

论文资源:https://ora.ox.ac.uk/objects/uuid:dea203ca-c183-4d25-9237-057abe0224dd
自然语言文本以非结构化的形式存在,它拥有大量关于我们所生活的世界的知识。随着自然语言文献数量的不断增加,分析文本并从中提取重要知识已成为一项非常耗时的工作。这导致了信息提取(IE)和自然语言处理(NLP)方法和工具的出现。IE专注于从文本中自动提取结构化语义信息。对这些清晰概念和关系的提取和附加分析有助于发现文本中包含的各种见解。本文的研究重点是开放信息提取(OIE)这一新型信息提取方法。与传统IE不同的是,OIE不局限于预先确定的一组特定于领域的关系,而是期望提取自然语言文本中发现的所有关系。已经提出了几种神经OIE算法,将OIE作为序列标记或序列生成问题来处理。序列标记方法将输入文本中的每个标记标识为属于主题、谓词或对象的,而序列生成方法在给定的输入文本中每次生成一个单词的元组。提出的方法有一定的局限性,这启发了本研究。
首先,由于OIE数据集中标签频率不等,序列标记技术往往过于强调出现频率较高的标签。第二,序列生成系统不仅容易多次产生相同的事实,而且还容易第二,序列生成系统不仅容易多次产生相同的事实,而且容易在事实中产生重复的标记。第三,尽管序列生成系统在构建隐含事实时使用词汇表中的词汇,但它们缺乏明确鼓励它们使用词汇表中的词汇或输入文本的功能。第四,通过在实际输入文本之外使用词性(PoS)和依赖标记来合并语法信息的技术没有充分利用大量的语法信息,特别是在依赖树结构中反映出来的信息。
本文旨在解决OIE早期方法的上述缺点。在这项研究中,我只研究了神经OIE方法,因为它们优于先前的基于规则的系统,并解决了基于规则的系统中的错误传播问题。在利用最先进的(SOTA)深度学习方法的同时,我给出了解决早期方法局限性的新方法。此外,我还研究了将知识图(KGs)中的事实知识合并到神经OIE模型中是否可以提高OIE方法的性能。首先,我提出了三种用于OIE方法序列标签的创新训练程序,以消除模型上OIE数据集中标签频率不均匀造成的模型偏差。其次,我避免了在事实中创建多余的标记,并通过提供方法显式地指导模型使用词汇表或输入文本中的术语,提高了模型创建隐式事实的能力。这种策略实际上大大减少了重复出现的令牌的数量。此外,当使用这种策略时,模型从原始短语中重复较少的标记,而从词汇表中引入更多的标记,这意味着具有更好的生成隐含事实的能力。第三,我提出了一种最大化依赖树拓扑提供的语法信息的方法。使用依赖树的结构,我计算了输入文本标记的语法丰富的向量表示。第四,我提出了一个用于序列标记和序列生成OIE技术的知识增强OIE框架,该框架基于在预训练语言模型(PLMs)中嵌入知识的最新成果。经过彻底的测试,我确认知识增强的OIE框架提高了OIE模型的性能。最后,为神经OIE模型训练提供了一种独特的判别策略。
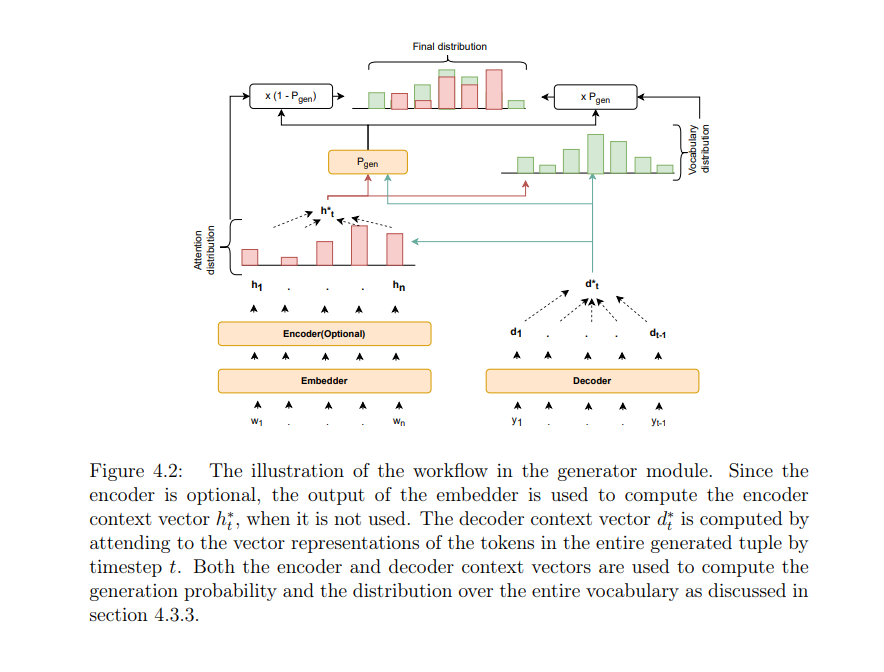
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢