
【标题】RORL: Robust Offline Reinforcement Learning via Conservative Smoothing
【作者团队】Rui Yang, Chenjia Bai, Xiaoteng Ma, Zhaoran Wang, Chongjie Zhang, Lei Han
【发表日期】2022.9.26
【论文链接】https://arxiv.org/pdf/2206.02829v2.pdf
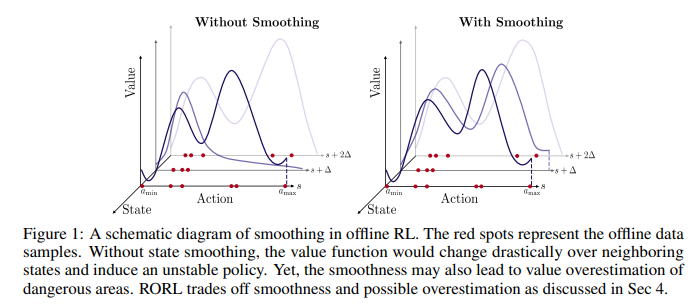
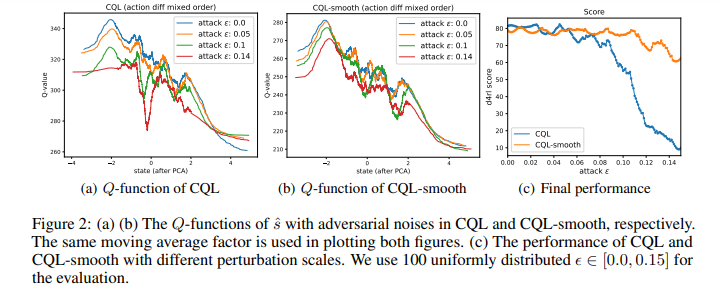
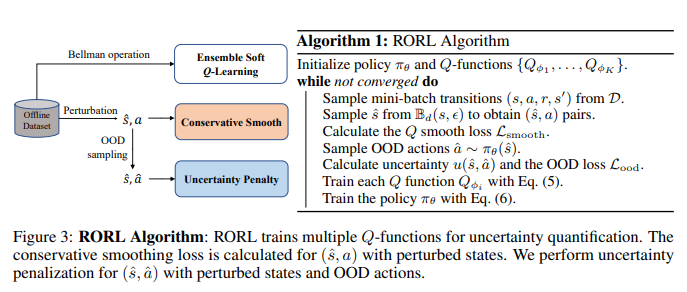
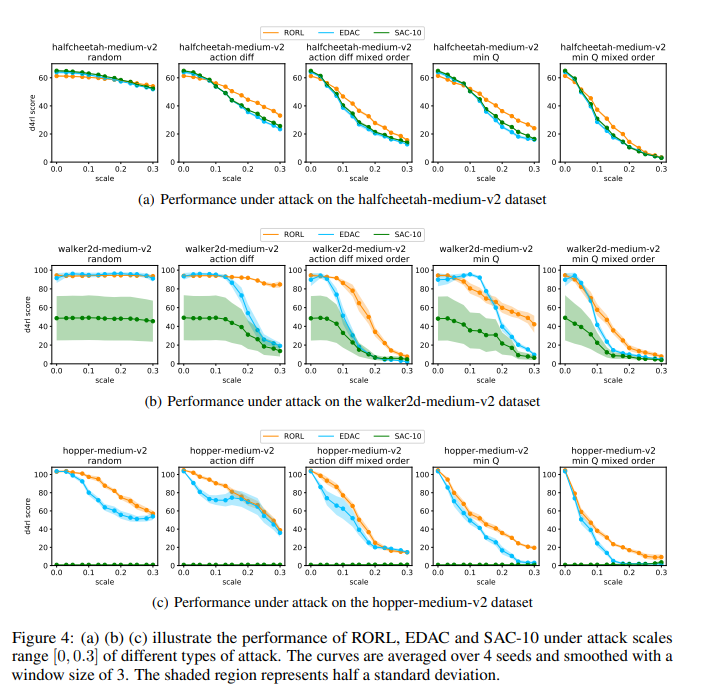
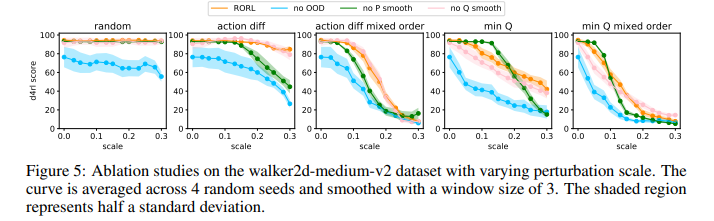
【推荐理由】离线强化学习(RL)为利用大量离线数据进行复杂决策任务提供了一个很有前景的方向。由于分布移位问题,当前的离线RL算法在值估计和动作选择方面通常被设计为保守的。然而,在现实条件下,如传感器错误和对抗性攻击,当遇到观测偏差时,这种保守主义会削弱所学策略的鲁棒性。为了权衡稳健性和保守性,本文提出了鲁棒离线强化学习(RORL)和新的保守性平滑技术。在RORL中,引入了对数据集附近状态的策略和值函数的正则化,以及对这些OOD状态的额外保守值估计。理论上,研究表明RORL比线性MDP中最近的理论结果具有更紧的次优界。并证明RORL可以在一般离线RL基准上实现最先进的性能,并且对对抗性观测扰动具有相当大的鲁棒性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢