
【标题】You Only Live Once: Single-Life Reinforcement Learning
【作者团队】Annie S. Chen, Archit Sharma, Sergey Levine, Chelsea Finn
【发表日期】2022.10.17
【论文链接】https://arxiv.org/pdf/2210.08863.pdf
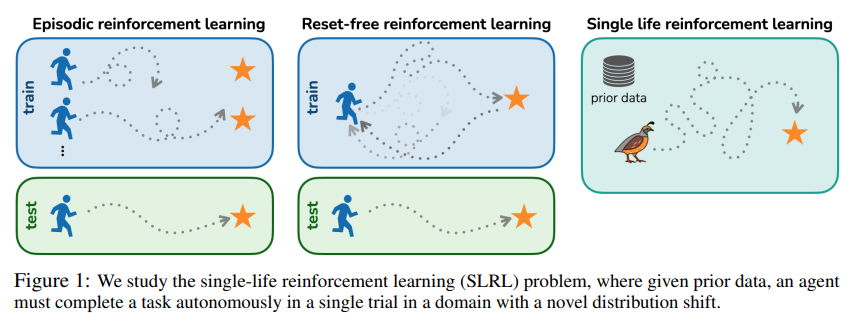
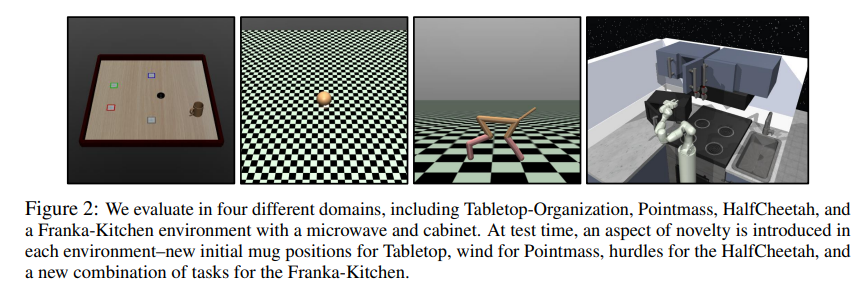
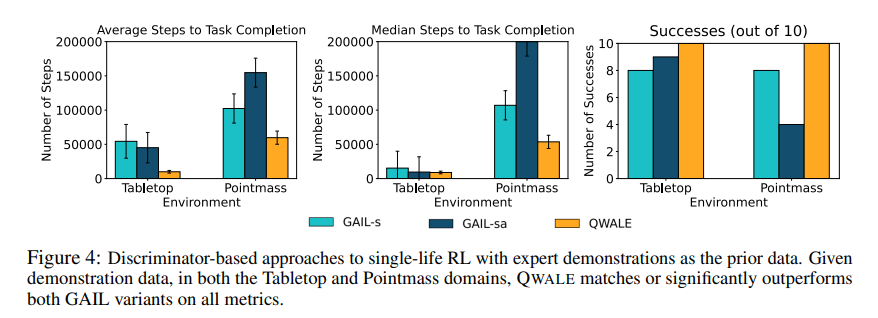
【推荐理由】强化学习算法通常设计用于学习一种性能策略,该策略可以重复、自主地完成任务,通常从零开始。然而,在许多实际情况中,目标可能不是学习可以重复执行任务的策略,而是简单地在一次试验中成功执行一项新任务。例如,想象一个救灾机器人的任务是从倒塌的建筑物中取回物品,在那里它无法得到人类的直接监督。它必须在一次测试时间内取回这个物体,并且必须在处理未知障碍物时取回,尽管它可能会利用灾难前对建筑物的了解。本文将这种问题设置形式化,并称之为单生命强化学习(SLRL。SLRL提供了一个自然的环境来研究自主适应陌生情况的挑战,研究发现,为标准情景强化学习设计的算法通常很难从这种环境下的分布外状态中恢复。基于这一观察结果,进一步提出了Q加权对抗学习(QWALE)算法,它采用了一种分布匹配策略,在新情况下利用代理的先前经验作为指导。通过对几个单寿命连续控制问题的实验表明,基于本研究的分布匹配公式的方法的成功率提高了20-60%,因为它们可以更快地从新状态中恢复。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢