

本文简要介绍发表于TIP2022录用论文“Mixed-Supervised Scene Text Detection With Expectation-Maximization Algorithm”的主要工作。针对检测模型对强标注数据的依赖问题,该论文首先提出了一系列弱标注形式来大幅度缩减数据标注成本,其次提出了一种基于EM算法的混合监督学习策略来利用这些弱标注数据提升检测器性能。此外,为了便于在混合监督学习框架中合理利用这些弱标注,该论文还提出了一种基于轮廓回归的两阶段任意形状场景文本检测器。在多个公开数据集上的实验结果显示,该论文提出的混合监督模型可以达到接近全监督模型的性能。
一、研究背景
近几年来,一大批基于深度学习的场景文本检测算法涌现出来,这些算法虽然取得了优异的检测效果,但是它们在训练过程中无不依赖于大量的强标注数据(多边形标注),需要耗费巨大的标注成本。为了缩减数据标注成本,一个自然的想法就是使用弱标注。作者从标注者的角度出发提出了一系列的弱标注形式,包括紧致的矩形框、宽松的矩形框、粗糙的矩形框以及图像级别标签。针对利用弱标注数据提升检测器性能的问题,之前的学者一般采用弱监督学习或半监督学习方法,这些方法虽然取得了一定的进步,但其效果与全监督模型还有较大的差距,不适用于真实场景(如自动驾驶领域)。该论文提出使用混合监督学习方法,即只有少量图片采用强标注,其余图片采用弱标注。作者首先提出了一种基于轮廓回归的两阶段文本检测器来更好地利用这些弱标签,其次作者将弱标签图片的多边形标签看作隐变量,使用了一个类似于EM算法的学习策略来解决这个混合监督学习问题。具体地,该算法主要包括两步:(1)E步:估计弱标签图片中文本实例的多边形轮廓;(2)M步:使用E步估计的多边形标签监督模型训练进而更新模型参数。由于整个迭代优化问题是高度非凸的,所以模型的质量很大程度上取决于初始化,因此,作者使用少量的强标注数据进行预训练来初始化模型。在六个场景文本数据集上的实验结果显示仅使用10%强标注图片以及90%弱标注图片,该论文提出的混合监督模型达到了接近全监督模型的性能。
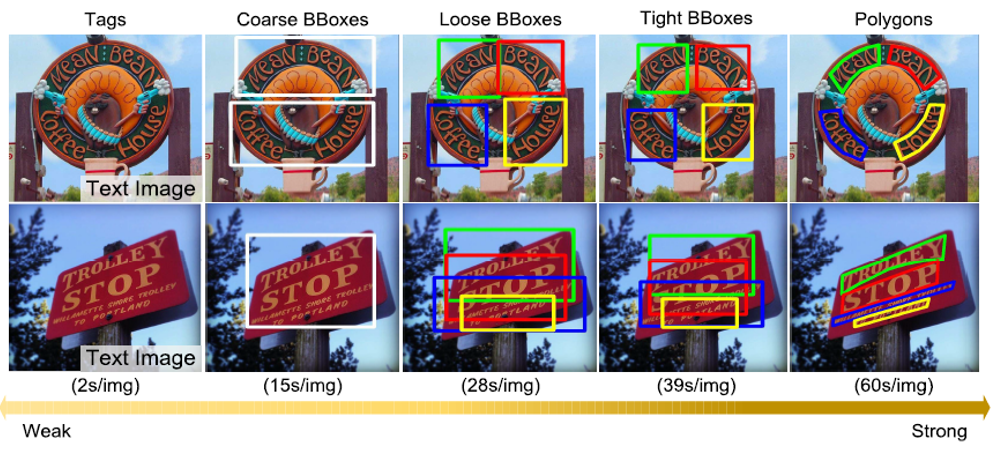
图1 五种监督形式及其平均标注耗时
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢