
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:通过可解释的人工智能从深度学习中获得遗传学洞察、基于神经辐射场的视觉引导双足运动技能模拟到现实迁移、基于强化学习的动态四足机器人守门员、英语对多语言模型流畅性的影响评估、大型语言模型是少(单)样本表格推理器、利用训练动态挖掘数据子集、利用广泛离线数据学习视觉运动任务、鲁棒神经后验估计与统计模型批判、基于Transformer的2D&3D分子表示
1、[LG] Obtaining genetics insights from deep learning via explainable artificial intelligence
G Novakovsky, N Dexter, MW Libbrecht…
[ University of British Columbia & Simon Fraser University & University of Washington]
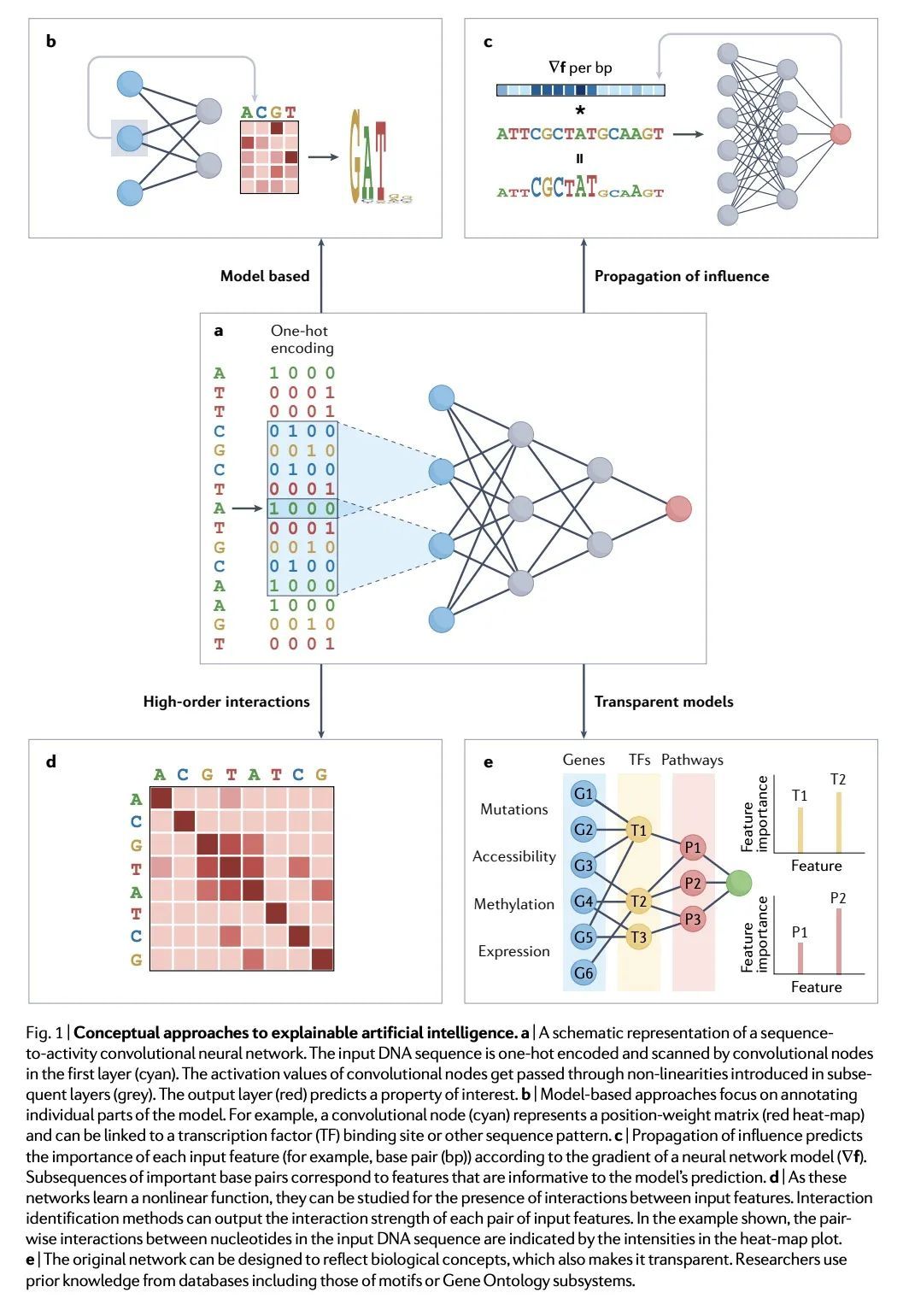
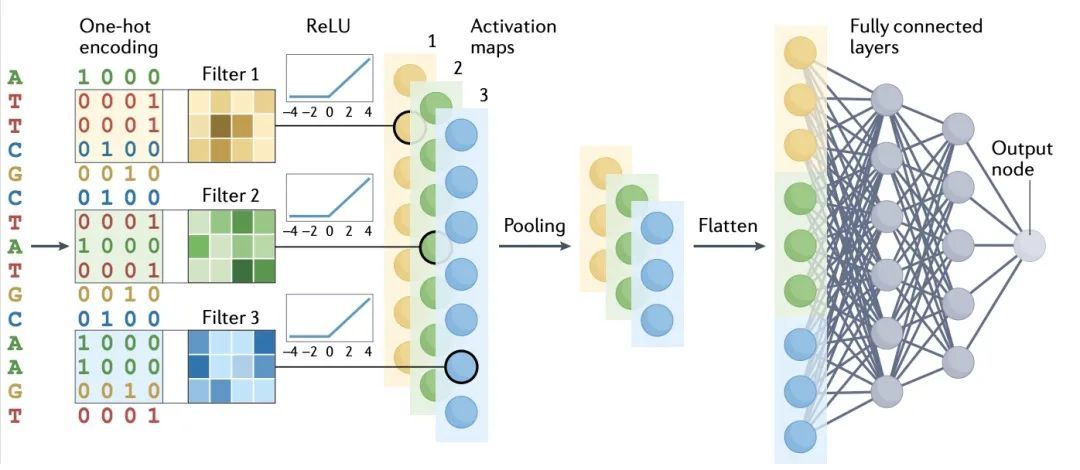
通过可解释的人工智能从深度学习中获得遗传学洞察。基于深度学习的人工智能(AI)模型现在代表了在基因组学研究中进行功能预测的最新技术水平。然而,预测模型做出这种预测的基本依据往往是未知的。对于基因组学研究者来说,这种缺失的解释信息往往比预测本身更有价值,因为它可以使人们对遗传过程有新的认识。本文回顾了可解释人工智能(xAI)这一新兴领域的进展,该领域有可能使生命科学研究人员获得对复杂的深度学习模型的机制性见解。本文对模型解释的方法进行了讨论和分类,包括在典型的高通量生物数据集的背景下,对每种方法如何工作及其基本假设和限制的直观理解。
Artificial intelligence (AI) models based on deep learning now represent the state of the art for making functional predictions in genomics research. However, the underlying basis on which predictive models make such predictions is often unknown. For genomics researchers, this missing explanatory information would frequently be of greater value than the predictions themselves, as it can enable new insights into genetic processes. We review progress in the emerging area of explainable AI (xAI), a field with the potential to empower life science researchers to gain mechanistic insights into complex deep learning models. We discuss and categorize approaches for model interpretation, including an intuitive understanding of how each approach works and their underlying assumptions and limitations in the context of typical high-throughput biological datasets.
https://nature.com/articles/s41576-022-00532-2

2、[RO] NeRF2Real: Sim2real Transfer of Vision-guided Bipedal Motion Skills using Neural Radiance Fields
A Byravan, J Humplik, L Hasenclever, A Brussee...
[DeepMind]
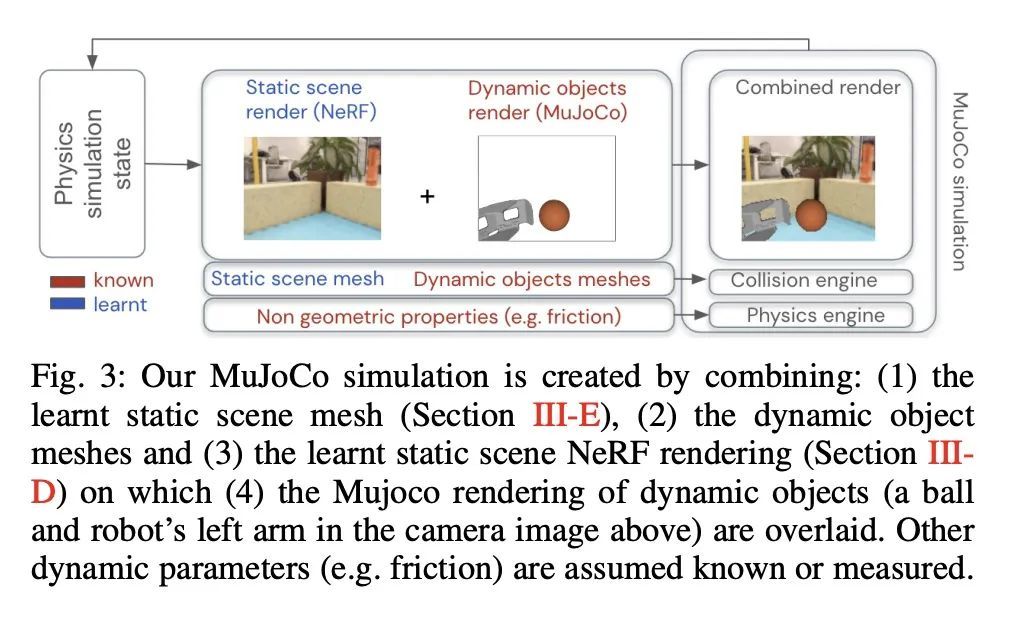
NeRF2Real:基于神经辐射场的视觉引导双足运动技能模拟到现实迁移。本文提出一个系统,用于将模拟到现实的方法应用于具有真实视觉效果的"真实"场景,以及依赖于用RGB摄像机的主动感知的策略。给定一个用普通手机收集的静态场景的短视频,学习场景的接触几何和使用神经辐射场(NeRF)进行新的视图合成的函数。通过叠加其他动态物体(如机器人自己的身体、一个球)的渲染来增强静态场景的NeRF渲染。用物理模拟器中的渲染引擎创建一个模拟,从静态场景的几何形状(从NeRF体密度估计)和动态物体的几何形状和物理属性(假设已知)计算接触动力学。可以用这种模拟来学习基于视觉的全身导航和推球策略,适用于带有致动头戴式RGB摄像头的20自由度仿人机器人,并且成功地将这些策略迁移到真正的机器人。
We present a system for applying sim2real approaches to "in the wild" scenes with realistic visuals, and to policies which rely on active perception using RGB cameras. Given a short video of a static scene collected using a generic phone, we learn the scene's contact geometry and a function for novel view synthesis using a Neural Radiance Field (NeRF). We augment the NeRF rendering of the static scene by overlaying the rendering of other dynamic objects (e.g. the robot's own body, a ball). A simulation is then created using the rendering engine in a physics simulator which computes contact dynamics from the static scene geometry (estimated from the NeRF volume density) and the dynamic objects' geometry and physical properties (assumed known). We demonstrate that we can use this simulation to learn vision-based whole body navigation and ball pushing policies for a 20 degrees of freedom humanoid robot with an actuated head-mounted RGB camera, and we successfully transfer these policies to a real robot. Project video is available at this https URL
https://arxiv.org/abs/2210.04932



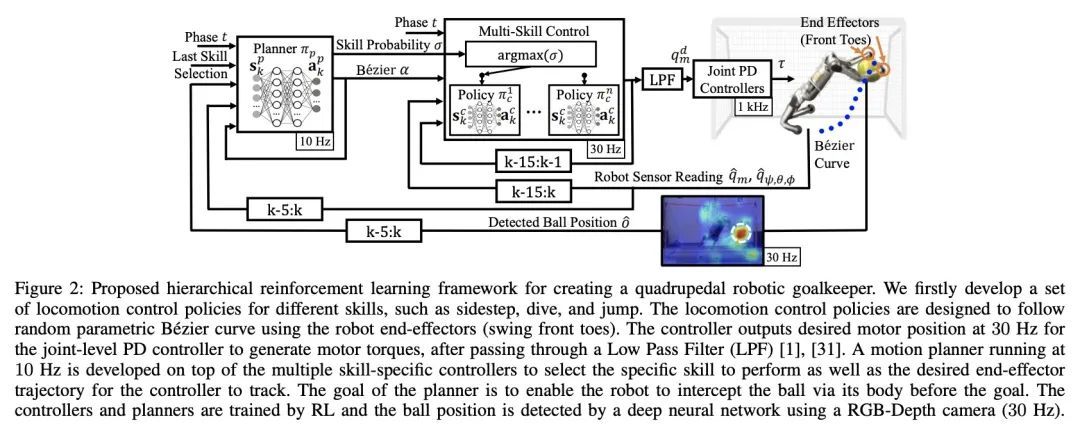
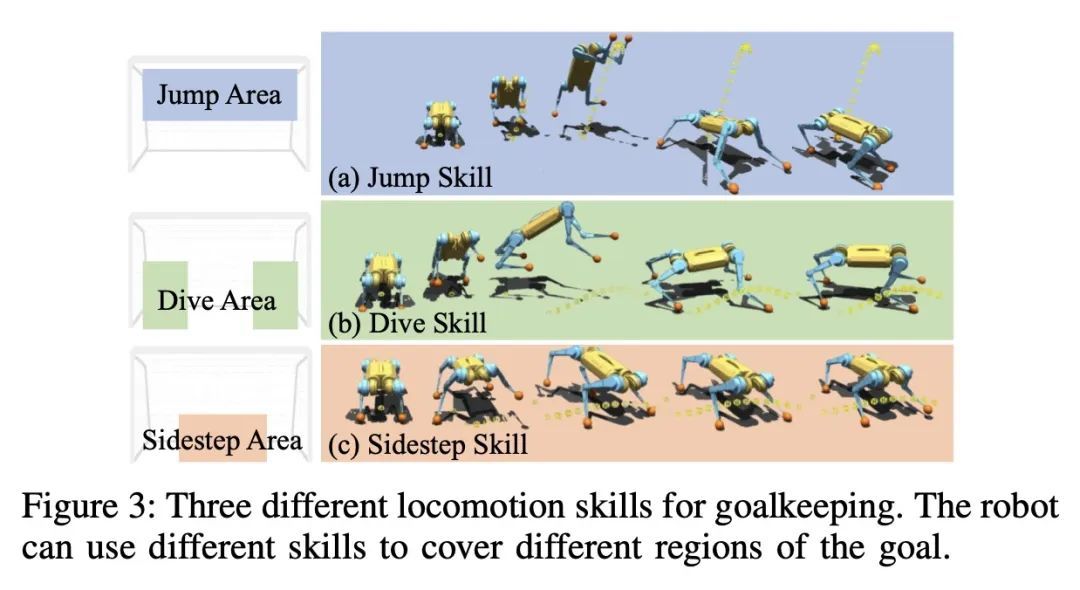
3、[RO] Creating a Dynamic Quadrupedal Robotic Goalkeeper with Reinforcement Learning
X Huang, Z Li, Y Xiang, Y Ni, Y Chi, Y Li, L Yang, X B Peng, K Sreenath
[UC Berkeley & Georgia Institute of Technology & Simon Fraser University]
基于强化学习的动态四足机器人守门员。本文提出一种强化学习(RL)框架,让四足机器人能在现实世界中执行足球守门任务。用四足机器人进行足球守门是一个具有挑战性的问题,结合了高动态运动和精确、快速的不适抓握物体(球)的操作。机器人需要在很短的时间内(通常不到一秒),利用动态运动机动性对可能飞来的球作出反应和拦截。本文建议用一个分层的无模型强化学习框架来解决该问题。该框架的第一部分包含了不同运动技能的多种控制策略,这些策略可以用来覆盖目标的不同区域。每个控制策略都能使机器人在执行一种特定的运动技能时跟踪随机参数化的末端执行器轨迹,如跳跃、俯冲和侧步。这些技能然后被框架的第二部分所利用,该部分是一个高级规划器,以确定所需的技能和末端执行器轨迹,从而拦截飞向目标不同区域的球。在Mini Cheetah四足机器人上部署了所提出的框架,并展示了该框架在现实世界中对快速移动的球进行各种敏捷拦截的有效性。
We present a reinforcement learning (RL) framework that enables quadrupedal robots to perform soccer goalkeeping tasks in the real world. Soccer goalkeeping using quadrupeds is a challenging problem, that combines highly dynamic locomotion with precise and fast non-prehensile object (ball) manipulation. The robot needs to react to and intercept a potentially flying ball using dynamic locomotion maneuvers in a very short amount of time, usually less than one second. In this paper, we propose to address this problem using a hierarchical model-free RL framework. The first component of the framework contains multiple control policies for distinct locomotion skills, which can be used to cover different regions of the goal. Each control policy enables the robot to track random parametric end-effector trajectories while performing one specific locomotion skill, such as jump, dive, and sidestep. These skills are then utilized by the second part of the framework which is a high-level planner to determine a desired skill and end-effector trajectory in order to intercept a ball flying to different regions of the goal. We deploy the proposed framework on a Mini Cheetah quadrupedal robot and demonstrate the effectiveness of our framework for various agile interceptions of a fast-moving ball in the real world.
https://arxiv.org/abs/2210.04435


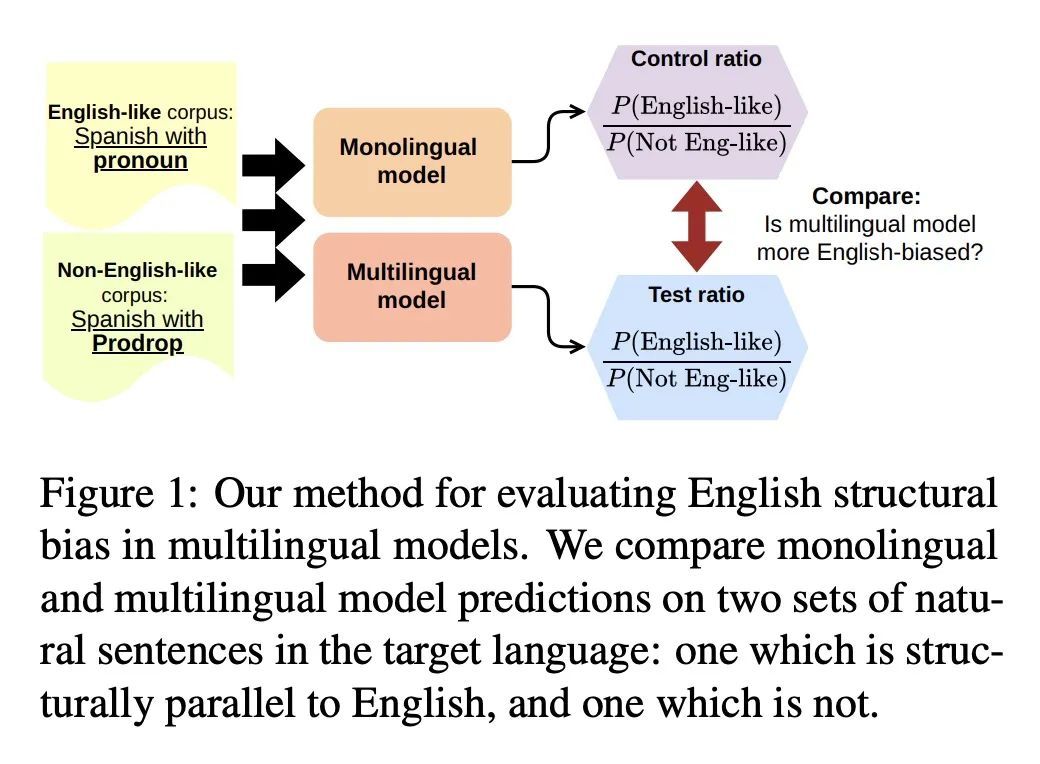
4、[CL] Multilingual BERT has an accent: Evaluating English influences on fluency in multilingual models
I Papadimitriou, K Lopez, D Jurafsky
[Stanford University]
多语言BERT的口音:英语对多语言模型流畅性的影响评估。虽然多语种语言模型可以通过利用高资源语言来提高低资源语言的NLP性能,但它们也会降低所有语言的平均性能("多语言性的诅咒")。本文展示了多语言模型的另一个问题:高资源语言的语法结构会渗入低资源语言,这种现象称为语法结构偏差。本文通过一种新方法来显示这种偏差,即比较多语言模型与单语言的西班牙语和希腊语模型的流畅性:测试它们对两种精心选择的可变语法结构(西班牙语中的optional pronoun-drop和希腊语中的optional Subject-Verb ordering)的偏好。发现与单语言对照组相比,多语言BERT偏向于类似英语的设置(明确的代词和主-动-宾排序)。通过案例研究,希望揭示出主导语言影响和偏向多语言表现的细微方式,并鼓励更多具有语言意识的流利程度评估。
While multilingual language models can improve NLP performance on low-resource languages by leveraging higher-resource languages, they also reduce average performance on all languages (the 'curse of multilinguality'). Here we show another problem with multilingual models: grammatical structures in higher-resource languages bleed into lower-resource languages, a phenomenon we call grammatical structure bias. We show this bias via a novel method for comparing the fluency of multilingual models to the fluency of monolingual Spanish and Greek models: testing their preference for two carefully-chosen variable grammatical structures (optional pronoun-drop in Spanish and optional Subject-Verb ordering in Greek). We find that multilingual BERT is biased toward the English-like setting (explicit pronouns and Subject-Verb-Object ordering) as compared to our monolingual control. With our case studies, we hope to bring to light the fine-grained ways in which dominant languages can affect and bias multilingual performance, and encourage more linguistically-aware fluency evaluation.
https://arxiv.org/abs/2210.05619



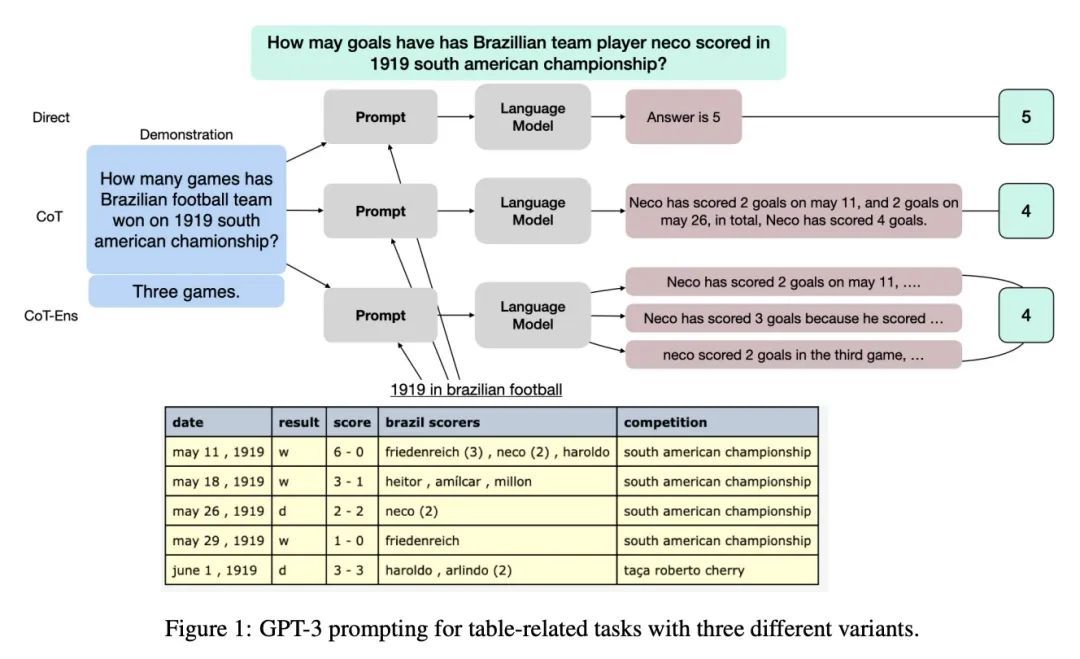
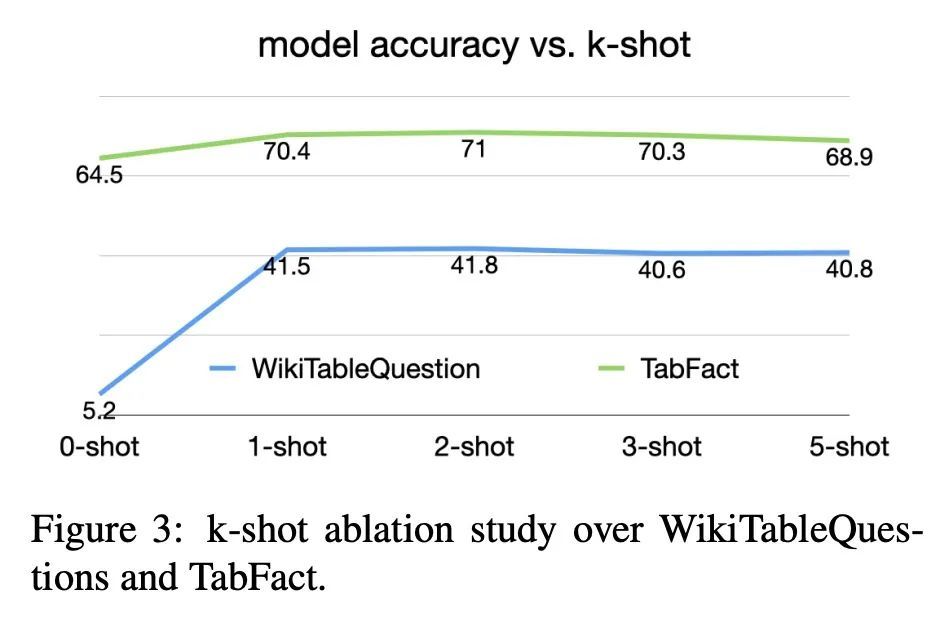
5、[CL] Large Language Models are few(1)-shot Table Reasoners
W Chen
[University of Waterloo]
大型语言模型是少(单)样本表格推理器。最近的文献表明,大型语言模型(LLM)通常是解决文本推理任务的优秀的少样本推理器。然而,大语言模型在表格推理任务上的能力还有待探索。本文旨在了解LLM在这些表格任务中的表现,以及在少样本上下文中的学习。本文在WikiTableQuestion、FetaQA、TabFact和FEVEROUS等流行的表格QA和事实验证数据集上评估了LLM,发现LLM确实有能力对表格结构进行复杂的推理。当与"思维链"提示相结合时,GPT-3能够实现非常强大的性能,只需进行单样本演示。本文进一步手工研究了从LLM引出的推理链,发现这些推理链与"ground truth"语义形式高度一致。相信本文的研究为在少样本情况下在不同的基于表格的推理任务中使用LLM提供了新的可能性。
Recent literature has shown that large language models (LLMs) are generally excellent few-shot reasoners to solve text reasoning tasks. However, the capability of LLMs on table reasoning tasks is yet to be explored. In this paper, we aim at understanding how well LLMs can perform on these table tasks with few-shot in-context learning. Specifically, we evaluate LLMs on popular table QA and fact verification datasets like WikiTableQuestion, FetaQA, TabFact, and FEVEROUS and found that LLMs are really competent at complex reasoning over table structures. When combined with `chain of thoughts' prompting, GPT-3 is able to achieve very strong performance with only a 1-shot demonstration. We further manually study the reasoning chains elicited from LLMs and found that these reasoning chains are highly consistent with the `ground truth' semantic form. We believe that our study opens new possibilities to employ LLMs on different table-based reasoning tasks under few-shot scenario.
https://arxiv.org/abs/2210.06710


另外几篇值得关注的论文:
[LG] Metadata Archaeology: Unearthing Data Subsets by Leveraging Training Dynamics
元数据考古:利用训练动态挖掘数据子集
S A Siddiqui, N Rajkumar, T Maharaj, D Krueger, S Hooker
[University of Cambridge & University of Toronto] https://arxiv.org/abs/2209.10015



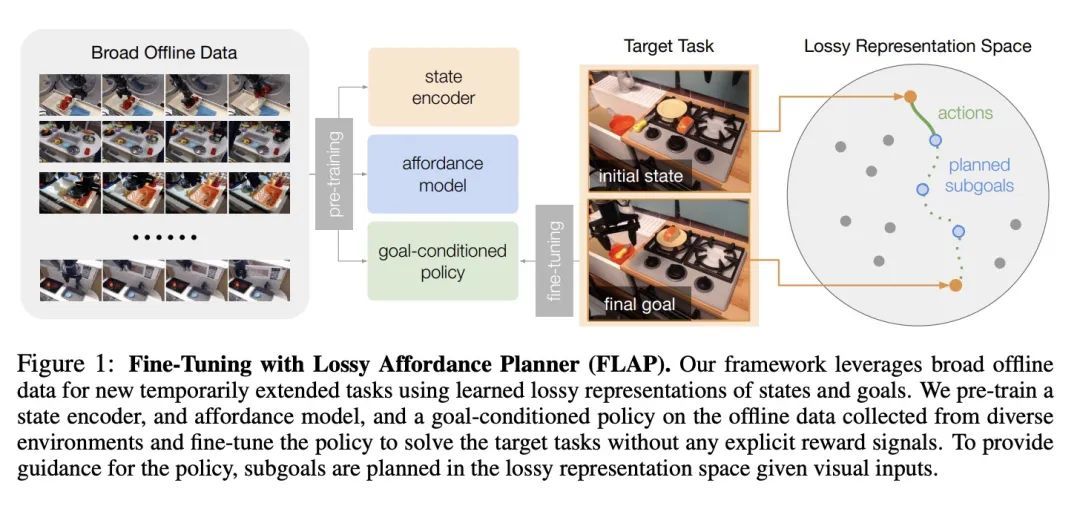
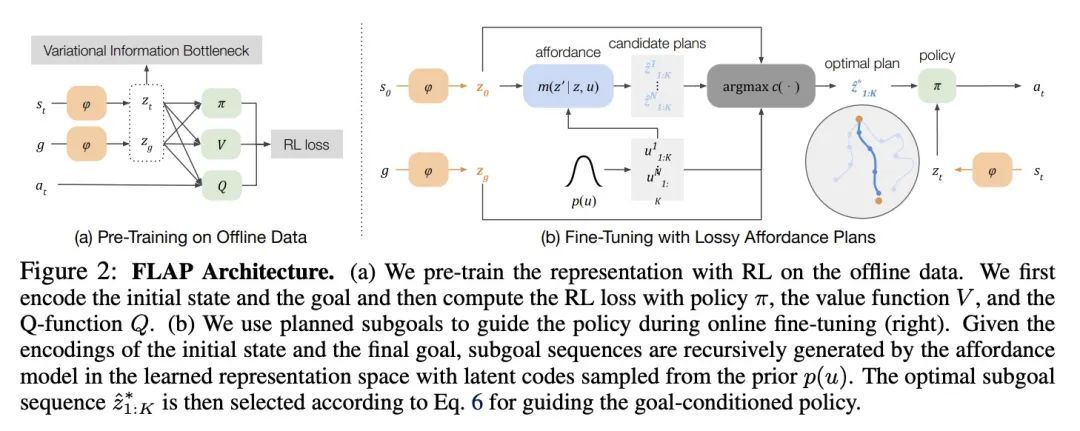
[RO] Generalization with Lossy Affordances: Leveraging Broad Offline Data for Learning Visuomotor Tasks
有损可供性泛化:利用广泛离线数据学习视觉运动任务
K Fang, P Yin, A Nair, H Walke, G Yan, S Levine
[UC Berkeley]
https://arxiv.org/abs/2210.06601

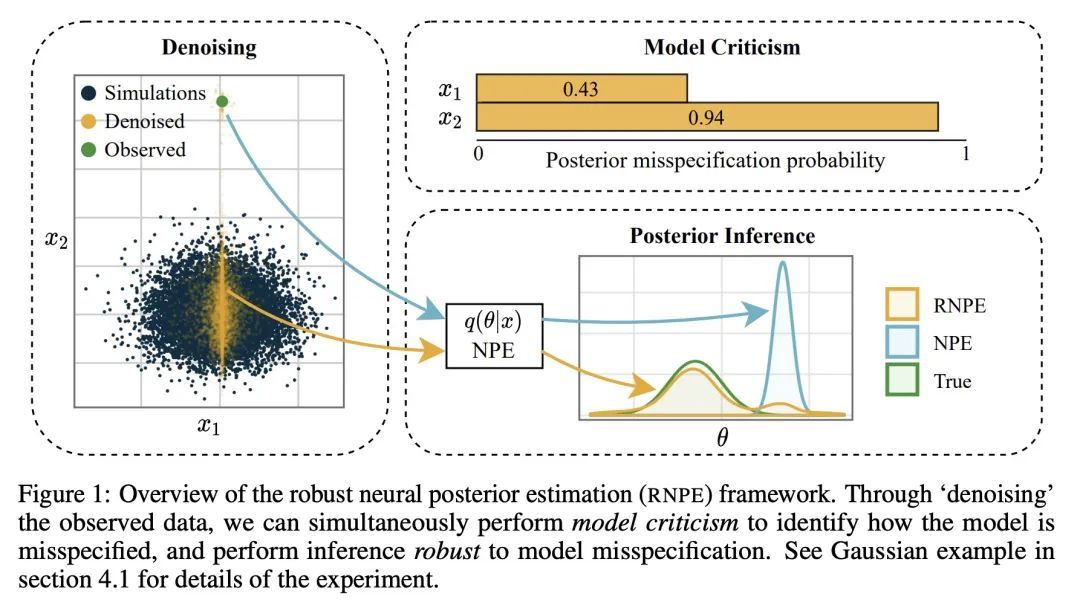
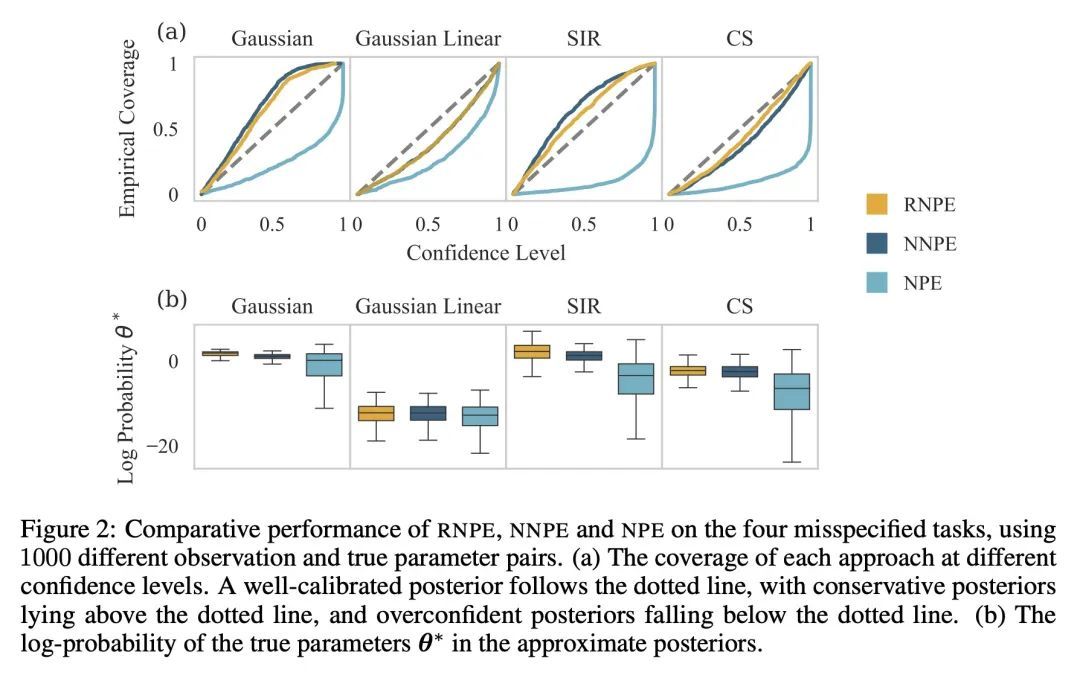
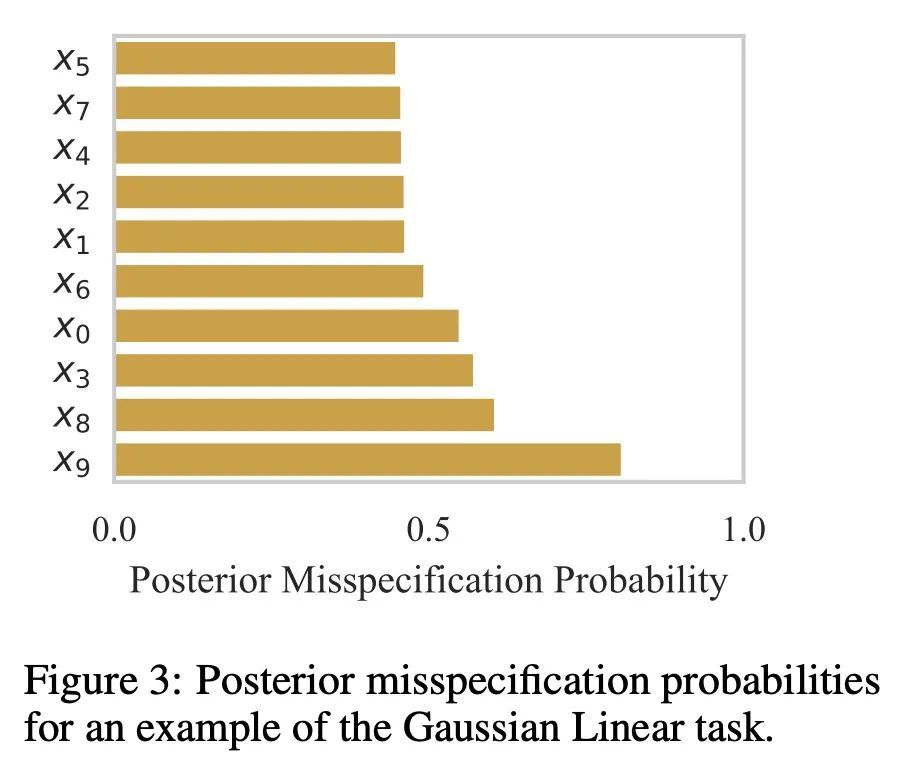
[LG] Robust Neural Posterior Estimation and Statistical Model Criticism
鲁棒神经后验估计与统计模型批判
D Ward, P Cannon, M Beaumont, M Fasiolo, S M Schmon
[Bristol University & Improbable]
https://arxiv.org/abs/2210.06564

[LG] One Transformer Can Understand Both 2D & 3D Molecular Data
基于Transformer的2D&3D分子表示
S Luo, T Chen, Y Xu, S Zheng, T Liu, L Wang, D He
[Peking University & Microsoft Research]
https://arxiv.org/abs/2210.01765

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢