

论文链接:https://arxiv.org/abs/2208.12675
项目主页:https://cyj407.github.io/DiSS/
代码仓库:https://github.com/cyj407/DiSS(尚未开源)
导读
从草图或素描生成图像是内容创作领域中一项非常重要的基本任务,在生成对抗网络(GAN)兴起的时代,研究者们往往会把这项任务表述成为图像到图像的转换(Pixel to Pixel,Image to Image),但是这种生成模式比较固定,即训练好一个模型只能完成一种类型的生成任务,当遇到输入是手绘草图的情况时,就需要更多的模型,因为不同的用户绘制出来的草图可能呈现出完全不同的风格。
但是在扩散模型(diffusion models)快速发展的今天,这种生成缺陷有望得到解决,本文作者提出了一种相对统一的框架,支持对用户输入的草图和笔画进行三维控制,用户不仅可以控制每个笔画的倾向程度,还可以决定该笔画生成的真实程度。此外基于扩散模型本身具有的高质量图像合成和稳定训练的特性,本文方法具有极高的生成灵活性,可以控制生成图像的形状、颜色和真实感。
贡献
在很多情景中,草图或者手绘图都是人类对一些特定物体和场景的抽象描述,它们代表了人们脑海中闪过的各种各样的奇思妙想,如果借助AI模型对用户手绘的图像进行真实图像合成就可以将人类创作与现实场景联系起来,激发出创作者更多的灵感,并且有效提高内容创作的工作效率。但现实情况是,从草图合成真实图像是一件非常棘手的事情,因为不同的用户输入往往代表了不同的期望输出,这给模型翻译带来了挑战。
本文基于扩散模型[1]提出了DiSS框架,DiSS可以直接从草图和轮廓图生成真实图像,并且实现了对输入的三维控制(轮廓、颜色、真实感)。在传统的图像翻译过程中,模型为了使得生成的图像效果更加逼真,往往需要对形状和颜色进行权衡考虑。因此DiSS首先考虑将形状和颜色这两大因素进行分离控制,在对形状和颜色进行解耦之后,DiSS可以更加灵活的定制生成过程,并且根据用户的需求分别调整采样结果。除此之外,本文作者提出了DiSS的第三个控制因素,真实感尺度(realism scale),对于该因素,作者通过对潜在特征变量不断的迭代调整,并且使用了一个低通滤波器来动态微调生成图像。
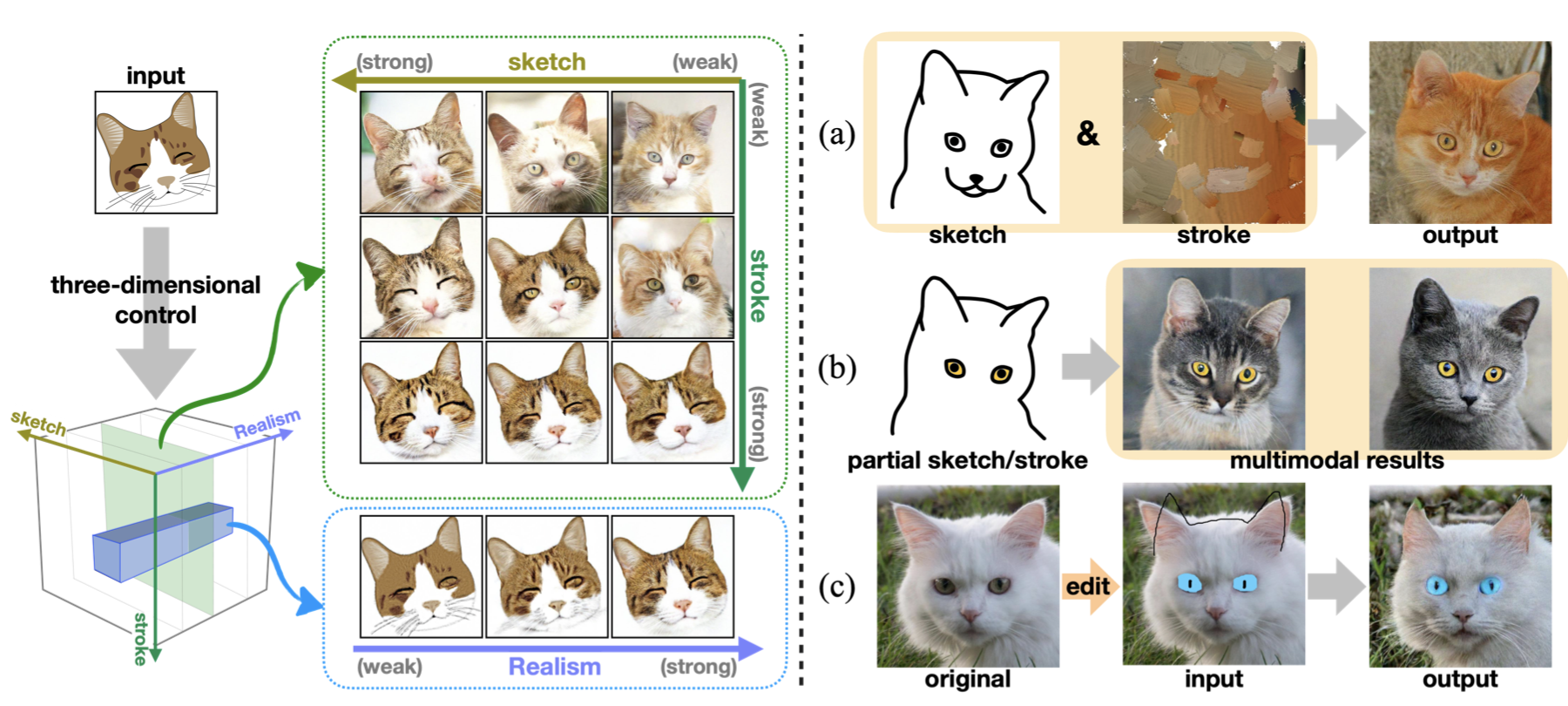
上图展示了DiSS的图像生成三维控制模式,其中用户可以灵活的控制输入草图和轮廓的各项参数,以及生成结果与真实图像之间的真实感尺度。此外,基于DiSS,本文作者还提出了几个与图像生成领域高度相关的几个新任务:图像的多条件局部编辑(multi-conditioned local editing)、给定区域的轮廓到图像转换(region-sensitive stroke-to-image),以及多模态多域图像合成(multi-domain sketch-to-image)。
方法
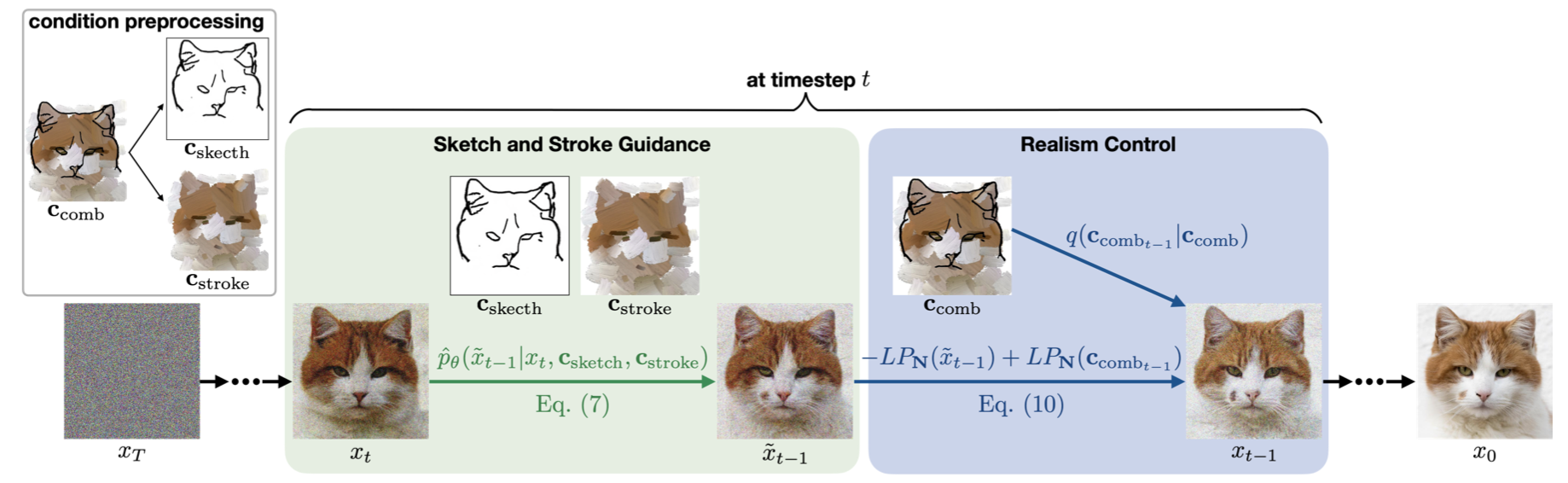
下图为DiSS整体框架的操作示意图,首先将草图(sketch)和轮廓图(stroke)进行整合作为整体的输入条件,然后进行sketch信息和stroke信息的分离控制引导,再经过最后的真实感控制,得到最终的图像合成结果,下面将详细介绍其中的技术细节。
2.1 扩散模型的预定义
去噪扩散概率模型(DDPM)本质上是一种生成模型,它采用去噪过程来表示从简单分布(通常是高斯分布)到目标分布的映射。其中前向扩散过程逐渐向目标分布采样的数据中添加噪声,而后向去噪过程则试图学习反向映射,这两个过程都被建模为马尔可夫链。当我们给定目标分布\( x_{0} \sim q(x_{0}) \) ,DDPM的前向扩散路径为马尔科夫链,通过 T 步将高斯噪声逐渐添加到x0 中:
\( q\left(x_{t} \mid x_{t-1}\right):=\mathcal{N}\left(x_{t} ; \sqrt{1-\beta_{t}} x_{t-1}, \beta_{t} \mathbf{I}\right) \)
为了精确地学习去噪过程,首先需要根据生成样本\( x_{t} \sim q\left(x_{t} \mid x_{0}\right) \) 训练模型ϵθ(xt,t) 去预测所添加的高斯噪声,并使用一个MSE损失进行优化:
\( L_{\text {simple }}:=E_{t \sim[1, T], x_{0} \sim q\left(x_{0}\right), \epsilon \sim \mathcal{N}(0, \mathbf{I})}\left[\left\|\epsilon-\epsilon_{\theta}\left(x_{t}, t\right)\right\|^{2}\right] \)
2.2 无分类器(classifier-free)扩散引导
为了根据给定的草图(sketch)和轮廓图(stroke)合成真实图像,本文的做法是先将sketch条件 \( \mathbf{C}_{\text {sketch }} \) 和 stroke条件\( \mathbf{C}_{\text {stroke }} \) 以及输入 \( x_t \) 进行拼接,作为U-Net模型的整体输入,基于上述扩散模型的目标转换形式,这里我们可以将生成映射形式化表示为:
\( \begin{array}{l} \hat{p}_{\theta}\left(\tilde{x}_{t-1} \mid x_{t}, \mathbf{c}_{\text {sketch }}, \mathbf{c}_{\text {stroke }}\right) \\ :=\mathcal{N}\left(\tilde{x}_{t-1} ; \mu_{\theta}\left(x_{t}, t, \mathbf{c}_{\text {sketch }}, \mathbf{c}_{\text {stroke }}\right), \Sigma_{\theta}\left(x_{t}, t, \mathbf{c}_{\text {sketch }}, \mathbf{c}_{\text {stroke }}\right)\right) \end{array} \)
接着,我们可以将本文的图像生成任务也转换为噪声预测任务,其中噪声信息为草图(sketch)和轮廓(stroke)信息,表示为\( \hat{\epsilon}_{\theta}\left(x_{t}, t, \mathbf{c}_{\text {sketch }}, \mathbf{c}_{\text {stroke }}\right) \) ,损失函数为:
\( \hat{L}_{\text {simple }}:=E_{t, x_{0}, \epsilon}\left[\left\|\epsilon-\hat{\epsilon}_{\theta}\left(x_{t}, t, \mathbf{c}_{\text {sketch }}, \mathbf{c}_{\text {stroke }}\right)\right\|^{2}\right] \)
为了对草图(sketch)和轮廓(stroke)信息进行分离控制,作者引入了一种classifier-free引导方法[2],并将其调整为二维控制形式,在具体实现中,作者采用了两阶段的训练策略,首先使用完整的草图和轮廓作为条件训练模型。然后对模型进行微调,将每种条件的30%随机替换为一幅灰色像素图像,记为∅ 。在采样过程中,使用两种信息的引导尺度\( s_{\text {sketch }},s_{\text {stroke }} \)的线性组合对两种信息进行权衡:
\( \begin{array}{l} \hat{\epsilon}_{\theta}\left(x_{t}, t, \mathbf{c}_{\text {sketch }}, \mathbf{c}_{\text {stroke }}\right)=\hat{\epsilon}_{\theta}\left(x_{t}, t, \emptyset, \emptyset\right) \\ +s_{\text {sketch }}\left(\hat{\epsilon}_{\theta}\left(x_{t}, t, \mathbf{c}_{\text {sketch }}, \emptyset\right)-\hat{\epsilon}_{\theta}\left(x_{t}, t, \emptyset, \emptyset\right)\right) \\ +s_{\text {stroke }}\left(\hat{\epsilon}_{\theta}\left(x_{t}, t, \emptyset, \mathbf{c}_{\text {stroke }}\right)-\hat{\epsilon}_{\theta}\left(x_{t}, t, \emptyset, \emptyset\right)\right) . \end{array} \)
得益于这种设置,使得DiSS可以在模型扩展中加入多种信息的生成引导。
2.3 真实感控制
上文提到,作者还在DiSS中加入了对真实感尺度的控制,这使得模型可以显示的控制生成图像的真实程度,作者使用了一种对潜在特征变量不断迭代细化的技术[3]在生成图像与目标数据分布之间进行调整,此外使用低通滤波操作 LPLP 对图像进行微调,然后上采样得到生成图像。假设给定真实感尺度 \( s_{\text {realism }} \sim[0,1] \)作为转换尺度的指示信息,然后再结合草图(sketch)和轮廓(stroke)信息的参考图像,我们可以将时间 t 步的真实感调节过程形式化表示为:
\( \begin{array}{l} \tilde{x}_{t-1} \sim \hat{p}_{\theta}\left(\tilde{x}_{t-1} \mid x_{t}, \mathbf{c}_{\text {sketch }}, \mathbf{c}_{\text {stroke }}\right) \\ x_{t-1}:=\tilde{x}_{t-1}-L P_{\mathbf{N}}\left(\tilde{x}_{t-1}\right)+L P_{\mathrm{N}}\left(\mathbf{c}_{\mathrm{comb} t-1}\right) \\ \text { in which } \mathbf{N}=-s_{\text {realism }}(\mathbf{m} / 8-1)+(\mathbf{m} / 8)+k \end{array} \)
其中 comb 表示草图(sketch)和轮廓(stroke)信息的组合。
实验
本文的实验部分在AFHQ、Landscapes和Oxford Flower三个数据集上进行,其中包含了丰富的草图和轮廓物象和意象。作者首先将DiSS的生成图像效果与现有的三种较为先进的图像生成方法进行了比较:
- U-GAT-IT是一种基于GAN的图像翻译方法,在测试U-GAT-IT时,作者将黑色草图与彩色轮廓叠加在一起形成绘图图像,将其作为输入图像,然后将相应的真实照片作为目标域图像训练模型。
- SSS2IS是一种基于GAN的自监督框架,它以黑色草图和风格图像作为输入,然后通过将风格图像替换为彩色轮廓图像来构成监督信号,通过计算真实图像和自编码器输出之间的回归损失来训练模型。
- SDEdit是一种基于扩散模型的轮廓图图像生成方法,为了构成引导信号,作者将草图图像与U-Net网络的原始输入进行拼接,同时在模型训练时使用草图作为条件信号参与训练。
下图详细的展示DiSS与上述三种方法的生成效果对比,与其他方法相比,DiSS在对象级(猫和花)和场景级(自然景观)数据集上得到了更加真实的结果。此外作者还观察到,DiSS对于轮廓图像所提供的不同层次的细节具有更好的鲁棒性,例如,在下图的第二行中,虽然轮廓图(stroke)没有明确指示出猫的眼睛位置,但是DiSS仍然可以精确的合成具有逼真效果的猫眼。


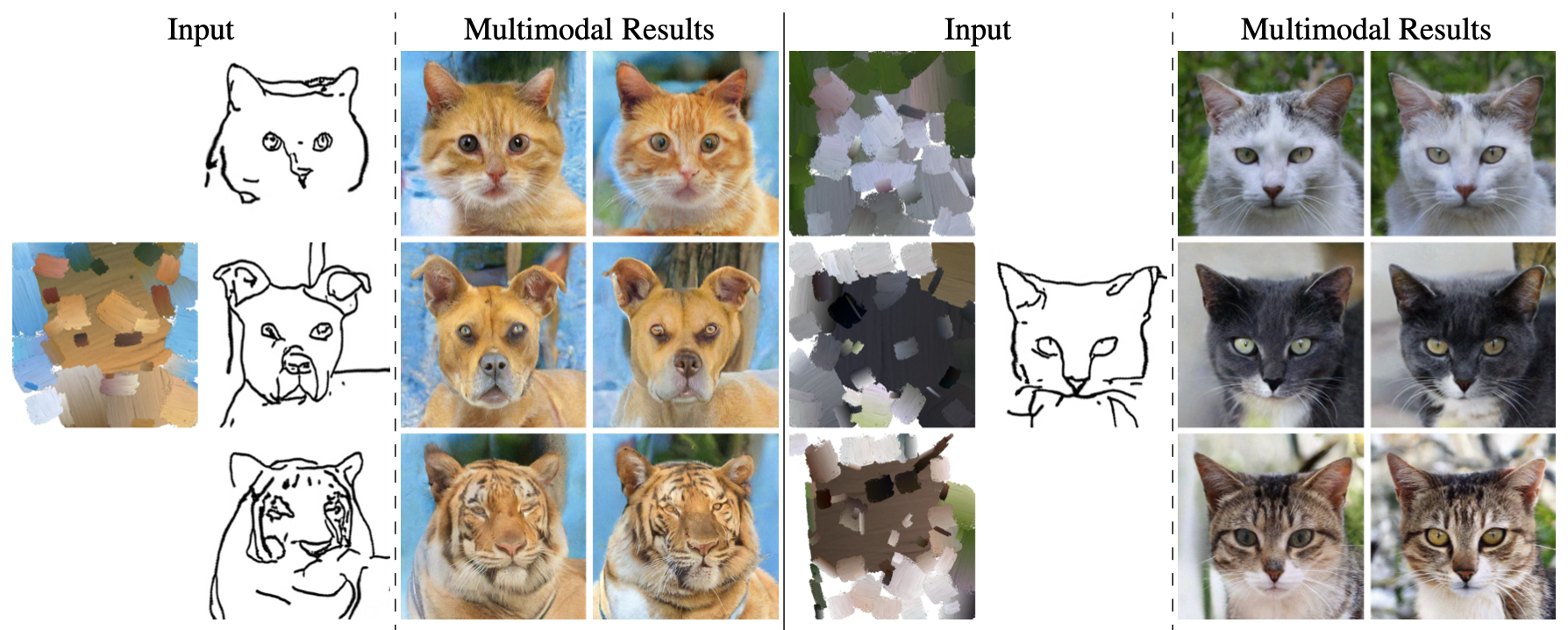
此外作者还展示了DiSS的多模态多域图像合成效果,如下图所示,DiSS可以接受来自不同域(即多模态)的图像进行统一的图像生成,下图中的所有图像(猫、狗以及其他的野生动物)都是使用同一个DiSS模型生成的,这表明DiSS可以理解输入草图中隐含的类别信息,
此外,DiSS借助于对生成过程的三维控制特性,还可以实现两个非常有趣的功能,即图像的多条件局部编辑和给定区域的轮廓到图像转换。作者还强调,对于这两个新功能无需重新训练新的模型,下图展示了可视化编辑的效果,作者在输入图像中重点标注了需要模型重点编辑的区域。

下图进一步展示了给定区域的轮廓到图像转换效果,该功能可以将草图和具有局部彩色轮廓的图像作为输入,进而产生具有更真实细节效果的图像。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢