
【标题】Model-Based Offline Reinforcement Learning with Pessimism-Modulated Dynamics Belief
【作者团队】Kaiyang Guo, Yunfeng Shao, Yanhui Geng
【发表日期】2022.10.13
【论文链接】https://arxiv.org/pdf/2210.06692.pdf
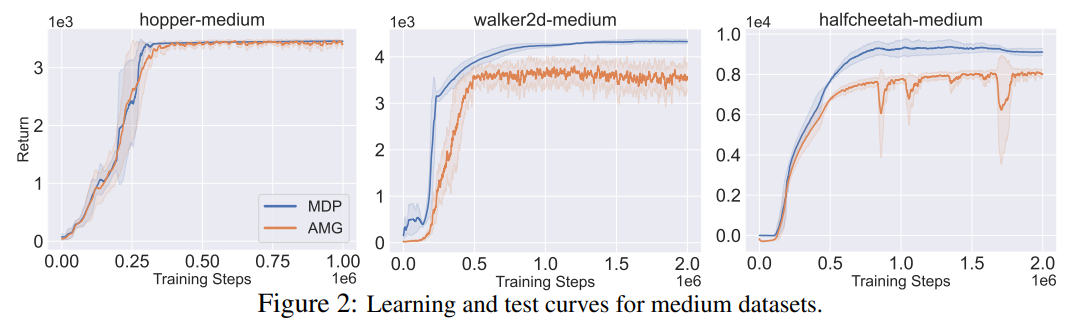
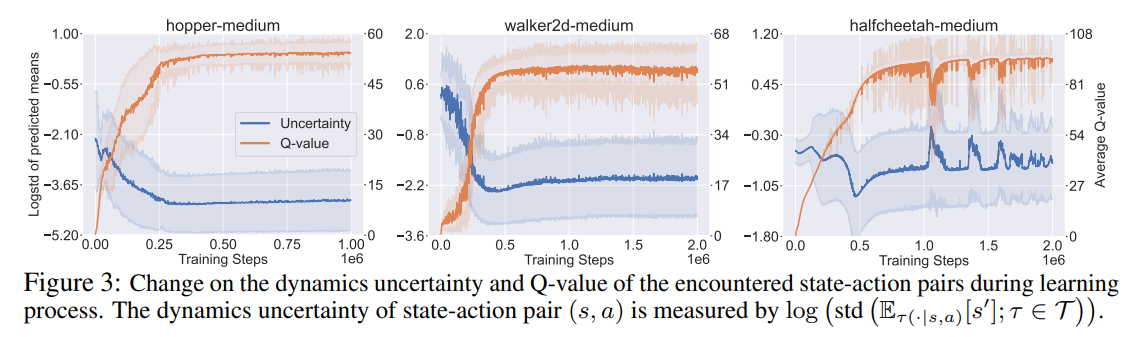
【推荐理由】基于模型的离线强化学习旨在通过利用先前收集的静态数据集和动态模型来找到高回报的策略。一些作品提出量化预测动态的不确定性,并明确将其应用于惩罚奖励。 然而,由于动态和奖励在 MDP 的背景下本质上是不同的因素,因此通过奖励惩罚来表征动态不确定性的影响可能会在模型利用和风险规避之间产生意想不到的权衡。 本文中作者改为维持动态的信念分布,并通过信念的偏差抽样来评估/优化策略。偏于悲观的采样过程是基于离线 RL 的交替马尔可夫博弈公式推导出来的。 有偏差的抽样自然会导致更新的动态信念与策略相关的重新加权因子,称为悲观调制动态信念。 本文为游戏设计了一种迭代正则化策略优化算法,保证在一定条件下单调改进。 本文还进一步设计了一种离线 RL 算法来近似地找到解决方案。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢