
【标题】Reinforcement Learning with Automated Auxiliary Loss Search
【作者团队】Tairan He, Yuge Zhang, Kan Ren, Minghuan Liu
【发表日期】2022.10.12
【论文链接】https://arxiv.org/pdf/2210.06041.pdf
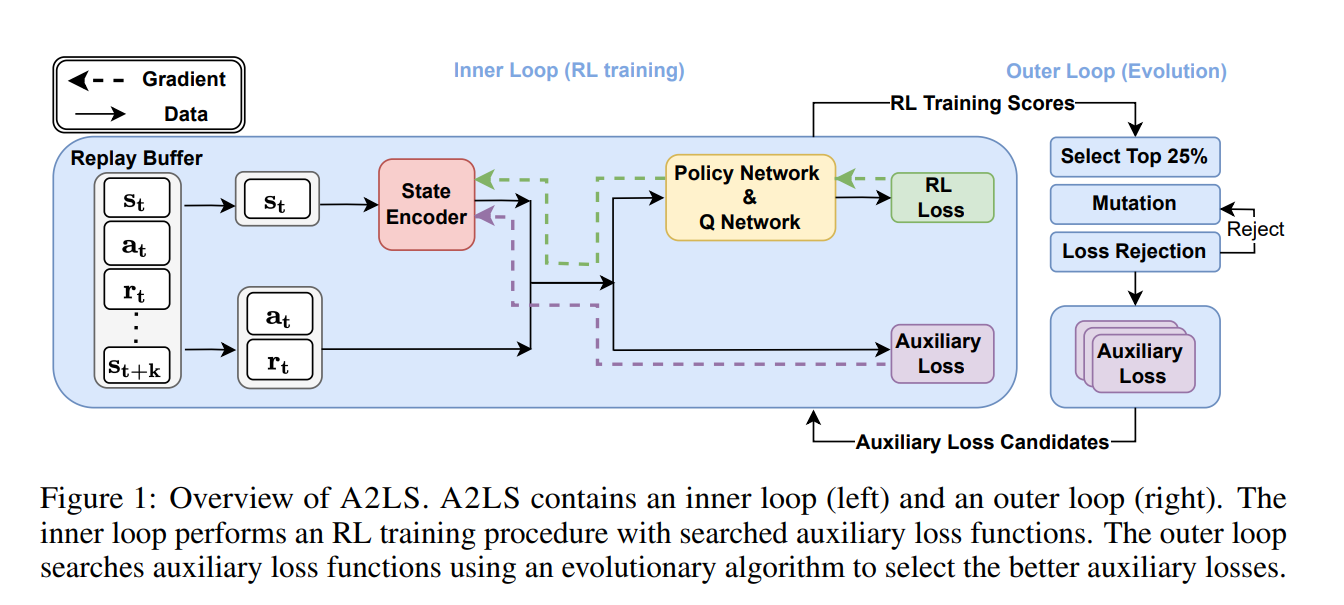
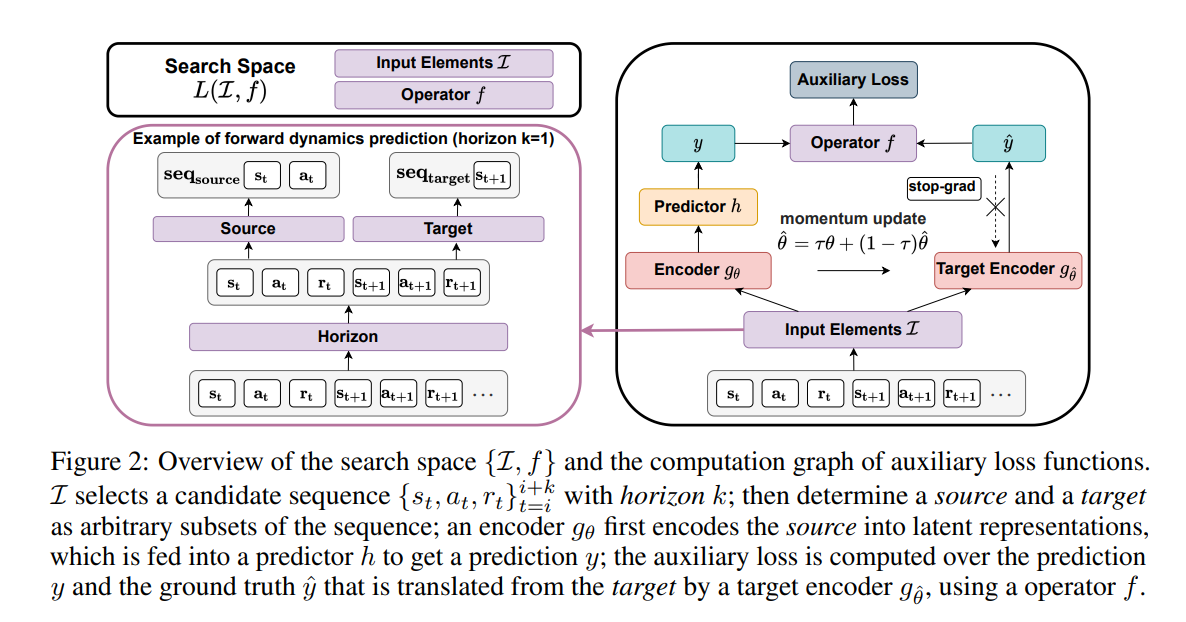
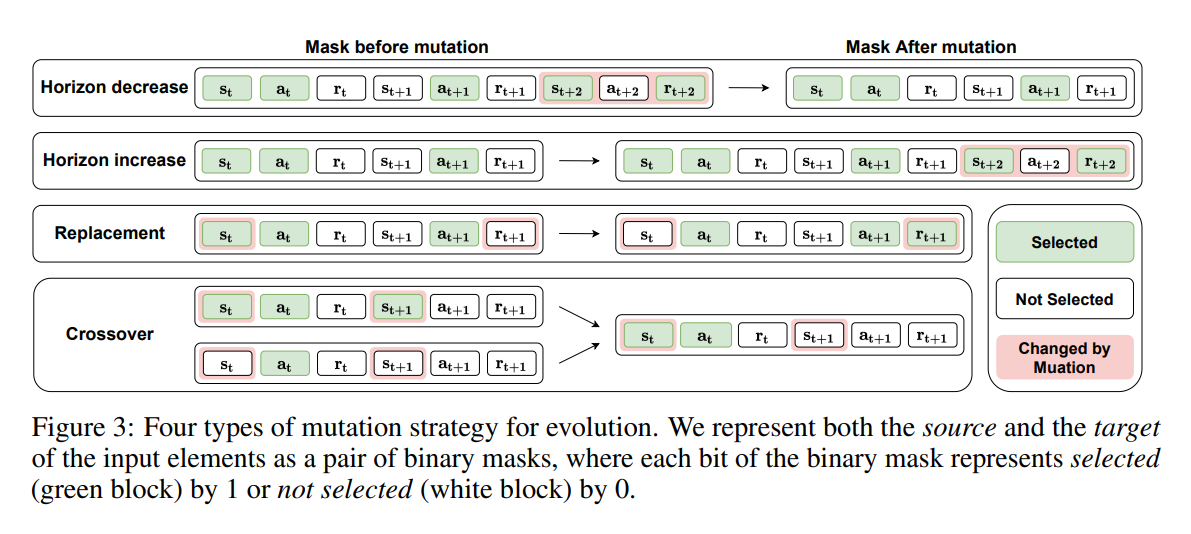
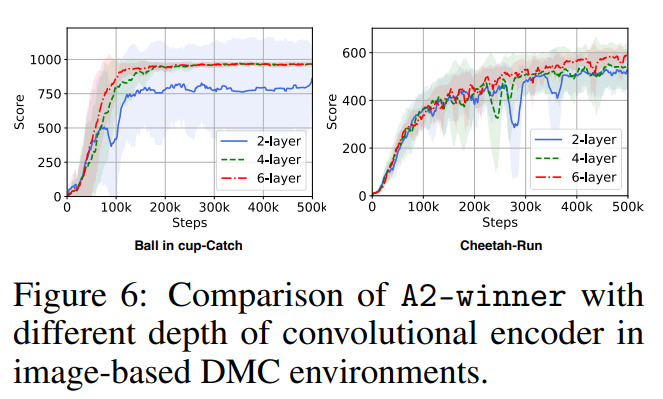
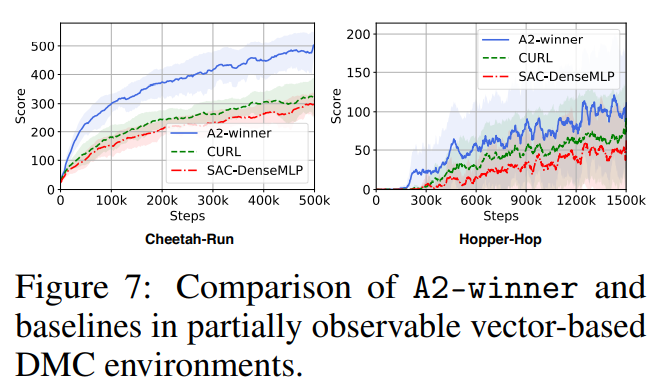
【推荐理由】良好的状态表示对于解决复杂的强化学习 (RL) 挑战至关重要。 最近的许多工作都集中在设计用于学习信息表示的辅助损失。 不幸的是,这些手工制作的目标在很大程度上依赖于专家知识,并且可能不是最理想的。 本文提出了一种学习辅助损失函数更好表示的原则性通用方法,称为自动辅助损失搜索(A2LS),它可以自动搜索 RL 中表现最好的辅助损失函数。 具体来说,基于收集到的轨迹数据,作者定义了一个大小为 7.5×1020 的通用辅助损失空间,并使用有效的进化搜索策略探索该空间。 实验结果表明,发现的辅助损失(即 A2-winner)显着提高了在高维(图像)和低维(向量)未见任务上的性能,效率更高,显示出对不同设置甚至不同基准域的良好泛化能力。本文进行统计分析以揭示辅助损失模式与 RL 性能之间的关系。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢