

论文链接:
https://arxiv.org/abs/2205.06803
代码链接:
https://github.com/TencentARC/VQFR
导读
受启发于经典的字典学习方法与矢量量化(Vector Quantization, VQ)技术,本文提出一种基于矢量量化的人脸复原方法VQFR。在VQVAE与VQGAN基础上,作者引入两个特殊设计:(1) 对VQ码本的压缩块尺寸进行了探索并发现合适的压缩块尺寸设计对于平衡高质量与真实性非常重要;(2) 为进一步融合源自输入的底层特征同时避免对VQ码本生成的真实细造成干扰,作者提出了一种包含纹理解码器与主解码器的并行解码器。受益于VQ码本与并行解码器,所提VQFR可以大幅提升人脸复原细节,同时保持人脸ID属性(即真实性,fidelity)。
贡献
人脸先验信息有助于提升盲人脸复原性能,如几何先验(FSRNet)、生成先验(GPEN, GFPGAN)以及参考先验(DFDNet)。但这些方案在人脸纹理细节重建方面效果仍差强人意,而的矢量量化技术则提供了另一种可能,它无需任何几何或者GAN先验,同时可提供不受人脸成分约束的更全面的底层特征。此外,矢量量化技术的机理使其对多样性退化更具鲁棒性。

为更好的基于VQGAN进行盲人脸复原,作者基于VQGAN进行了重建与复原分析,见上图。可以看到:
- 对于重建任务,我们发现:合适的压缩块尺寸对于重建质量非常重要,且有助于移除LQ输入的退化。何为压缩块尺寸呢?就是码本中每个原子在原始图像中对应的块尺寸,即特征下采样倍率。经过充分探索,我们建议:对于输入 512 \times 512512×512 的输入,其压缩块尺寸设为32。
- 对于复原任务,我们发现:受限于VQGAN的架构,最终重建结果尽管具有高质量,但忠实性不足;在Encoder与Decoder之间构建跳过连接可以提升忠实性,但重建质量会迅速下降。也就是说,底层输入特征具有更多的忠实性信息,但会干扰源自VQ码本重建的逼真细节。这就促使我们提出了一种并行解码器:包含纹理解码器与主解码器。纹理解码器只从VQ码本中接收信息,而主解码器则对纹理解码器的特征进行变换以匹配退化输入信息。
方法
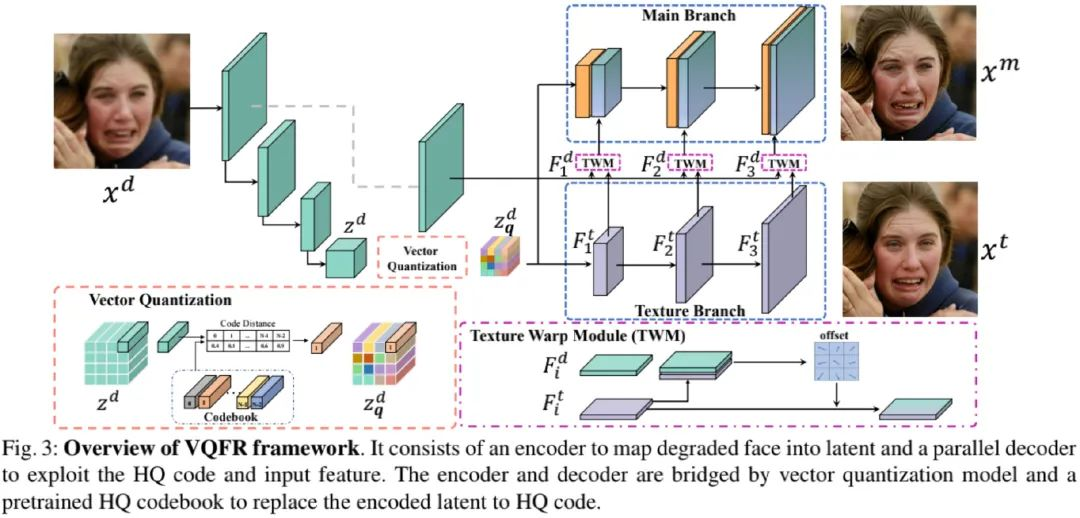
上图给出了VQFR整体架构示意图,可以看到:VQFR由Encoder、并行Decoder与预训练HQ码本构成。首先,仅需HQ人脸图像通过矢量量化技术学习一个VQ码本;然后,退化人脸通过Encoder进行编码,编码特征与VQ码本进行最近邻匹配替换得到量化特征;最后,量化特征经由Decoder处理得到重建人脸图像。
关于VQ技术的介绍这里就略过不计,感兴趣的同学建议查看原文或者VQVAE、VQGAN等文章。在这里,我们重点对并行解码器进行介绍。
Parallel Decoder
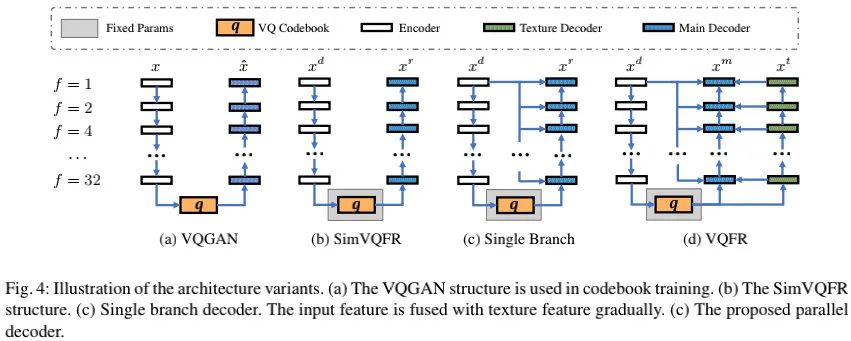
如前所述,SIMVQFR会导致重建人脸的忠实性不足;而简单的以单分支方式融合输入信息会弱化细节。也就是说:这种简单的单分支结果会干扰高质量细节生成。
为确保人脸重建结果的高质量与忠实性,作者提出了一种并行解码器结构,其核心在于:将人脸复原的两个目标(即高质量人脸细节重建与人脸ID属性的忠实性)进行解耦。
如前述Fig3所示,给定退化人脸图像 \( x^d \in R^{H \times W \times 3} \),我们首先对其进行编码得到 \( z^d=E(x^d) \) ;然后采用HQ码本中的原子对其进行量化得到\( z^d_q \) ;最后,我们将其送入纹理解码器得到 \( x^t=G_t(z_q^d) \) 。我们将纹理分支的多级特征表示为\( F^t = \left \{ F^t_i \right \} \),由于纹理分支仅对HQ信息进行编码,具有逼真的人脸细节。
主分支解码器 G_mGm 则旨在具有高忠实性与高重建质量的人脸 xm ,正如上述图示所示,主分支解码器在多个空间维度基于输入特征 \( F^d = \left \{ F^d_i \right \} \)对纹理特征进行变换处理。对于第i个空间维度,我们首先采用纹理仿射模块(Texture Warping Module, TWM)将 \( F^t_I \) 朝 \( F^d_i \) 进行变换得到 \( F^w_i \);然后将所得特征与Fi−1 进行融合到主分支解码器的i级输出特征 Fi 。该过程可描述如下:
\( F_{i}^{w}=T W M\left(F_{i}^{d}, F_{i}^{t}\right) F_{i}=\text{Conv}\left(\text{Concat}\left(U p\left(F_{i-1}\right), F_{i}^{w}\right)\right) \)
该部分的实现对应如下部分,即红框部分。
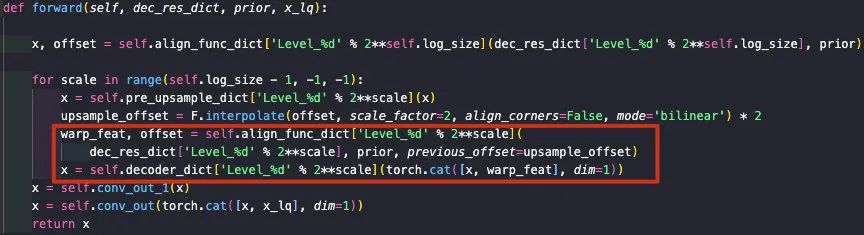
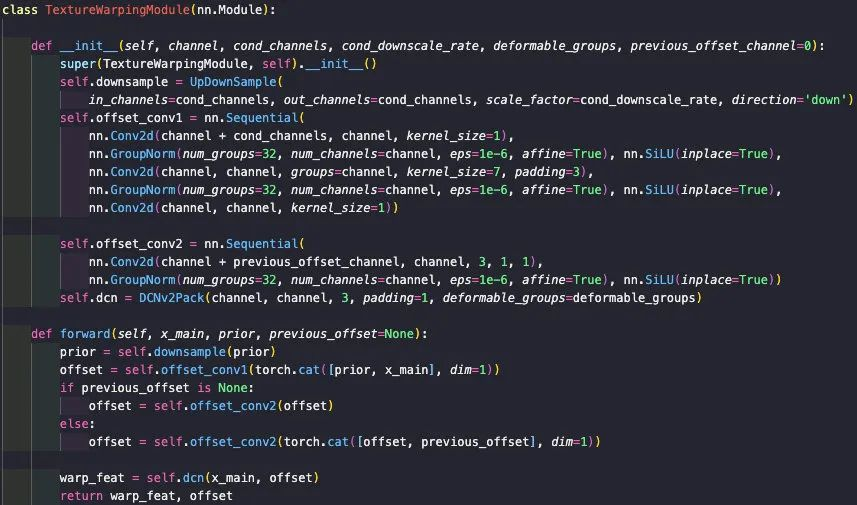
Texture Warping Module
关于TWM的实现,作者采用形变卷积将 Ft 特征朝 Fd 进行变换。具体描述如下:
\( { offset }={Conv}\left({Concat}\left(F_{i}^{d}, F_{i}^{t}\right)\right) F_{i}^{w}=D C N\left(F_{i}^{t}, { offset }\right)offset=Conv(Concat(Fid,Fit)) \)
该模块的实现code参考如下,需要注意的是:这里作者采用了大卷积核以模拟大位置偏差。
Model Objective
VQFR的损失函数包含以下几部分:
- 像素重建损失,这里选用了常见 L1 损失;
- Code对齐损失,它用于迫使LQ对应特征与HQ对应特征相匹配,这里选用了 L2 损失;
- 感知损失,这里选用了常见的基于VGG19的感知损失;
- 对抗损失,这里选用了SWAGAN的全局判别器与PatchGAN的局部判别器。
最终损失函数定义如下:
\( \mathcal{L}_{\text {pix }}=\left\|x^{t}-x^{h}\right\| \mathcal{L}_{\text {code }}=\left\|z^{d}-z_{q}^{h}\right\|_{2}^{2} \mathcal{L}_{\text {per }}=\left\|\phi\left(x^{r}\right)-\phi\left(x^{h}\right)\right\|_{2}^{2} \mathcal{L}_{\text {adv }}^{\text {global }}=-\lambda_{\text {adv }} \)
实验
人工合成数据
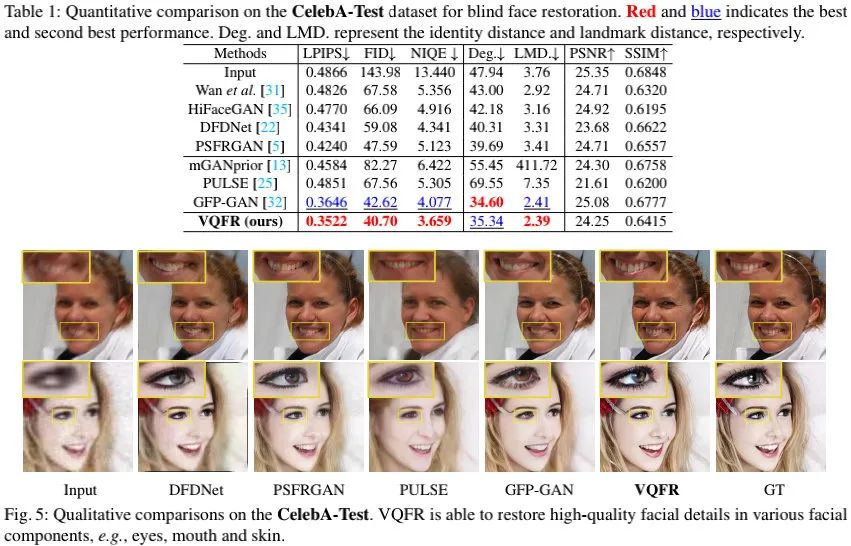
从上述图表可以看到:
- 在客观指标方面,VQFR取得了最佳LPIPS、最佳IFD、最佳NIQE;
- 在人脸属性评价维度,VQFR取得了最佳LMD指标,即其重建结果与GT的关键点距离误差更小。
- 在重建效果方面,VQFR的重建纹理更逼真,同时ID属性忠实性更接近GT。
现实场景数据
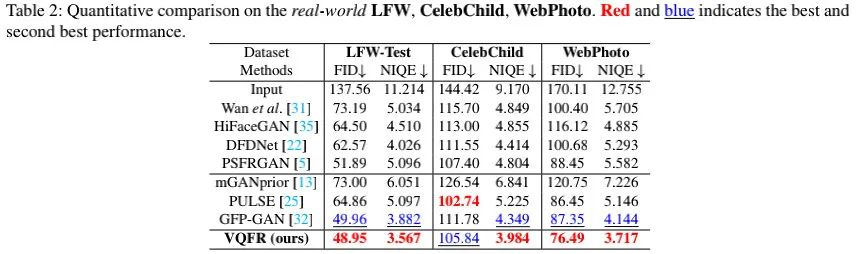

从上述图表可以看到:
- 在三个现实场景数据上,VQFR可以大幅改善图像质量,具有最优的FID与NIQE指标;
- 在重建效果方面,VQFR重建结果纹理更逼真,明显优于其他方案。
Ablation Study



上面提供了采用VQFR处理的效果图,左为输入,中为主分支解码器的输出,右为纹理解码器的输出。其实,从这个效果来看,纹理解码器的效果也是非常不错的。两个结果对比来看,一个冷色调、一个暖色调的差异,整体差异并没有想象中那么大。所以,实际应用场景下可以考虑只用纹理解码器部分的输出。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢