

标题:「SelfMix」: Robust Learning Against Textual Label Noise with Self-Mixup Training
录取:COLING2022 Oral
链接:https://arxiv.org/abs/2210.04525
Github:「SelfMix & Baselines」: https://github.com/noise-learning/SelfMix
数据的标签错误随处可见,如何在噪声数据集上学习到一个好的分类器,是很多研究者探索的话题。在 Learning With Noisy Labels 这个大背景下,很多方法在图像数据集上表现出了非常好的效果。
而文本的标签错误有时很难鉴别。比如对于一段文本,可能专家对于其主旨类别的看法都不尽相同。这些策略是否在语言模型,在文本数据集上表现好呢?本文探索了文本噪声标签在预训练语言模型(PLMs)上的特性,提出了一种新的学习策略 SelfMix,并机器视觉上常用的方法应用于预训练语言模型作为 baseline。
为什么选 PLMs
我们对于常见语言分类模型在带噪文本数据集上做了一些前期实验,结果如下:
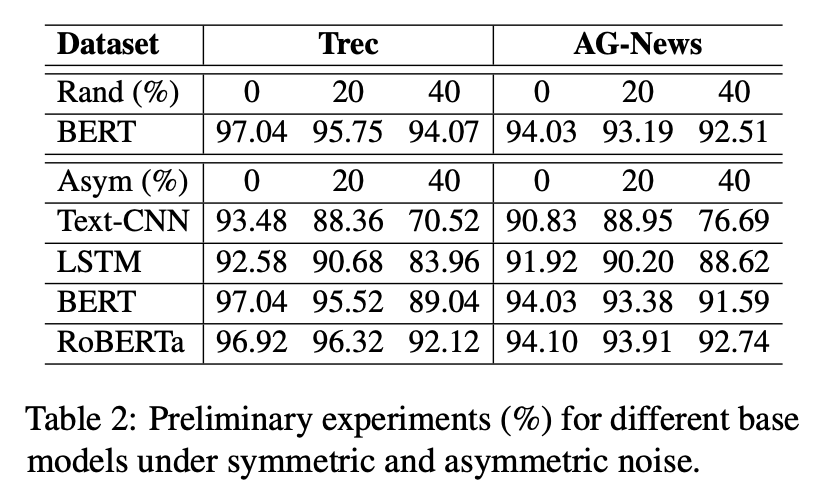
首先,毫无疑问,预训练模型(BERT,RoBERTa)的表现更好。其次,文章提到,预训练模型已经在大规模的预训练语料上获得了一定的类别先验知识。故而在有限轮次训练之后,依然具有较高的准确率,如何高效利用预训练知识处理标签噪声,也是一个值得探索的话题。
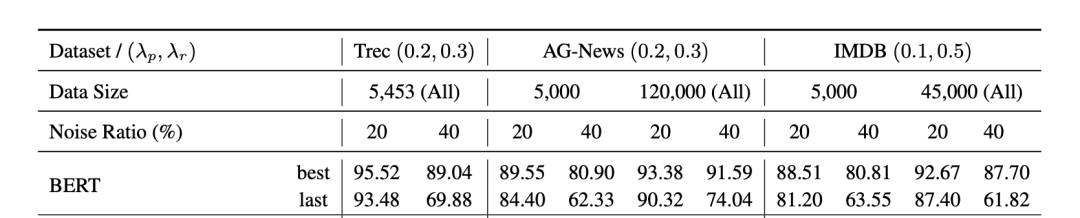
预训练模型虽然有一定的抗噪学习能力,但在下游任务的带噪数据上训练时也会受到噪声标签的影响,这种现象在少样本,高噪声比例的设置下更加明显。
方法
由此,我们提出了 SelfMix,一种对抗文本噪声标签的学习策略。
基础模型上,我们采用了 BERT encoder + MLP 这一常用的分类范式。
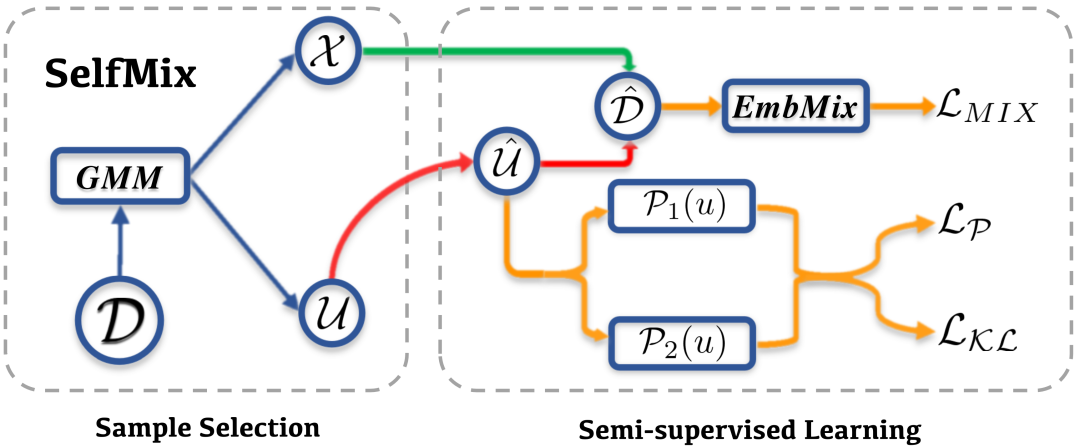
针对带噪学习策略,主要可以分为两个部分
- Sample Selection
- Semi-supervised Learning
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢