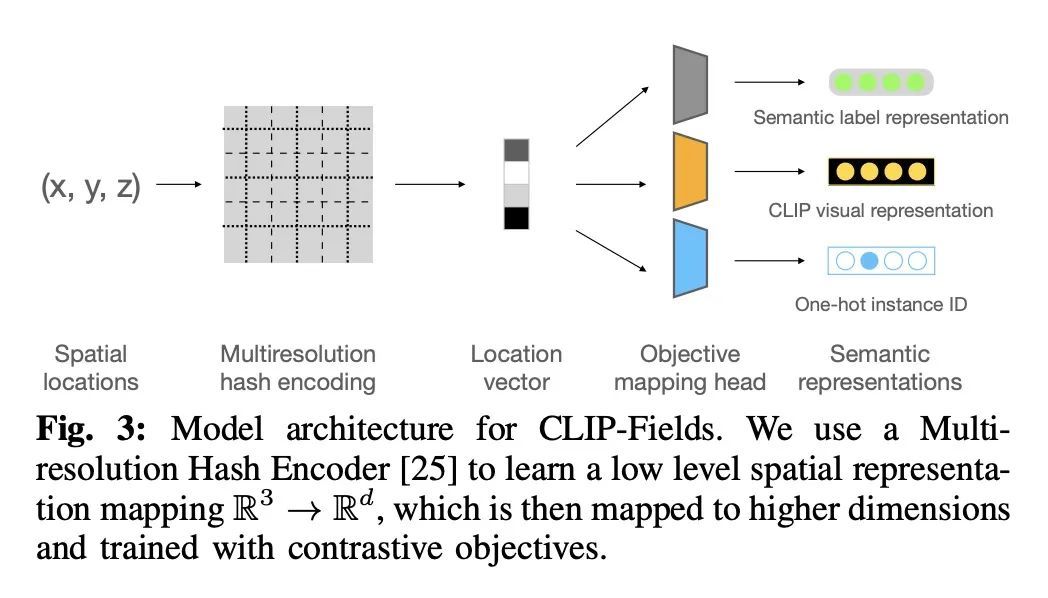
[RO] CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory
CLIP-Fields:机器人记忆弱监督语义场
N M M Shafiullah, C Paxton, L Pinto, S Chintala, A Szlam
[New York University & FAIR Labs]
https://arxiv.org/abs/2210.05663

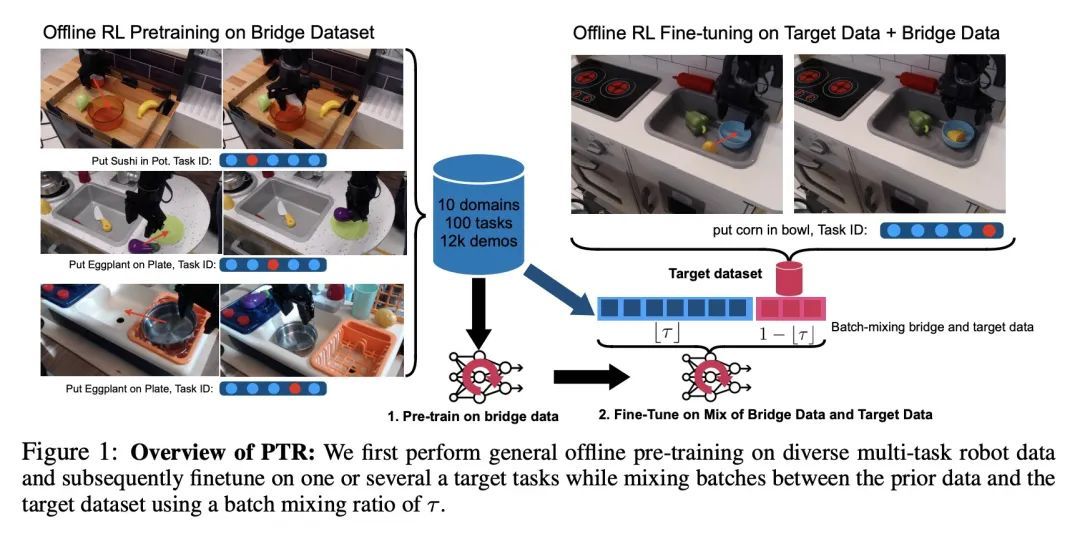
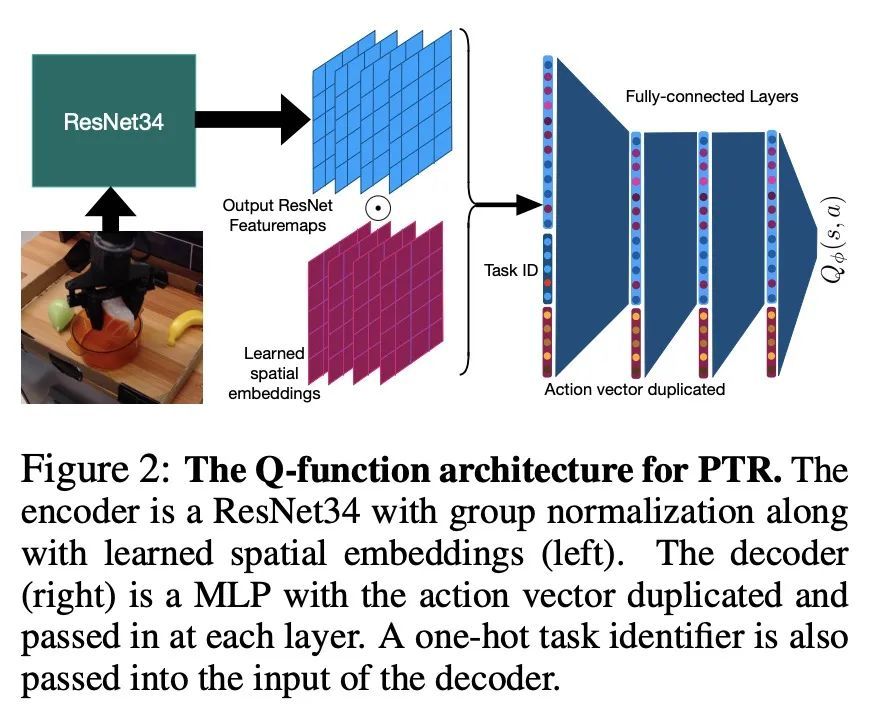
[RO] Pre-Training for Robots: Offline RL Enables Learning New Tasks from a Handful of Trials
机器人预训练:用离线强化学习从少量试错学习新任务
A Kumar, A Singh, F Ebert, Y Yang, C Finn, S Levine
[UC Berkeley & Stanford University]
https://arxiv.org/abs/2210.05178

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢