
【标题】A Mixture of Surprises for Unsupervised Reinforcement Learning
【作者团队】Andrew Zhao, Matthieu Gaetan Lin, Yangguang Li, Yong-Jin Liu, Gao Huang
【发表日期】2022.10.13
【论文链接】https://arxiv.org/pdf/2210.06702.pdf
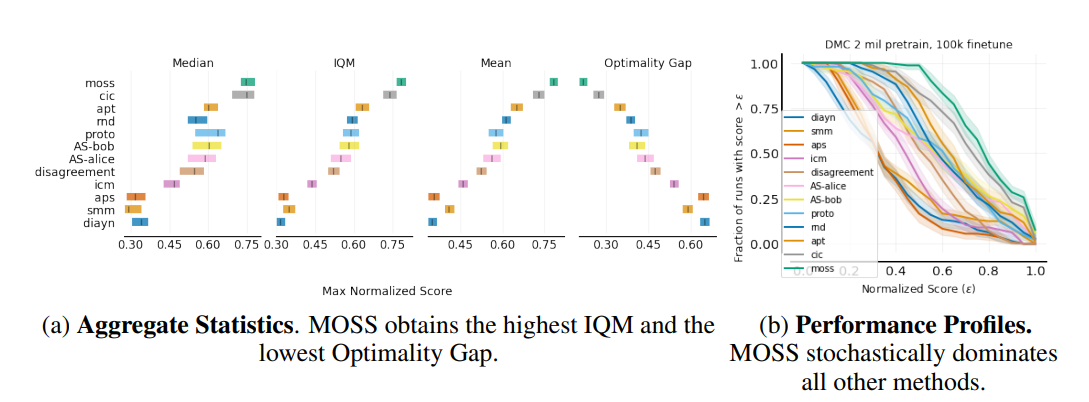
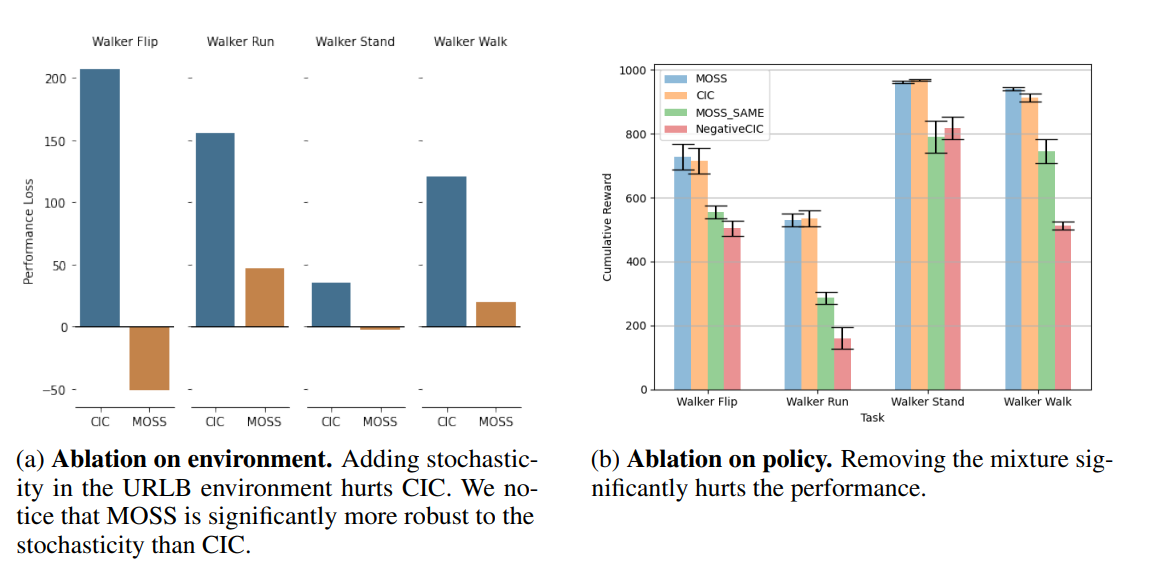
【推荐理由】无监督强化学习旨在以无奖励的方式学习通用策略,以快速适应下游任务。 大多数现有方法都建议提供基于惊喜的内在奖励。 最大化或最小化惊喜会促使智能体探索或控制其环境。 然而,这两种策略都依赖于一个强有力的假设:环境动态的熵要么高要么低。 这个假设在现实世界的场景中可能并不总是成立,因为环境动态的熵可能是未知的。 本文提出了一种新颖而简单的策略组合来解决这一问题。 具体来说,训练一个混合分量,其目标是最大化惊喜,另一个目标是最小化惊喜。 因此,本文的方法不对环境动态的熵做出假设。此方法称为无监督强化学习的 Mixture Of SurpriseS (MOSS)。 实验结果表明,本文的方法在 URLB 基准测试中实现了最先进的性能,优于以前基于惊喜最大化的目标。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢