【标题】Teacher Forcing Recovers Reward Functions for Text Generation
【作者团队】Yongchang Hao, Yuxin Liu, Lili Mou
【发表日期】2022.10.17
【论文链接】https://arxiv.org/pdf/2210.08708.pdf
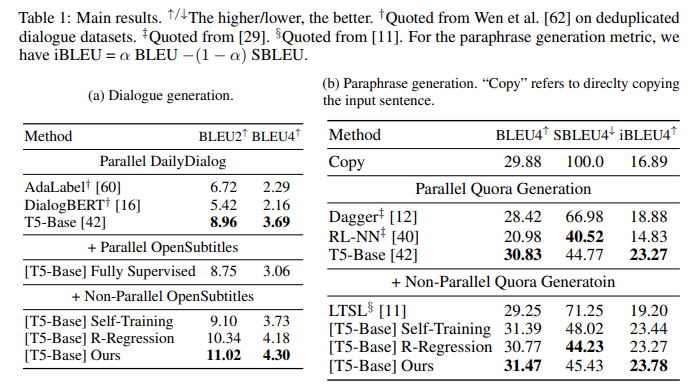
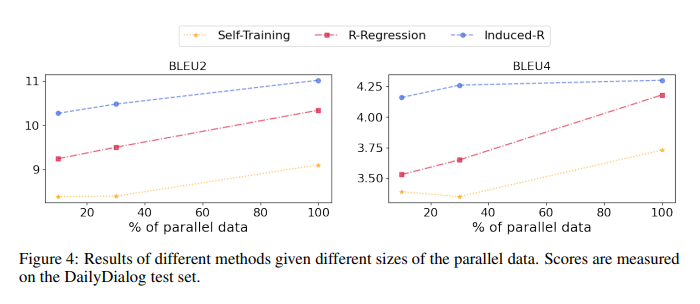
【推荐理由】强化学习(RL)已广泛用于文本生成,以缓解暴露偏差问题或利用非并行数据集。奖励功能对RL培训的成功起着重要作用。然而,先前的奖励功能通常是特定于任务且稀疏的,限制了RL的使用。本研究提出了一种任务无关的方法,该方法直接从一个经过教师强制训练的模型中推导出一个逐步的奖励函数。此外,还提出了一个简单的修改,通过诱导奖赏函数来稳定非平行数据集上的RL训练。实验结果表明,在多个文本生成任务中,该研究方法优于自我训练和奖赏回归方法,验证了奖赏函数的有效性。

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢