
关于周刊:
关于周刊订阅:
告诉大家一个好消息,《强化学习周刊》开启“订阅功能”,以后我们会向您自动推送最新版的《强化学习周刊》。订阅方法:
1,注册智源社区账号
2,点击周刊界面左上角的作者栏部分“强化学习周刊”(如下图),进入“强化学习周刊”主页。

3,点击“关注TA”(如下图)
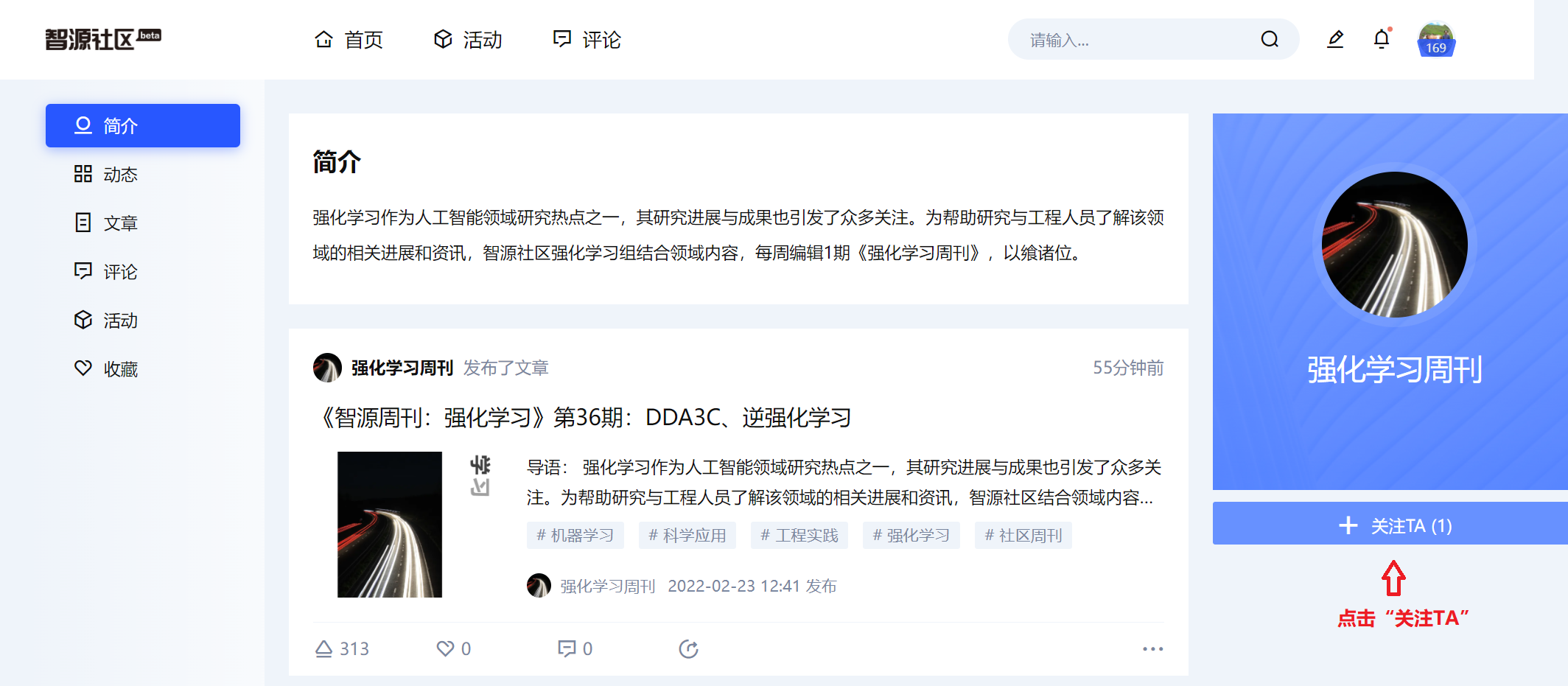
4,您已经完成《强化学习周刊》订阅啦,以后智源社区会自动向您推送最新版的《强化学习周刊》!
导语:
强化学习作为人工智能领域研究热点之一,其在人工智能领域以及学科交叉研究中的突出表现,引起越来越多的研究人员对该领域的关注。为更好地服务相关研究人员及时了解强化学习领域的研究进展以及科研资讯,智源社区结合以前工作基础及读者反馈,在论文推荐基础之上新增科研资讯、学术讲座、强化学习教程、相关招聘等板块,撰写为第63期《强化学习周刊》以飨诸位。
周刊采用社区协作的模式产生,欢迎感兴趣的朋友们参与我们的工作,一起来推动强化学习社群的分享、学习和交流活动。社区将定期为推动强化学习社群建设表现优异的同学提供精美的奖品。可以扫描文末的二维码加入强化学习社区群。
本期贡献者:(李明,刘青、小胖)
导读
强化学习已经成为人工智能研究领域的热点,其在各个应用领域中取得了瞩目的成就。《强化学习周刊》共分四个板块,论文推荐板块为读者梳理了Nips2022的9篇强化学习相关研究论文,其中涉及到推荐系统方向、组合优化应用方向、分布式自适应元强华学习、图像合成应用方向、可解释强化学习方向等;科研资讯为读者分享来自DeepMind强势推出的AlphaTensor论文,该算法是首个用于发现任意矩阵乘法的有效且证明正确的算法;本次招聘版块为大家介绍来自西湖大学系统神经科学与神经工程实验室的博士后招聘职位---脑认知+深度强化学习交叉学科方向;本次教程推荐板块为大家分享斯坦福大学CS234强化学习课程2022最新版,该教程通过讲座、书面作业和编码作业的结合,学生通过该课程将精通RL的关键思想和技术。
论文推荐
NeurIPS2022(Thirty-sixth Conference on Neural Information Processing Systems,第三十六届神经信息处理系统会议)是一年一度的国际人工智能顶会,今年将在11月28日星期一至12月9日星期五举办,第一周在新奥尔良会议中心举行物理会议,第二周举行虚拟会议。本次周刊为各位读者分享其中9篇有关强化学习的研究论文。
标题:DreamShard: Generalizable Embedding Table Placement for Recommender Systems(莱斯大学:Daochen Zha | DreamShard:推荐系统的通用嵌入表放置)
简介:本文研究了分布式推荐系统的嵌入表布局,其目的是将表划分并放置在多个硬件设备(如GPU)上,以平衡计算和通信成本。尽管现有研究已经探索了基于学习的计算图设备放置方法,但嵌入表放置仍然是一个具有挑战性的问题,由于嵌入表的操作融合,以及具有不同表数和/或设备数的不可见放置任务的泛化要求。故本文提出了DreamShard,一种用于嵌入表位置的强化学习(RL)方法。DreamShard通过一个成本网络来直接预测融合操作的成本,以及一个策略网络来实现操作融合和泛化的推理,该策略网络在没有实际GPU执行的情况下,根据估计的马尔可夫决策过程(MDP)进行有效训练,其中状态和回报是通过成本网络来估计的。这两个网络配备了总和和最大表示约简,可以直接推广到具有不同表数和/或设备数的任何看不见的任务,而无需进行微调。大量实验表明,DreamShard大大优于现有的人类专家和基于RNN的策略,在大型合成表和生产表的最强基线上,加速率高达19%。
论文链接:https://arxiv.org/pdf/2210.02023.pdf
阅读详情
标题:DIMES: A Differentiable Meta Solver for Combinatorial Optimization Problems(伊利诺伊大学香槟分校:Ruizhong Qiu | DIMES:组合优化问题的可微元解法)
简介:最近,深度强化学习(DRL)模型在解决NP难组合优化(CO)问题方面显示出了良好的结果。然而,对于图上的组合优化问题,如旅行推销员问题(TSP),大多数DRL求解器只能扩展到几百个节点。本文通过提出一种新的方法,即DIMES,解决了大规模组合优化中的可扩展性挑战。与以前的DRL方法不同,该方法需要昂贵的自回归解码或离散解的迭代细化,DIMES引入了一个紧凑的连续空间,用于参数化候选解的潜在分布。这样的连续空间允许通过大规模并行采样进行稳定的基于增强的训练和微调。并进一步提出了一个元学习框架,以便在微调阶段有效初始化模型参数。大量实验表明,对于Traveling Salesman问题和Maximal Independent Set问题,DIMES在大型基准数据集上的性能优于最近基于DRL的方法。
论文链接:https://arxiv.org/pdf/2210.04123.pdf
阅读详情
标题:Decomposed Mutual Information Optimization for Generalized Context in Meta-Reinforcement Learning(香港大学:Yao Mu | 元强化学习中广义上下文的分解互信息优化)
简介:适应过渡动力学的变化在机器人应用中至关重要。通过学习具有紧凑上下文的条件策略,上下文感知元强化学习提供了一种根据动态变化调整行为的灵活方法。然而,在实际应用中,智能体可能会遇到复杂的动态变化。多个混杂因素会影响过渡动态,因此难以为决策推断准确的背景。本文通过上下文学习的分解互信息优化(DOMINO)解决了这一挑战,DOMINO明确地学习一个不纠缠的上下文,以最大化上下文和历史轨迹之间的互信息,同时最小化状态转移预测误差。通过理论分析表明,DOMINO可以通过学习非纠缠上下文来克服由多个混淆挑战引起的对互信息的低估,并减少在不同环境中收集的样本数量的需求。大量实验表明,DOMINO学习的上下文对基于模型和无模型的强化学习算法在未知环境中的样本效率和性能方面都有利于动力学泛化。
论文链接:https://arxiv.org/pdf/2210.04209.pdf
阅读详情
标题:Reinforcement Learning with Automated Auxiliary Loss Search(上海交大:Tairan He | 自动辅助损失搜索的强化学习)
简介:良好的状态表示对于解决复杂的强化学习(RL)挑战至关重要。现有研究都侧重于为学习信息表示设计辅助损失。然而,此类手工目标严重依赖于专家知识,可能是次优的。本文提出了一种学习辅助损失函数更好表示的原则性通用方法,称为自动辅助损失搜索(A2LS),它可以自动搜索RL的最佳辅助损失函数。即基于收集的轨迹数据,定义了一个大小为7.5×10^{20}的一般辅助损失空间,并使用有效的进化搜索策略来探索该空间。实验结果表明,发现的辅助损失(即A2优胜者)显著提高了高维(图像)和低维(矢量)看不见任务的性能,效率更高,显示出对不同设置甚至不同基准域的良好泛化能力。通过统计分析,以揭示辅助损耗模式与RL性能之间的关系。
论文链接:https://arxiv.org/pdf/2210.06041.pdf
阅读详情
标题:Distributionally Adaptive Meta Reinforcement Learning(Improbable人工智能实验室: Anurag Ajay|分布式自适应元强化学习)
简介:元强化学习算法提供了一种数据驱动的方式来获取策略,这些策略可以快速适应具有不同奖励或动态函数的许多任务。然而,学习到的元策略通常只对他们接受训练的确切任务分布有效,并且在测试时间奖励的分布变化或过渡动态的存在下努力。本文为元强化学习算法开发了一个框架,该框架能够在任务空间中的测试时间分布变化下表现适当。本文框架集中在分布稳定性的自适应方法上,该方法训练大量元策略对不同水平的分布变化具有稳定性。当对可能发生变化的测试时间分布的任务进行评估时,能够选择具有最合适稳定性水平的元策略,并用它来进行快速适应。实验正式展示此框架如何在分布变化下改善缺陷,并通过经验证明其在广泛分布变化下模拟机器人问题的有效性。
论文链接:https://arxiv.org/pdf/2210.03104.pdf
阅读详情
标题:S2P: State-conditioned Image Synthesis for Data Augmentation in Offline Reinforcement Learning(首尔大学: Daesol Cho|S2P:用于离线强化学习中数据增强的状态条件图像合成)
简介:离线强化学习 (Offline RL) 存在先天的分布变化,因为它在训练期间无法与物理环境进行交互。为了缓解这种限制,基于状态的离线强化学习利用从记录经验中学习到的动态模型,并增强预测的状态转换以扩展数据分布。为了在基于图像的 RL 上也利用这种优势,本文首先提出了一个生成模型 S2P (State2Pixel),它从相应的状态合成智能体的原始像素。它可以在 RL 算法中弥合状态和图像域之间的差距,并通过状态空间中基于模型的转换虚拟地探索看不见的图像分布。实验证明,基于 S2P 的图像合成不仅提高了基于图像的离线 RL 性能,而且对未知任务具有很强的泛化能力。
论文链接:https://arxiv.org/pdf/2209.15256.pdf
阅读详情
标题:ASPiRe:Adaptive Skill Priors for Reinforcement Learning(哥伦比亚大学: Mengda Xu|ASPiRe:强化学习的自适应技能先验)
简介:本文提出了 ASPiRe(RL 的自适应技能先验),一种利用先前经验加速强化学习的新方法。与从庞大且多样化的数据集中学习单一技能先验的现有方法不同,本文的框架从一组专门的数据集中学习不同区分技能先验(即行为先验)的库,并学习如何将它们结合起来解决新任务。 该概念允许算法获得一组更可重用于下游任务的专业技能先验;然而,它也带来了额外的挑战,即如何有效地结合这些非结构化的技能先验集,为新任务形成新的先验知识。具体来说,它要求智能体不仅要确定要使用哪种技能先验,还要确定如何将它们组合(顺序或同时)以形成新的先验。为了实现这一目标,ASPiRe 包含自适应权重模块 (AWM),该模块学习推断不同技能先验之间的自适应权重分配,并使用它们通过加权 Kullback-Leibler 散度指导下游任务的策略学习。
论文链接:https://arxiv.org/pdf/2209.15205.pdf
阅读详情
标题:Enhanced Meta Reinforcement Learning using Demonstrations in Sparse Reward Environments(德州农工大学: Desik Rengarajan|在稀疏奖励环境中使用演示增强元强化学习)
简介:元强化学习 (Meta-RL) 是一种从解决各种任务中获得的经验被提炼成元策略的方法。元策略只经过少量(或单一)步骤的调整,就能够在新的相关任务上接近最佳地执行。然而,采用这种方法来解决现实世界问题的一个主要挑战是它们通常与稀疏奖励函数相关联,这些奖励函数只表明一个任务是部分还是全部完成。本文考虑的情况是,每个任务都有一些数据,可能是由一个次优智能体产生的。然后,此文开发了一类名为“使用演示增强元强化学习”(EMRLD)的算法,利用这些信息,即使是次优的,也能在训练中获得指导。文中展示了 EMRLD 如何在离线数据上联合利用RL和监督学习来产生一个展示单调性能改进的元策略的。文中展示 EMRLD 算法在各种稀疏奖励环境(包括移动机器人)中的表现明显优于现有方法。
论文链接:https://arxiv.org/pdf/2209.13048.pdf
阅读详情
标题:Reinforcement Learning with Non-Exponential Discounting(达姆施塔特工业大学: Matthias Schultheis|非指数折现的强化学习)
简介:在强化学习(RL)中,通常使用指数函数来模拟时间偏好,将奖励随时间折现,从而约束预期的长期奖励。相反,在经济学和心理学中,已经证明人类经常采用双曲折现方案,当假设特定的任务终止时间分布时,这种方案是最佳的。本文提出了一个基于连续时间模型的强化学习理论,并将其推广到任意的折现函数。这一表述涵盖了存在非指数随机终止时间的情况。文中推导出一个Hamilton-Jacobi-Bellman(HJB)方程,描述了如何使用拼合方法解决该问题,该方法使用深度学习进行函数近似。此外,本文展示了如何处理逆向RL问题,研究人员尝试恢复给定决策数据的折扣函数的属性。文中在两个模拟问题上验证了所提出的方法的适用性。本文的方法为分析人类在连续决策任务中的折扣开辟了道路。
论文链接:https://arxiv.org/pdf/2209.13413.pdf
阅读详情
标题:Explainable Reinforcement Learning via Model Transforms(雅盖隆大学: Mira Finkelstein|通过模型转换进行可解释的强化学习)
简介:理解强化学习(RL)智能体新出现的行为可能是困难的,因为这种智能体通常是在复杂的环境中使用高度复杂的决策程序进行训练。这就产生了各种用于解释RL的方法,旨在调和智能体的行为和观察者所预期的行为之间可能出现的差异。最近的大多数方法依赖于领域知识、对智能体的策略的分析,或者对底层环境的特定元素的分析,通常被建模为马尔科夫决策过程(MDP)。本文主张即使底层MDP不完全已知或没有被智能体维护(当使用无模型方法时),它仍然可以被利用来自动生成解释。为此,本文建议使用正式的MDP抽象和转换,以前在文献中用于加速寻找最优策略,以自动产生解释。由于这种变换通常是基于环境的符号表示,它们可以代表对预期和实际智能体行为之间的差距的有意义的解释。本文正式定义了这个问题,提出了一类可用于解释突发行为的变换,并提出了能够有效搜索解释的方法。
论文链接:https://arxiv.org/pdf/2209.12006.pdf
阅读详情
科研资讯
标题:Nature封面论文:DeepMind强势推出AlphaTensor
简介:最新一期Nature的封面论文中,DeepMind提出AlphaTensor这一Alpha系列智能家族新成员,其用于自动发现算法获得广大科研人员的关注。提高基础计算算法的效率会产生广泛的影响,矩阵乘法就是这样一项原始任务,发生在许多系统中。使用机器学习自动发现算法提供了超越人类直觉并超越当前最佳人工设计算法的前景。DeepMind 科研人员报告了一种基于 AlphaZero的深度强化学习方法-- AlphaTensor,这是首个用于发现任意矩阵乘法的有效且证明正确的算法。智能体AlphaTensor 发现的算法在许多矩阵大小上都优于最先进的复杂性。特别相关的是有限域中 4 × 4 矩阵的情况,AlphaTensor 的算法在 50 年间首次改进了 Strassen 的两级算法。实验结果突出了 AlphaTensor 在一系列问题上加速算法发现过程并针对不同标准进行优化的能力。未来,DeepMind 希望基于他们的研究,更多地将人工智能用来帮助社会解决数学和科学领域的一些最重要的挑战。
资讯链接:https://www.nature.com/articles/s41586-022-05172-4?utm_source=xmol&utm_medium=affiliate&utm_content=meta&utm_campaign=DDCN_1_GL01_metadata
阅读详情
相关招聘
标题:西湖大学系统神经科学与神经工程实验室招聘博士后---脑认知+深度强化学习交叉学科方向
描述:生命科学学院系统神经科学与神经工程实验室(孙一实验室)以社会认知的神经网络计算原理为研究对象,以神经环路与行为为研究主线,以先进技术特别是功能成像技术为研究特点,以果蝇为主要实验模型。将与西湖大学工学院机器智能实验室紧密合作,从事与实验室研究方向一致的研究与创新及其他事宜,并开展 “脑认知+深度强化学习”的交叉学科研究。机器智能实验室(王东林实验室)专注于强化学习、深度学习和机器人智能化应用等领域的前沿研究,实验室PI王东林博士担任国家科技创新2030重大项目首席科学家。具体职位要求以及薪酬待遇详见链接。
招聘链接:https://www.westlake.edu.cn/Careers/OpenPositions/202210/t20221010_22931.shtml
阅读详情
教程推荐
标题:斯坦福大学CS234强化学习课程2022最新版
简介:要实现人工智能的梦想和影响,需要学会做出正确决策的自主系统。强化学习是这样做的一个强大范例。本课程将对强化学习领域进行扎实的介绍,学生将学习核心挑战和方法,包括概括和探索。通过讲座、书面作业和编码作业的结合,学生将精通RL的关键思想和技术。作业将包括强化学习和深度强化学习的基础知识。
教程链接:http://web.stanford.edu/class/cs234/index.html
B站视频:https://www.bilibili.com/video/BV18N4y1A7jd/
阅读详情
如果你正在从事或关注强化学习研究、实现与应用,欢迎加入“智源社区-强化学习-交流群”。在这里,你可以:
学习前沿知识、求解疑难困惑
分享经验心得、展示风貌才华
参与专属活动、结识研究伙伴
请扫描下方二维码加入。 备注:“姓名+单位+强化学习”才会验证进群哦。
内容中包含的图片若涉及版权问题,请及时与我们联系删除



评论
沙发等你来抢