
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:数据增强相当于增加了多少数据、基于大步长SGD的稀疏特征学习、揭开彩票假说的面纱、面向图像和视频的全景分割的通用框架、符号语言的语言模型绑定、通过大规模检索生成图像、图上的深度多速率学习梯度门控、语言引导的认知规划与视频预测、科学机器学习的广泛基准
1、[LG] How Much Data Are Augmentations Worth? An Investigation into Scaling Laws, Invariance, and Implicit Regularization
J Geiping, M Goldblum, G Somepalli, R Shwartz-Ziv...
[University of Maryland & New York University]
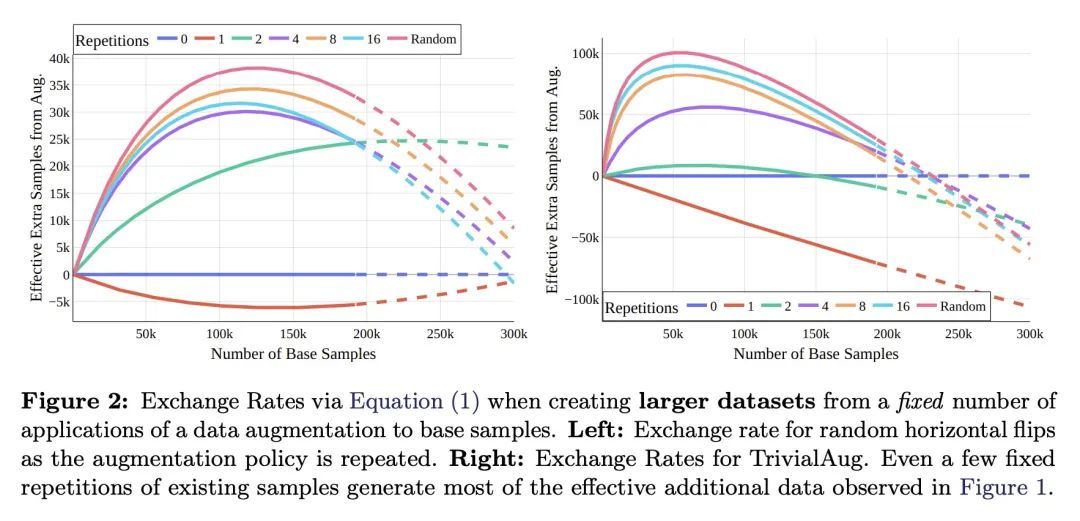
数据增强相当于增加了多少数据?对缩放率、不变性和隐式正则化的研究。尽管数据增强有明显的性能优势,但人们对它们为何如此有效知之甚少。本文分解了数据增强运作的几个关键机制。通过在增强的数据和额外的真实数据之间建立一个交换率,发现在分布外测试场景中,产生多样化但与数据分布不一致的样本的增强,甚至比额外的训练数据更有价值。本文还发现,鼓励不变性的数据增强比单纯的不变性更有价值,特别是在中小型训练集上。根据这一观察,增强在训练过程中诱发了额外的随机性,有效地平坦了损失景观。
Despite the clear performance benefits of data augmentations, little is known about why they are so effective. In this paper, we disentangle several key mechanisms through which data augmentations operate. Establishing an exchange rate between augmented and additional real data, we find that in out-of-distribution testing scenarios, augmentations which yield samples that are diverse, but inconsistent with the data distribution can be even more valuable than additional training data. Moreover, we find that data augmentations which encourage invariances can be more valuable than invariance alone, especially on small and medium sized training sets. Following this observation, we show that augmentations induce additional stochasticity during training, effectively flattening the loss landscape.
https://arxiv.org/abs/2210.06441



2、[LG] SGD with large step sizes learns sparse features
M Andriushchenko, A Varre, L Pillaud-Vivien, N Flammarion
[EPFL]
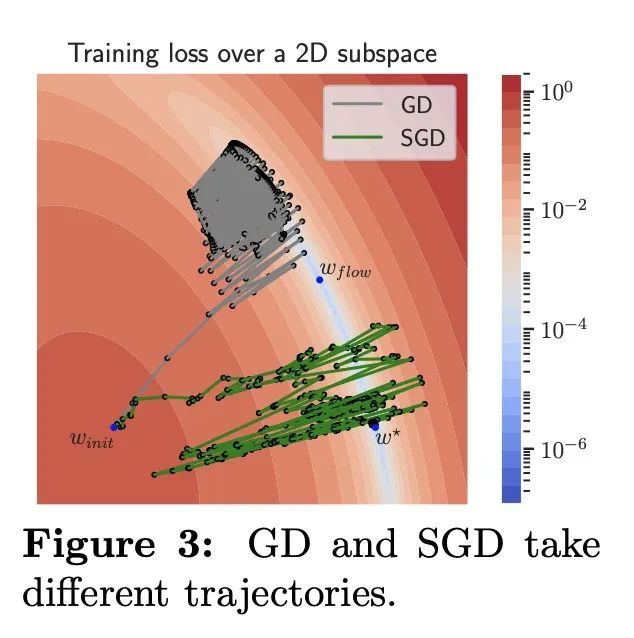
基于大步长SGD的稀疏特征学习。本文展示了随机梯度下降法(SGD)在神经网络训练中的重要动态性特征。本文提出实证观察,常用的大步长:(i)导致迭代从谷的一边跳到另一边,造成损失稳定,以及 (ii)这种稳定诱发了与反弹方向正交的隐藏随机动态,使其隐性地偏向简单预测。此外,根据经验表明,大的步长使SGD在损失景观谷中保持高位,隐式正则化就能更好地运作并找到稀疏表征。值得注意的是,没有使用显式正则化,因此正则化的效果完全来自于受步长规划影响的SGD训练动态。这些观察揭示了通过步长规划,梯度和噪声是如何通过神经网络的损失景观共同驱动SGD动态的。通过对简单的神经网络模型的研究,以及从随机过程中得到的定性论证,从理论上证明了这些发现。最后,这种分析可以对训练神经网络时的一些常见做法和观察到的现象提供一个新的启示。
We showcase important features of the dynamics of the Stochastic Gradient Descent (SGD) in the training of neural networks. We present empirical observations that commonly used large step sizes (i) lead the iterates to jump from one side of a valley to the other causing loss stabilization, and (ii) this stabilization induces a hidden stochastic dynamics orthogonal to the bouncing directions that biases it implicitly toward simple predictors. Furthermore, we show empirically that the longer large step sizes keep SGD high in the loss landscape valleys, the better the implicit regularization can operate and find sparse representations. Notably, no explicit regularization is used so that the regularization effect comes solely from the SGD training dynamics influenced by the step size schedule. Therefore, these observations unveil how, through the step size schedules, both gradient and noise drive together the SGD dynamics through the loss landscape of neural networks. We justify these findings theoretically through the study of simple neural network models as well as qualitative arguments inspired from stochastic processes. Finally, this analysis allows to shed a new light on some common practice and observed phenomena when training neural networks. The code of our experiments is available at this https URL.
https://arxiv.org/abs/2210.05337



3、[LG] Unmasking the Lottery Ticket Hypothesis: What's Encoded in a Winning Ticket's Mask?
M Paul, F Chen, B W. Larsen, J Frankle, S Ganguli, G K Dziugaite
[Stanford & MosaicML & Google Research]
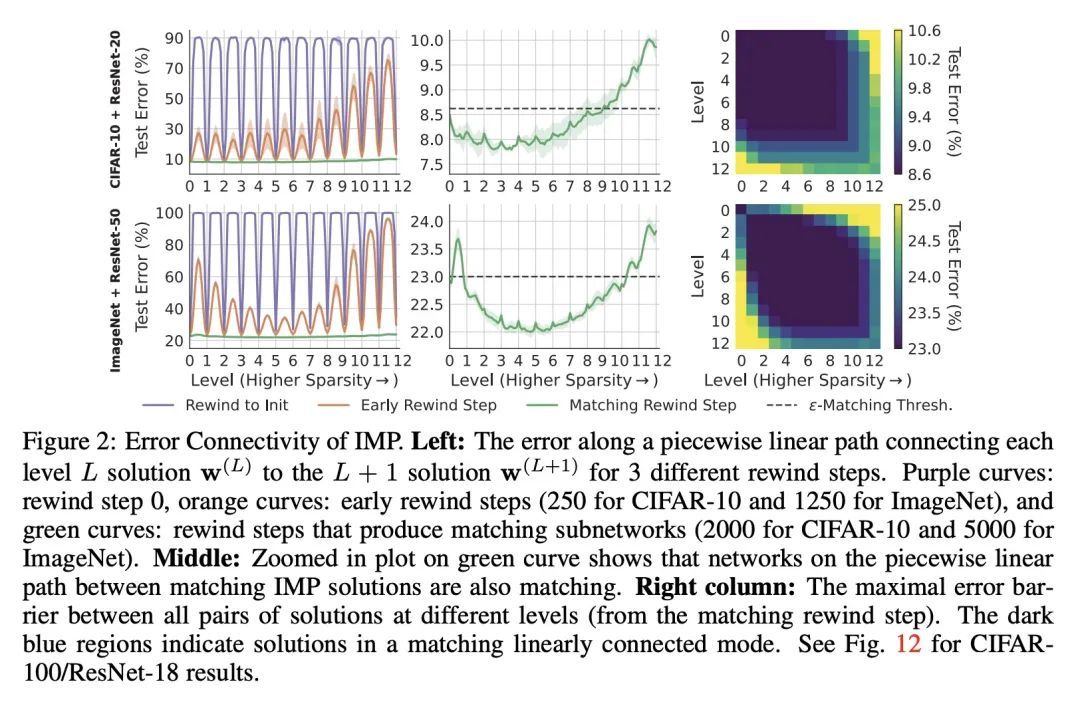
揭开彩票假说的面纱:中奖彩票的掩码编码了什么?现代深度学习涉及到训练昂贵的、高度过参数化的网络,因此促使人们去寻找更稀疏的网络,这些网络仍然可以被训练到与完整网络相同的精度(即匹配)。迭代幅度修剪(IMP)是一种最先进的算法,可以找到这种高度稀疏的匹配子网络,即所谓的中奖彩票。迭代幅度修剪的操作方式是:反复循环训练,掩码最小的幅度权重,倒退到早期训练点,然后重复。尽管IMP很简单,但它何时以及如何找到中奖彩票的基本原则仍然难以理解。特别是,在训练结束时发现的IMP掩码会向接近训练开始的回溯网络传达什么有用的信息?SGD是如何让网络提取这些信息的?为什么需要迭代修剪?本文从误差景观的几何学角度提出了答案。首先,在较高的稀疏度下,在连续的修剪迭代中,一对修剪过的网络被一条具有零误差障碍的线性路径所连接,当且仅当它们是匹配的。这表明在训练结束时发现的掩码传达了对一个轴向子空间的识别,该空间与一个匹配的子水平集的理想线性连接模式相交。第二,SGD可以利用这一信息,因为它具有很强的鲁棒性:尽管在训练早期有强烈的扰动,但它可以回到这一模式。第三,本文展示了在训练结束时误差景观的平坦性如何决定了在IMP的每次迭代中可以修剪的权重部分的限制。在IMP中重新训练的作用是找到一个具有新的小权重的网络来修剪。总的来说,这些结果通过揭示误差景观几何的基本作用,在揭开中奖彩票的神秘面纱方面取得了进展。
Modern deep learning involves training costly, highly overparameterized networks, thus motivating the search for sparser networks that can still be trained to the same accuracy as the full network (i.e. matching). Iterative magnitude pruning (IMP) is a state of the art algorithm that can find such highly sparse matching subnetworks, known as winning tickets. IMP operates by iterative cycles of training, masking smallest magnitude weights, rewinding back to an early training point, and repeating. Despite its simplicity, the underlying principles for when and how IMP finds winning tickets remain elusive. In particular, what useful information does an IMP mask found at the end of training convey to a rewound network near the beginning of training? How does SGD allow the network to extract this information? And why is iterative pruning needed? We develop answers in terms of the geometry of the error landscape. First, we find that—at higher sparsities—pairs of pruned networks at successive pruning iterations are connected by a linear path with zero error barrier if and only if they are matching. This indicates that masks found at the end of training convey the identity of an axial subspace that intersects a desired linearly connected mode of a matching sublevel set. Second, we show SGD can exploit this information due to a strong form of robustness: it can return to this mode despite strong perturbations early in training. Third, we show how the flatness of the error landscape at the end of training determines a limit on the fraction of weights that can be pruned at each iteration of IMP. Finally, we show that the role of retraining in IMP is to find a network with new small weights to prune. Overall, these results make progress toward demystifying the existence of winning tickets by revealing the fundamental role of error landscape geometry.
https://arxiv.org/abs/2210.03044



4、[CV] A Generalist Framework for Panoptic Segmentation of Images and Videos
T Chen, L Li, S Saxena, G Hinton, D J. Fleet
[Google Research] (2022)
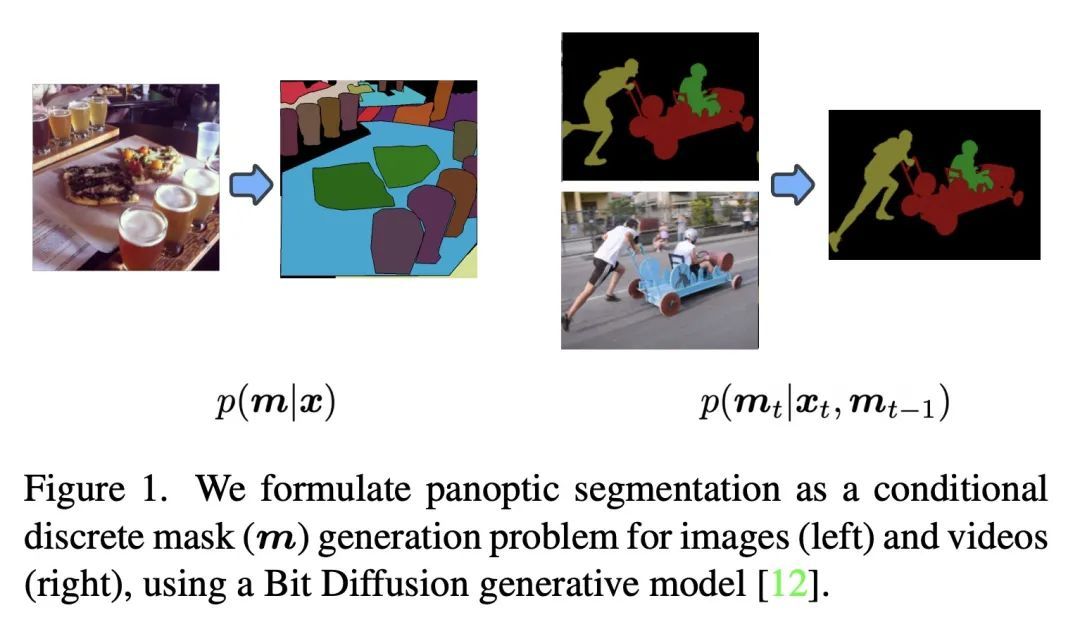
面向图像和视频的全景分割的通用框架。全景分割为图像的每像素分配语义和实例ID标签。由于实例ID的排列组合也是有效的解决方案,该任务需要学习高维的一对多映射。最先进的方法采用定制的架构和特定任务的损失函数。本文将全景分割表述为一个离散数据生成问题,不依赖于任务的归纳偏差。一个基于模拟比特的扩散模型被用来为全景掩码建模,具有简单、通用的架构和损失函数。通过简单地添加过去的预测作为调节信号,所提出方法能对视频进行建模(在流媒体环境下),从而学会自动跟踪目标实例。通过广泛的实验,本文证明了所提出的通用方法可以在类似的环境下与最先进的定制方法竞争。
Panoptic segmentation assigns semantic and instance ID labels to every pixel of an image. As permutations of instance IDs are also valid solutions, the task requires learning of high-dimensional one-to-many mapping. As a result, state-of-the-art approaches use customized architectures and task-specific loss functions. We formulate panoptic segmentation as a discrete data generation problem, without relying on inductive bias of the task. A diffusion model based on analog bits is used to model panoptic masks, with a simple, generic architecture and loss function. By simply adding past predictions as a conditioning signal, our method is capable of modeling video (in a streaming setting) and thereby learns to track object instances automatically. With extensive experiments, we demonstrate that our generalist approach can perform competitively to state-of-the-art specialist methods in similar settings.
https://arxiv.org/abs/2210.06366



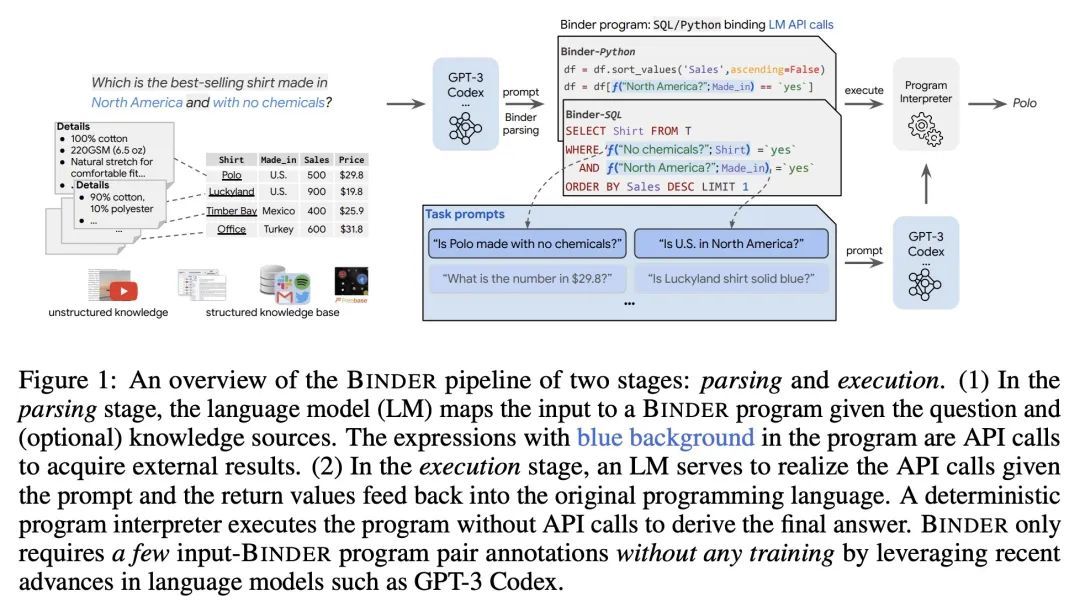
5、[CL] Binding Language Models in Symbolic Languages
Z Cheng, T Xie, P Shi, C Li...
[The University of Hong Kong & University of Waterloo & University of Washington & Yale University]
符号语言的语言模型绑定。尽管端到端神经方法最近在性能和易用性方面都主导了NLP任务,但它们缺乏可解释性和鲁棒性。本文提出了Binder,一种免训练的神经符号框架,将任务输入映射到程序中,(1)允许将统一的语言模型(LM)功能的API绑定到编程语言(如SQL、Python)中,以扩展其语法覆盖范围,从而解决更多多样化的问题,(2)采用语言模型作为程序解析器和执行过程中API调用的底层模型,(3)只需要一些上下文示范性标注。具体来说,采用GPT-3 Codex作为语言模型。在解析阶段,只需几个上下文中的示例,Codex就能识别出任务输入中无法由原始编程语言回答的部分,正确地生成API调用以促使Codex解决无法回答的部分,并在与原始语法兼容的同时确定API调用的位置。在执行阶段,鉴于API调用中的适当提示,Codex可以执行各种功能(例如常识性QA、信息提取)。Binder在WikiTableQuestions和TabFact数据集上取得了最先进的结果,其明确的输出程序有利于人类调试。之前最好的系统都是在数以万计的特定任务样本上进行微调的,而Binder只使用了几十个标注作为上下文中的典范,没有进行任何训练。
Though end-to-end neural approaches have recently been dominating NLP tasks in both performance and ease-of-use, they lack interpretability and robustness. We propose Binder, a training-free neural-symbolic framework that maps the task input to a program, which (1) allows binding a unified API of language model (LM) functionalities to a programming language (e.g., SQL, Python) to extend its grammar coverage and thus tackle more diverse questions, (2) adopts an LM as both the program parser and the underlying model called by the API during execution, and (3) requires only a few in-context exemplar annotations. Specifically, we employ GPT-3 Codex as the LM. In the parsing stage, with only a few in-context exemplars, Codex is able to identify the part of the task input that cannot be answerable by the original programming language, correctly generate API calls to prompt Codex to solve the unanswerable part, and identify where to place the API calls while being compatible with the original grammar. In the execution stage, Codex can perform versatile functionalities (e.g., commonsense QA, information extraction) given proper prompts in the API calls. Binder achieves state-of-the-art results on WikiTableQuestions and TabFact datasets, with explicit output programs that benefit human debugging. Note that previous best systems are all finetuned on tens of thousands of task-specific samples, while Binder only uses dozens of annotations as in-context exemplars without any training. Our code is available at this https URL .
https://arxiv.org/abs/2210.02875


6、[CV] KNN-Diffusion: Image Generation via Large-Scale Retrieval
S Sheynin, O Ashual, A Polyak, U Singer, O Gafni, E Nachmani, Y Taigman
[Meta AI]
KNN-Diffusion: 通过大规模检索生成图像。最近的文本-图像模型已经取得了令人印象深刻的结果。然而,由于它们需要大规模的文本-图像对数据集,在数据稀缺或缺少标注的新领域训练它们是不切实际的。本文提出用大规模检索方法,特别是高效的k-Nearest-Neighbors(kNN),它提供了新的能力: (1)在没有任何文字的情况下训练一个相当小而高效的文本-图像扩散模型,(2) 通过在推理时简单交换检索数据库来生成分布外图像,以及(3)在保留对象身份的同时进行文字驱动的局部语义操作。为了证明所提方法的鲁棒性,将所提出的kNN方法应用于两个最先进的扩散骨架,并在几个不同的数据集上展示了结果。正如人们研究和自动指标所评估的那样,与现有的仅用图像(没有配对文本数据)训练文本到图像生成模型的方法相比,所提出方法取得了最先进的结果。
Recent text-to-image models have achieved impressive results. However, since they require large-scale datasets of text-image pairs, it is impractical to train them on new domains where data is scarce or not labeled. In this work, we propose using large-scale retrieval methods, in particular, efficient k-Nearest-Neighbors (kNN), which offers novel capabilities: (1) training a substantially small and efficient text-to-image diffusion model without any text, (2) generating out-of-distribution images by simply swapping the retrieval database at inference time, and (3) performing text-driven local semantic manipulations while preserving object identity. To demonstrate the robustness of our method, we apply our kNN approach on two state-of-the-art diffusion backbones, and show results on several different datasets. As evaluated by human studies and automatic metrics, our method achieves state-of-the-art results compared to existing approaches that train text-to-image generation models using images only (without paired text data)
https://arxiv.org/abs/2204.02849




7、[LG] Gradient Gating for Deep Multi-Rate Learning on Graphs
T. K Rusch, B P. Chamberlain, M W. Mahoney, M M. Bronstein, S Mishra
[ETH Zurich & Twitter Inc. & UC Berkeley]
图上的深度多速率学习梯度门控。本文提出梯度门控(G2),一种用于提高图神经网络(GNN)性能的新框架。该框架基于对GNN层的输出进行门控,其机制是在底层图的节点间进行信息传递的多速率流动。局部梯度被利用来进一步调节信息传递的更新。所提出框架灵活地允许用任意基本GNN层作为包装,围绕其建立多速率梯度门控机制。本文严格证明了G2缓解了过度平滑问题,并允许设计深度GNN。实证结果表明,所提出的框架在各种图学习任务上取得了最先进的性能,包括在大规模异质图上。
We present Gradient Gating (G2), a novel framework for improving the performance of Graph Neural Networks (GNNs). Our framework is based on gating the output of GNN layers with a mechanism for multi-rate flow of message passing information across nodes of the underlying graph. Local gradients are harnessed to further modulate message passing updates. Our framework flexibly allows one to use any basic GNN layer as a wrapper around which the multi-rate gradient gating mechanism is built. We rigorously prove that G2 alleviates the oversmoothing problem and allows the design of deep GNNs. Empirical results are presented to demonstrate that the proposed framework achieves state-of-the-art performance on a variety of graph learning tasks, including on large-scale heterophilic graphs.
https://arxiv.org/abs/2210.00513




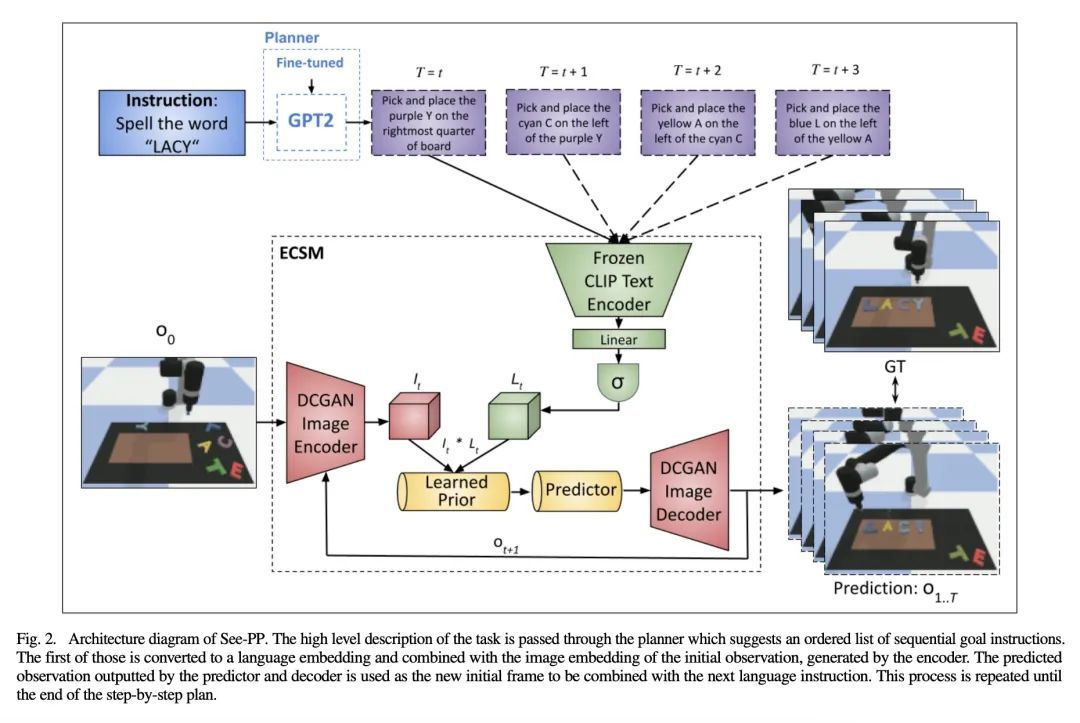
8、[RO] See, Plan, Predict: Language-guided Cognitive Planning with Video Prediction
M Attarian, A Gupta, Z Zhou, W Yu, I Gilitschenski, A Garg
[University of Toronto]
看、规划、预测:语言引导的认知规划与视频预测。认知规划是将复杂的任务结构性地分解为一连串的未来行为。在计算环境中,执行认知规划需要将规划和概念建立在一种或多种模态之上,以便利用它们进行低级控制。由于现实世界的任务经常用自然语言描述,本文通过语言引导的视频预测设计了一种认知规划算法。目前的视频预测模型并不支持对自然语言指令的调节。本文提出一种新的视频预测架构,利用预训练好的Transformer的力量。该网络被赋予了基于自然语言输入的概念的能力,并能泛化到未见过的物体。在一个新的模拟数据集上证明了该方法的有效性,其中每个任务都是由自然语言描述的高级动作定义的。通过实验将所提出方法与没有规划和行动基础的视频生成基线进行了比较,并展示了明显的改进。消融研究强调了自然语言嵌入为概念基础能力提供的对未见物体的改进的泛化性,以及规划对任务的视觉"想象"的重要性。
Cognitive planning is the structural decomposition of complex tasks into a sequence of future behaviors. In the computational setting, performing cognitive planning entails grounding plans and concepts in one or more modalities in order to leverage them for low level control. Since real-world tasks are often described in natural language, we devise a cognitive planning algorithm via language-guided video prediction. Current video prediction models do not support conditioning on natural language instructions. Therefore, we propose a new video prediction architecture which leverages the power of pre-trained transformers.The network is endowed with the ability to ground concepts based on natural language input with generalization to unseen objects. We demonstrate the effectiveness of this approach on a new simulation dataset, where each task is defined by a high-level action described in natural language. Our experiments compare our method against one video generation baseline without planning or action grounding and showcase significant improvements. Our ablation studies highlight an improved generalization to unseen objects that natural language embeddings offer to concept grounding ability, as well as the importance of planning towards visual "imagination" of a task.
https://arxiv.org/abs/2210.03825



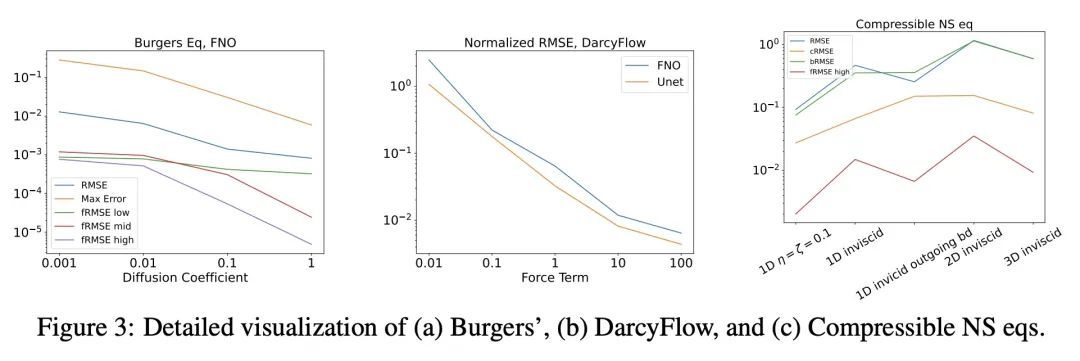
9、[LG] PDEBENCH: An Extensive Benchmark for Scientific Machine Learning
M Takamoto, T Praditia, R Leiteritz, D MacKinlay, F Alesiani, D Pflüger, M Niepert
[NEC Labs Europe & University of Stuttgart & CSIRO’s Data61]
PDEBENCH:科学机器学习的广泛基准。近年来,基于机器学习的物理系统建模受到了越来越多的关注。尽管取得了一些令人印象深刻的进展,但仍然缺乏易于使用但仍然具有挑战性和代表广泛问题的科学机器学习的基准。本文提出PDEBench,一个基于偏微分方程(PDE)的时间依赖性仿真任务的基准套件。PDEBench由代码和数据组成,以经典数值模拟和机器学习基线为基准来衡量机器学习模型性能。所提出的基准问题集有以下独特特点:(1) 与现有基准相比,PDE的范围更广,从相对常见的例子到更现实和困难的问题;(2) 与之前的工作相比,有更大的现成数据集,包括在更多的初始和边界条件以及PDE参数下的多次模拟运行;(3) 具有用户友好的API的更可扩展的源代码,用于数据生成和流行机器学习模型(FNO, U-Net, PINN, 基于梯度的反演方法)的基线结果。PDEBench允许研究人员用标准化API为自己的目的自由扩展基准,并将新模型的性能与现有基线方法进行比较。本文还提出了新的评估指标,目的是在科学机器学习的背景下对学习方法有一个更全面的了解。通过这些指标,确定了对最近的机器学习方法具有挑战性的任务,并提出这些任务作为社区未来的挑战。
Machine learning-based modeling of physical systems has experienced increased interest in recent years. Despite some impressive progress, there is still a lack of benchmarks for Scientific ML that are easy to use but still challenging and representative of a wide range of problems. We introduce PDEBench, a benchmark suite of time-dependent simulation tasks based on Partial Differential Equations (PDEs). PDEBench comprises both code and data to benchmark the performance of novel machine learning models against both classical numerical simulations and machine learning baselines. Our proposed set of benchmark problems contribute the following unique features: (1) A much wider range of PDEs compared to existing benchmarks, ranging from relatively common examples to more realistic and difficult problems; (2) much larger ready-to-use datasets compared to prior work, comprising multiple simulation runs across a larger number of initial and boundary conditions and PDE parameters; (3) more extensible source codes with user-friendly APIs for data generation and baseline results with popular machine learning models (FNO, U-Net, PINN, Gradient-Based Inverse Method). PDEBench allows researchers to extend the benchmark freely for their own purposes using a standardized API and to compare the performance of new models to existing baseline methods. We also propose new evaluation metrics with the aim to provide a more holistic understanding of learning methods in the context of Scientific ML. With those metrics we identify tasks which are challenging for recent ML methods and propose these tasks as future challenges for the community. The code is available at this https URL.
https://arxiv.org/abs/2210.07182



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢