
【论文标题】Foundation Transformers
【作者团队】Hongyu Wang, Shuming Ma, Shaohan Huang, Li Dong, Wenhui Wang, Zhiliang Peng, Yu Wu, Payal Bajaj, Saksham Singhal, Alon Benhaim, Barun Patra, Zhun Liu, Vishrav Chaudhary, Xia Song, Furu Wei
【发表时间】2022/10/12
【机 构】微软
【论文链接】https://arxiv.org/pdf/2210.06423v1.pdf
跨越语言、视觉、语音和多模态的模型架构的大融合正在出现。然而,在同一名称 "Transformer "下,上述领域使用不同的实现方式以获得更好的性能,例如,BERT使用Post-LayerNorm,而GPT和视觉Transform使用Pre-LayerNorm。本文呼吁为真正的通用模型开发基础Transformer,它可以作为各种任务和模式的首选架构,并保证训练的稳定性,为此引入了一个Transformer变体,名为Magneto,以实现这一目标。具体来说,本文提出了Sub-LayerNorm来实现良好的表达能力,并从理论上提出了DeepNet的初始化策略来实现稳定规模提升。实验证明了它比为各种应用设计的上的Transformer变体更出色的性能和更好的稳定性,包括语言建模(即BERT和GPT)、机器翻译、视觉预训练(即BEiT)、语音识别和多模态预训练(即BEiT-3)。
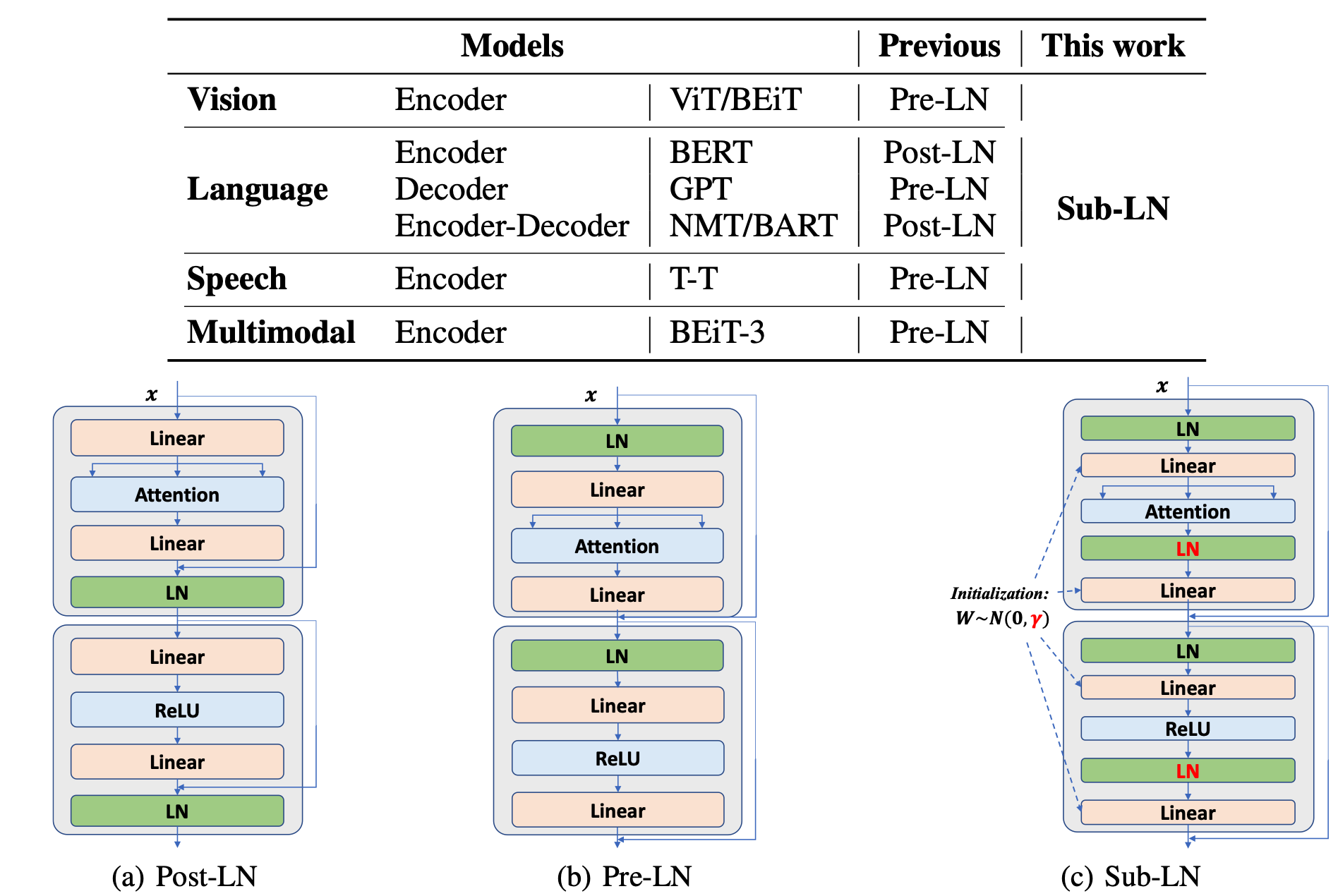
上图展示了语言、视觉、语音和多模态的SOTA模型的架构。
一些模型(如GPT和ViT)采用Pre-LN Transformer,而另一些模型则使用Post-LN Transformer(如BERT和机器翻译)以获得更好的性能。本文不是直接使用相同的架构,而是需要在特定的任务或模式上比较两个Transformer变体,以确定骨干,这对模型的开发是无效的。更重要的是,考虑到多模态模型,最佳Transformer变体通常对输入模态是不同的。以BEiT-3(Wang等人,2022b)的视觉-语言预训练为例,使用Post-LN对视觉编码是次优的,而Pre-LN对语言部分是次优的。多模态预训练的真正融合需要一个统一的架构,在不同的任务和模态中表现良好。此外,Transformer架构的一个痛点是训练的稳定性,特别是对于大规模模型,通常需要付出巨大的工作量来调整超参数或保姆式的训练过程。
而本文引入了Sub-LayerNorm(Sub-LN),它为每个子层(即多头自注意力和前馈网络)增加了一个额外的LayerNorm。此外,MAGNETO(基础Transformer)有一个新颖的初始化方法,从理论上保证从根本上提高训练的稳定性,这使得模型可以轻松地扩大规模。本文在广泛的任务和模式上对MAGNETO进行了评估,即屏蔽语言建模(即BERT)、因果语言建模(即GPT)、机器翻译、屏蔽图像建模(即BEiT)、语音识别和视觉-语言预训练(即BEiT-3)。实验结果表明,MAGNETO在下游任务上的表现明显优于事实上的Transformer变体。此外,MAGNETO在优化方面更加稳定,允许更大的学习率来提高结果,而不会出现训练分歧。
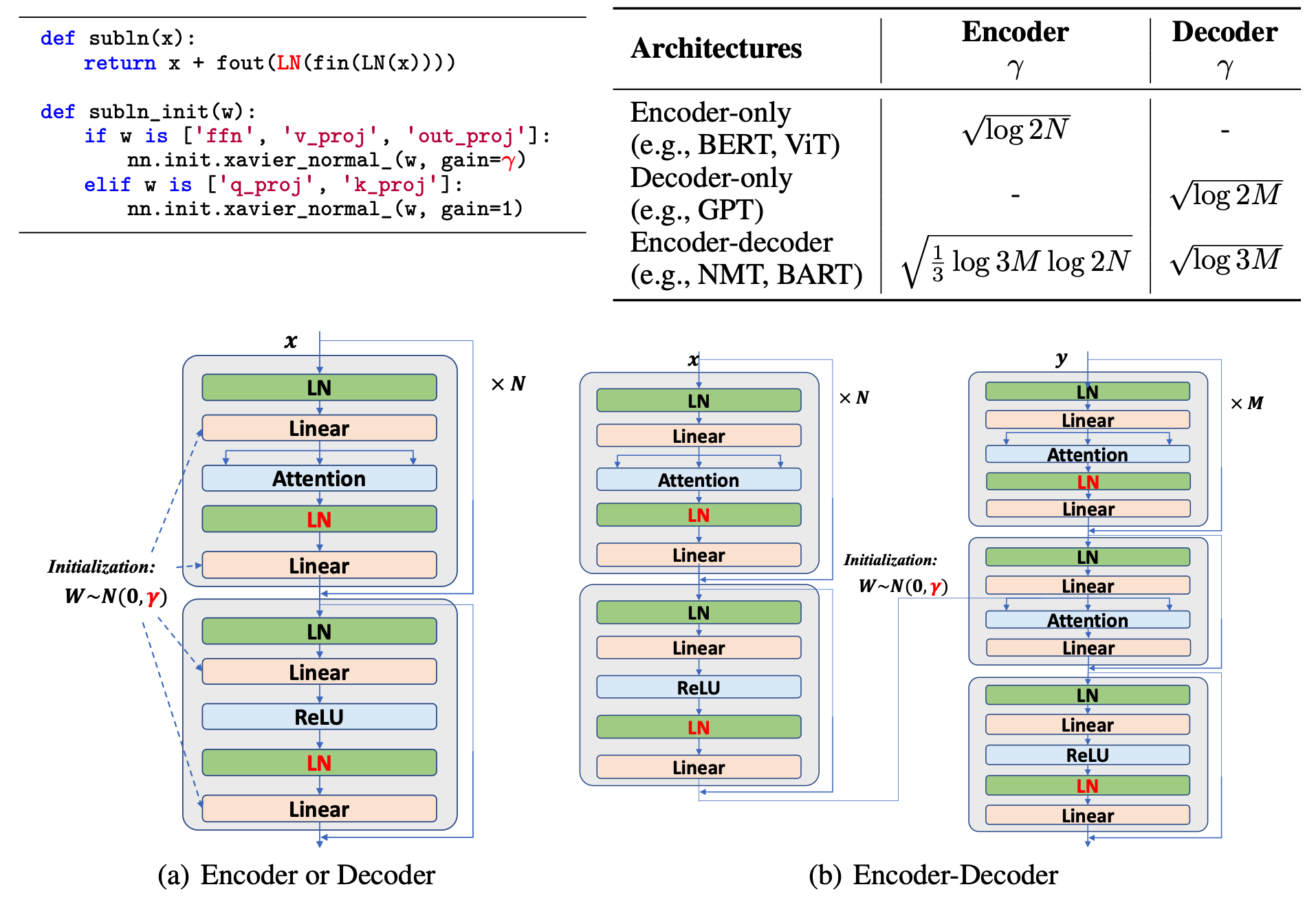
上图介绍了MAGNETO的架构。在原版的Transformer架构之上,只有几行代码的变化。值得注意的是,根据DeepNet的推导,Q投影和K投影的权重在初始化过程中没有被缩放。此外,在编码器-解码器架构的交叉注意力中只有一个LayerNorm。
具体来说,对于单个编码器或者解码器:
1.对每个层应用标准的初始化(如Xavier初始化,其他的初始化方法也可以)。
2.对于每一层,将前馈网络的权重以及注意层的值投影和输出投影按根号对数2N(或根号对数2M)进行调整。
对于编码器和解码器:
1.对每个编码器和解码器层应用标准初始化(如Xavier初始化)。
2. 对于编码器层,前馈网络的权重以及注意层的值投影和输出投影的比例为根号 log 3M log 2N 。
3. 对于解码层,将前馈网络的权重以及注意层的值投影按根号log3M对数2N的比例放大。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢