

本文简要介绍SIGGRAPH 2022录用论文“Learning From Documents in the Wild to Improve Document Unwarping”的主要工作。该论文提出一个文档图像校正方法PaperEdge,训练过程能同时利用合成数据以及真实数据,此外还提出了一个更加鲁邦的评价指标Aligned Distortion(AD)以及一个带有文档区域Mask标注的真实场景下的文档图像数据集。

图1 本文方法矫正效果. 其中第一行为输入,第二行为本文方法输出结果.
一、研究背景
文档图像校正在文档数字化以及文档分析中都十分重要。现有的SOTA方案基本都是基于合成数据训练的深度学习方法,导致模型在真实数据上测试时的泛化能力不足,影响矫正性能。因此本文提出在模型训练阶段引入真实数据,以此提升模型的矫正性能。为了用真实数据进行训练,本文提出了DIW(Document-in-the-Wild)数据集,包含5000张带有文档区域Mask标注的真实场景文档图像。本文提出的PaperEdge方法可以基于DIW数据集进行弱监督的训练。此外,考虑到现有的评价指标存在对微小变化过于敏感以及在无纹理区域存在较大误差等问题,本文提出一个更加鲁邦的评价指标AD。
二、方法原理简述

图2 整体流程图
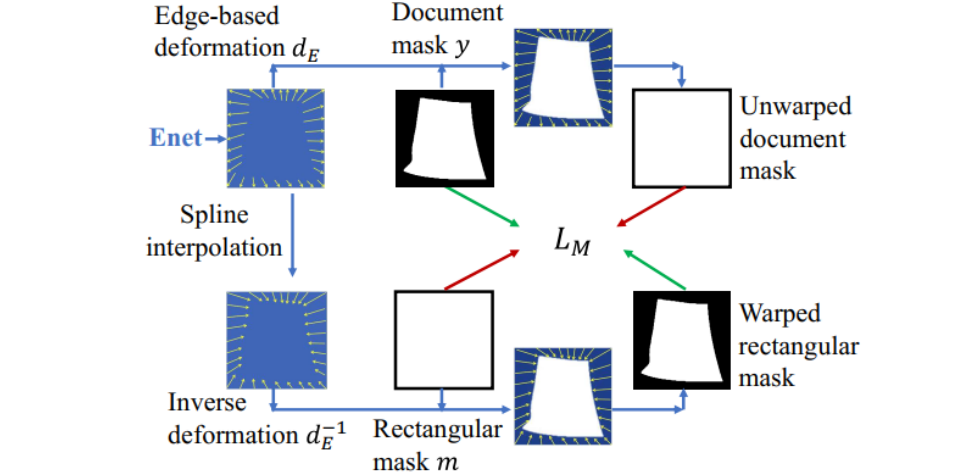
图3 Enet 的弱监督方式

图4 Tnet的自监督方式
图2是本文整体流程图:包含两个子网络对输入的文档图像依次处理。第一个子网络Enet根据文档的边界信息进行矫正,输出一个形变场(Warping Field)对文档进行全局的粗略矫正,将文档图像拉平成四边形;第二个子网络Tnet,输出另一个形变场对Enet的矫正结果进行局部的细粒度矫正。
- lLearning From Documents in the Wild to Improve Document Unwarping论文地址:
https://dl.acm.org/doi/abs/10.1145/3528233.3530756 - lLearning From Documents in the Wild to Improve Document Unwarping 项目地址:
https://github.com/cvlab-stonybrook/PaperEdge - lDIW数据集下载地址:
https://drive.google.com/file/d/1qAmLurt6bK0ro8PnRz6rBgVs1rfrsdKi/view?usp=sharing
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢