
UIE模型是百度今年开源出来的可以应用于zero-shot的新模型,其功能强大使用简便,虽不至于将NLP带入一个新的阶段,但也确实极大的降低了NLP基础任务的工程化使用门槛,是一个非常有效的工具。
近期花了一些时间来阅读UIE的源码和论文,也做了一些实践,看了许多文章,作为总结性的文档,本文从读UIE源码后的一点感受,围绕到底是哪个UIE?、paddle和原版的UIE、UIE真是“大一统么以及UIE为什么有效等几个方面进行介绍,供大家参考。
当然,只是个人的一些理解,仅供参考与批评。
一、从读UIE源码后的一点感受谈起
前段时间百度推出的UIE模型在各个NLP相关的公众号刷屏,基本上都是以“大一统”的字眼进行介绍的,出于好奇,我也安装了paddle,体验了一把这个模型。
>>> from pprint import pprint>>> from paddlenlp import Taskflow
>>> schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction>>> ie = Taskflow('information_extraction', schema=schema)>>> pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint
[{'时间': [{'end': 6,
'probability': 0.9857378532924486,
'start': 0,
'text': '2月8日上午'}],
'赛事名称': [{'end': 23,
'probability': 0.8503089953268272,
'start': 6,
'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],
'选手': [{'end': 31,
'probability': 0.8981548639781138,
'start': 28,
'text': '谷爱凌'}]}]根据官方的提示,果不其然地获取到了不错的结果,这也是prompt这一概念一年前提出到现在,我第一次接触到从应用角度来讲,令我感到惊喜的模型。但是惊喜之余,仔细揣摩了一番,又感觉这个“大一统”的模型似乎并没有特别新奇之处。
这几天读了一遍UIE的源码,给大家分享几点感触:
UIE的原理是什么,最核心在于构造了一个针对不同任务【实体识别,关系抽取,事件抽取,情感分析等】的统一输出样式,其他并无重大创新。本质上SSI就是schema,SEL是形式化后的预测格式,相当于是对齐了T5的输入输出,整个代码的核心是数据格式的转换【大部分代码】,底层模型使用的就是Seq2seq的预测模型。
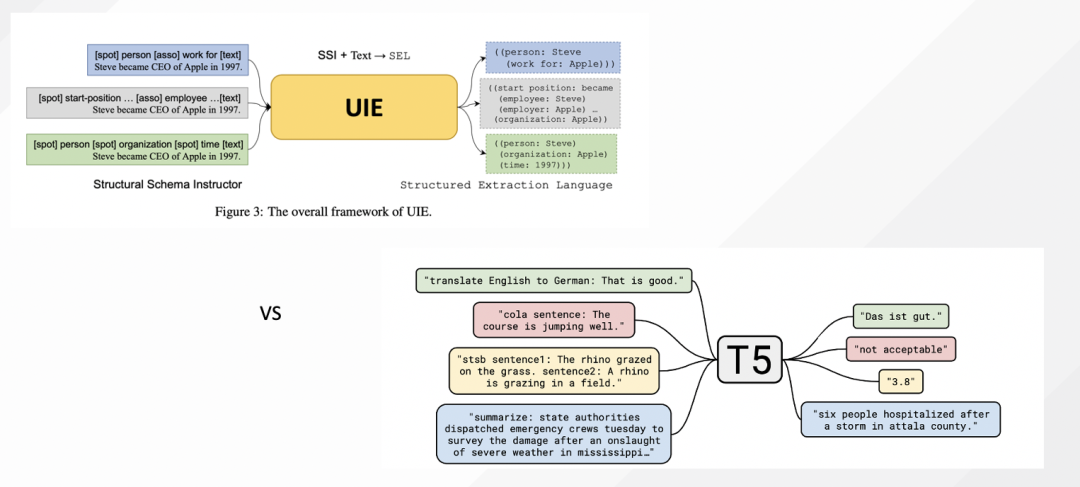
- 如果要起底它,其实是Bart/T5的一个延伸而已,把预测阶段把输入输出对齐到了T5上。
- UIE的可贵之处,在于其预训练数据和训练模型,而不在于其统一任务的格式【非核心】。
- 进一步延伸到prompt,若要起底,可能还是T5【当时出来的时候,加在text前的prefix,就是现在的prompt,只是没那么叫】,学界目前更多的是把这个prefix抽离出来,并一顿规范、抽离,称之为prompt learning。
- 进一步延伸到现在UIE等方法的屠榜,大胆的认为,本质上是归结于大模型本身,而且大模型作为一个参数化的大知识图谱可能是成立的【我们不知道里面还有什么,能有什么,既然已经喂了几十T的数据】,比如在kgclue榜单,作为单跳问答score已经到0.99了,而我们看ernie的训练数据本身就有问答数据,百科数据,所以这个测试集的答案本身就包含在预训练任务当中的【俗称泄露穿越】,这也说明了预训练模型的后续方向就变成了"通过某种方式,向它套取东西,套取形式化的数据",而这种方式,就是模板,就是与预训练任务对齐的完形填空【T5】或者干扰【Bart】等。形式化的数据,可能就是某种迁移能力,或者直接的内含结果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢